 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpreting CLIP with Sparse Linear Concept Embeddings (SpLiCE)
Paper and Code
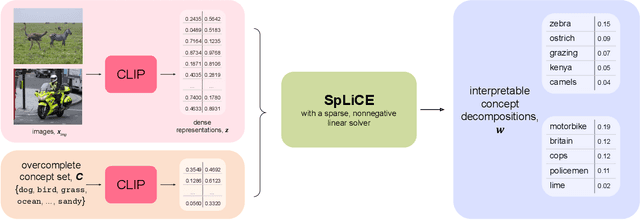
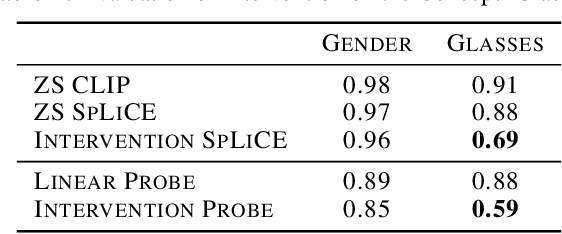

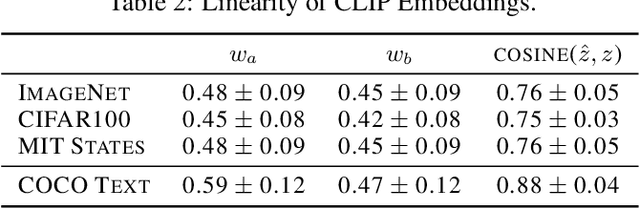
CLIP embeddings have demonstrated remarkable performance across a wide range of computer vision tasks. However, these high-dimensional, dense vector representations are not easily interpretable, restricting their usefulness in downstream applications that require transparency. In this work, we empirically show that CLIP's latent space is highly structured, and consequently that CLIP representations can be decomposed into their underlying semantic components. We leverage this understanding to propose a novel method, Sparse Linear Concept Embeddings (SpLiCE), for transforming CLIP representations into sparse linear combinations of human-interpretable concepts. Distinct from previous work, SpLiCE does not require concept labels and can be applied post hoc. Through extensive experimentation with multiple real-world datasets, we validate that the representations output by SpLiCE can explain and even replace traditional dense CLIP representations, maintaining equivalent downstream performance while significantly improving their interpretability. We also demonstrate several use cases of SpLiCE representations including detecting spurious correlations, model editing, and quantifying semantic shifts in datasets.