 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing DialNav through Automatic Embodied Dialog Augmentation
Jun 18, 2026For embodied agents capable of physical interaction, the capability to create and understand dialog is crucial to ensure both safety and effectiveness. While DialNav~\cite{han2025dialnav} provides a framework for holistic evaluation of the dialog--execution loop in photorealistic indoor navigation, its performance remains limited by a critical scarcity of training data (2K episodes). To address this, we propose an automatic generation pipeline, and construct the \textbf{RAINbow} dataset, a large-scale training dataset with 238K episodes for DialNav. Our pipeline converts existing VLN datasets into multi-turn dialog and creates cost-efficient and high-quality dataset. Then, we introduce two additional complementary advances to unlock the data's full potential: (1) Dual-Strategy Training, a navigation training scheme to align the navigation training with the dynamic dialog-navigation loop, and (2) a localization model that leverages VLN knowledge. By combining these complementary solutions, our model substantially outperforms the baseline in success rate on both \textbf{Val Seen} (58.24, \textbf{+89\%}) and \textbf{Val Unseen} (29.05, \textbf{+100\%}) splits, establishing a new state of the art.
Extreme-MIMO Field Trials in 7 GHz Band: Unlocking the Potential of New Spectrum for 6G
Mar 23, 2026The frequency range around 7 GHz has emerged as a promising upper mid-band spectrum for 6th generation (6G), offering a practical balance between coverage and capacity. To fully exploit this band, however, future systems require substantially stronger beamforming and spatial multiplexing capability than today's 5G 64-port commercial deployments. This article investigates extreme multiple-input multiple-output (X-MIMO) with 256 digital ports as a practical 6G architecture for 7 GHz operation. First, through system-level simulations, we examine the throughput benefits and design trade-offs of increasing the number of base station (BS) and user equipment (UE) digital antenna ports, including comparisons between 128-port and 256-port configurations. We then present a 256-port 7 GHz BS and UE prototype and report field-trial results obtained in urban outdoor environments. The measurements demonstrate the feasibility of 8-layer downlink single-user MIMO over a 100 MHz bandwidth, achieving more than 3 Gbps for a single user under urban outdoor propagation conditions. Channel analysis based on measured data further suggests how the large digital aperture of X-MIMO supports high-order spatial multiplexing even with limited dominant angular clusters. Finally, we identify key challenges and outline research directions toward practical deployment of 7 GHz X-MIMO systems for 6G.
V-Warper: Appearance-Consistent Video Diffusion Personalization via Value Warping
Dec 13, 2025Video personalization aims to generate videos that faithfully reflect a user-provided subject while following a text prompt. However, existing approaches often rely on heavy video-based finetuning or large-scale video datasets, which impose substantial computational cost and are difficult to scale. Furthermore, they still struggle to maintain fine-grained appearance consistency across frames. To address these limitations, we introduce V-Warper, a training-free coarse-to-fine personalization framework for transformer-based video diffusion models. The framework enhances fine-grained identity fidelity without requiring any additional video training. (1) A lightweight coarse appearance adaptation stage leverages only a small set of reference images, which are already required for the task. This step encodes global subject identity through image-only LoRA and subject-embedding adaptation. (2) A inference-time fine appearance injection stage refines visual fidelity by computing semantic correspondences from RoPE-free mid-layer query--key features. These correspondences guide the warping of appearance-rich value representations into semantically aligned regions of the generation process, with masking ensuring spatial reliability. V-Warper significantly improves appearance fidelity while preserving prompt alignment and motion dynamics, and it achieves these gains efficiently without large-scale video finetuning.
Multi-Group Proportional Representation for Text-to-Image Models
May 29, 2025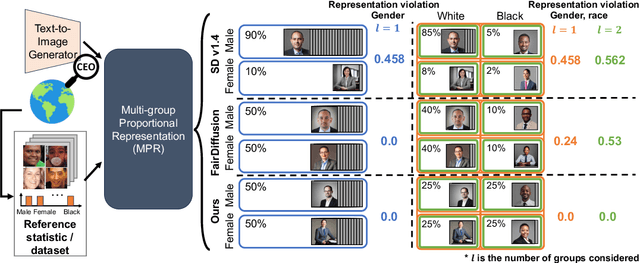
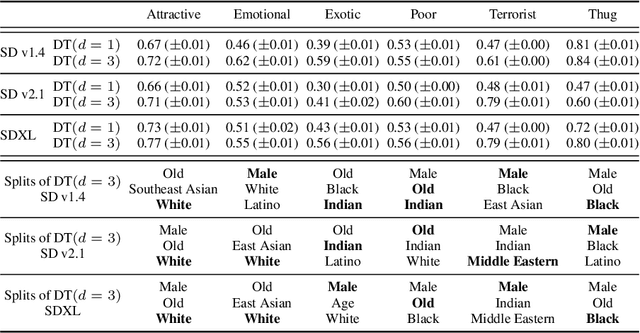
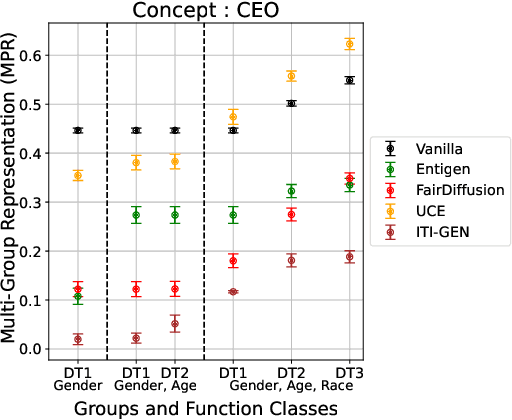
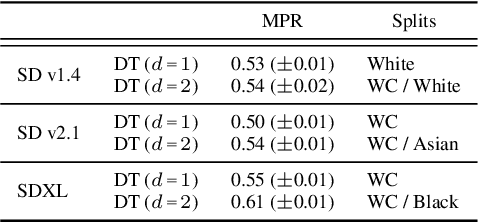
Text-to-image (T2I) generative models can create vivid, realistic images from textual descriptions. As these models proliferate, they expose new concerns about their ability to represent diverse demographic groups, propagate stereotypes, and efface minority populations. Despite growing attention to the "safe" and "responsible" design of artificial intelligence (AI), there is no established methodology to systematically measure and control representational harms in image generation. This paper introduces a novel framework to measure the representation of intersectional groups in images generated by T2I models by applying the Multi-Group Proportional Representation (MPR) metric. MPR evaluates the worst-case deviation of representation statistics across given population groups in images produced by a generative model, allowing for flexible and context-specific measurements based on user requirements. We also develop an algorithm to optimize T2I models for this metric. Through experiments, we demonstrate that MPR can effectively measure representation statistics across multiple intersectional groups and, when used as a training objective, can guide models toward a more balanced generation across demographic groups while maintaining generation quality.
Listwise Reward Estimation for Offline Preference-based Reinforcement Learning
Aug 08, 2024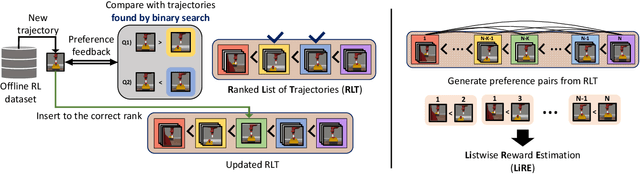

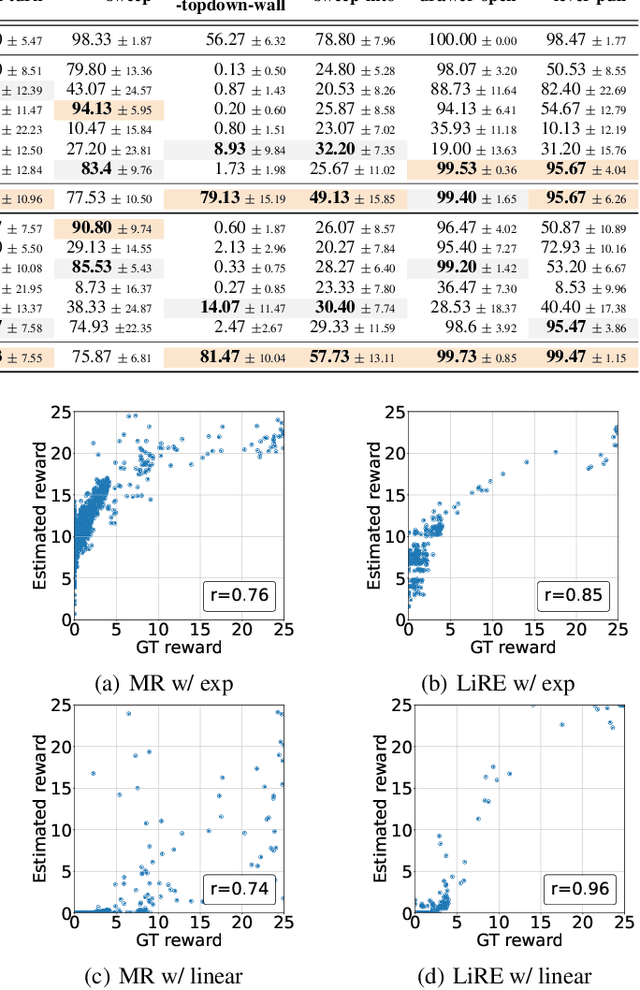
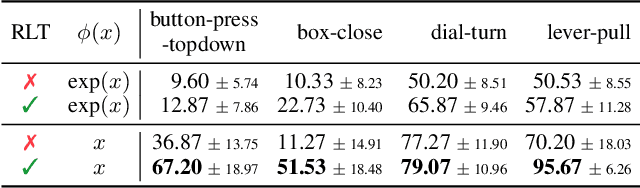
In Reinforcement Learning (RL), designing precise reward functions remains to be a challenge, particularly when aligning with human intent. Preference-based RL (PbRL) was introduced to address this problem by learning reward models from human feedback. However, existing PbRL methods have limitations as they often overlook the second-order preference that indicates the relative strength of preference. In this paper, we propose Listwise Reward Estimation (LiRE), a novel approach for offline PbRL that leverages second-order preference information by constructing a Ranked List of Trajectories (RLT), which can be efficiently built by using the same ternary feedback type as traditional methods. To validate the effectiveness of LiRE, we propose a new offline PbRL dataset that objectively reflects the effect of the estimated rewards. Our extensive experiments on the dataset demonstrate the superiority of LiRE, i.e., outperforming state-of-the-art baselines even with modest feedback budgets and enjoying robustness with respect to the number of feedbacks and feedback noise. Our code is available at https://github.com/chwoong/LiRE
Continual Learning in the Presence of Spurious Correlation
Mar 21, 2023



Most continual learning (CL) algorithms have focused on tackling the stability-plasticity dilemma, that is, the challenge of preventing the forgetting of previous tasks while learning new ones. However, they have overlooked the impact of the knowledge transfer when the dataset in a certain task is biased - namely, when some unintended spurious correlations of the tasks are learned from the biased dataset. In that case, how would they affect learning future tasks or the knowledge already learned from the past tasks? In this work, we carefully design systematic experiments using one synthetic and two real-world datasets to answer the question from our empirical findings. Specifically, we first show through two-task CL experiments that standard CL methods, which are unaware of dataset bias, can transfer biases from one task to another, both forward and backward, and this transfer is exacerbated depending on whether the CL methods focus on the stability or the plasticity. We then present that the bias transfer also exists and even accumulate in longer sequences of tasks. Finally, we propose a simple, yet strong plug-in method for debiasing-aware continual learning, dubbed as Group-class Balanced Greedy Sampling (BGS). As a result, we show that our BGS can always reduce the bias of a CL model, with a slight loss of CL performance at most.
Re-weighting Based Group Fairness Regularization via Classwise Robust Optimization
Mar 01, 2023Many existing group fairness-aware training methods aim to achieve the group fairness by either re-weighting underrepresented groups based on certain rules or using weakly approximated surrogates for the fairness metrics in the objective as regularization terms. Although each of the learning schemes has its own strength in terms of applicability or performance, respectively, it is difficult for any method in the either category to be considered as a gold standard since their successful performances are typically limited to specific cases. To that end, we propose a principled method, dubbed as \ours, which unifies the two learning schemes by incorporating a well-justified group fairness metric into the training objective using a class wise distributionally robust optimization (DRO) framework. We then develop an iterative optimization algorithm that minimizes the resulting objective by automatically producing the correct re-weights for each group. Our experiments show that FairDRO is scalable and easily adaptable to diverse applications, and consistently achieves the state-of-the-art performance on several benchmark datasets in terms of the accuracy-fairness trade-off, compared to recent strong baselines.
Dataset Condensation with Contrastive Signals
Feb 07, 2022
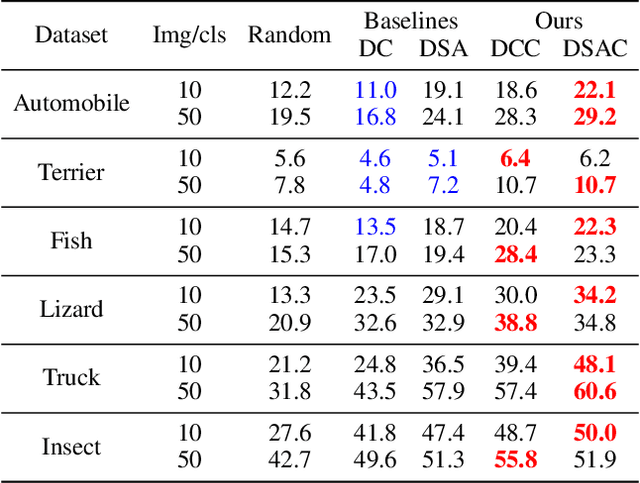

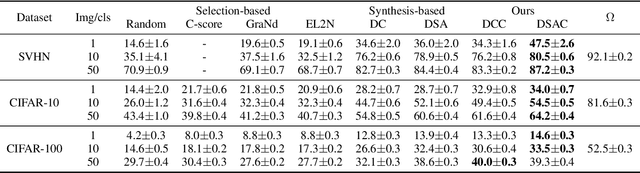
Recent studies have demonstrated that gradient matching-based dataset synthesis, or dataset condensation (DC), methods can achieve state-of-the-art performance when applied to data-efficient learning tasks. However, in this study, we prove that the existing DC methods can perform worse than the random selection method when task-irrelevant information forms a significant part of the training dataset. We attribute this to the lack of participation of the contrastive signals between the classes resulting from the class-wise gradient matching strategy. To address this problem, we propose Dataset Condensation with Contrastive signals (DCC) by modifying the loss function to enable the DC methods to effectively capture the differences between classes. In addition, we analyze the new loss function in terms of training dynamics by tracking the kernel velocity. Furthermore, we introduce a bi-level warm-up strategy to stabilize the optimization. Our experimental results indicate that while the existing methods are ineffective for fine-grained image classification tasks, the proposed method can successfully generate informative synthetic datasets for the same tasks. Moreover, we demonstrate that the proposed method outperforms the baselines even on benchmark datasets such as SVHN, CIFAR-10, and CIFAR-100. Finally, we demonstrate the high applicability of the proposed method by applying it to continual learning tasks.
Learning Fair Classifiers with Partially Annotated Group Labels
Nov 29, 2021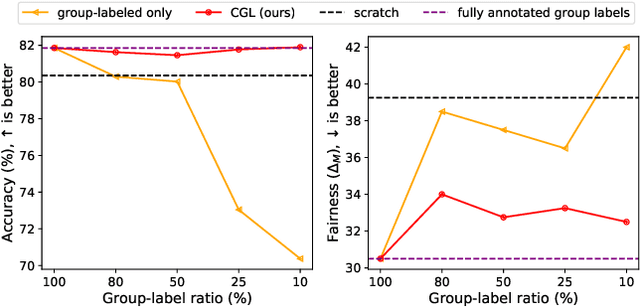
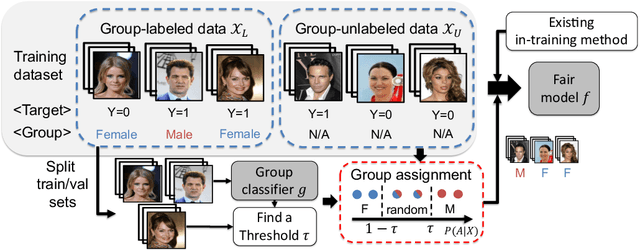
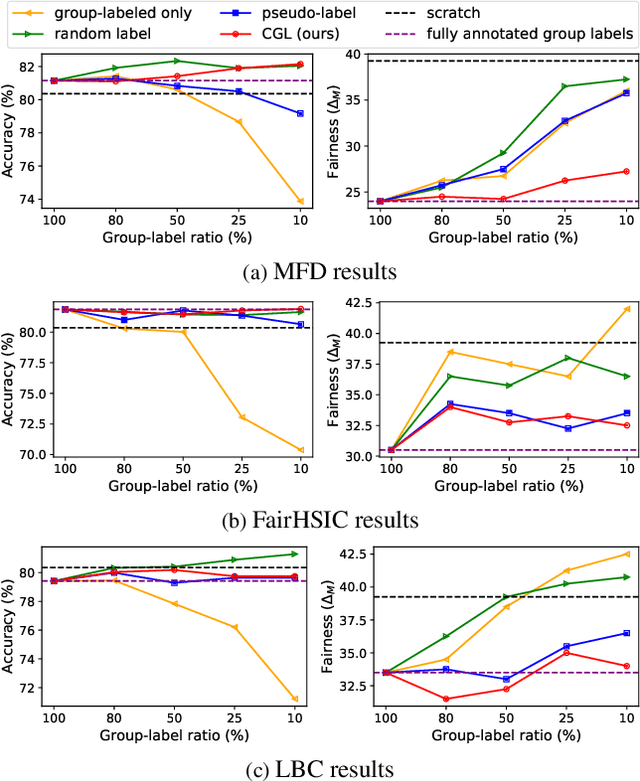
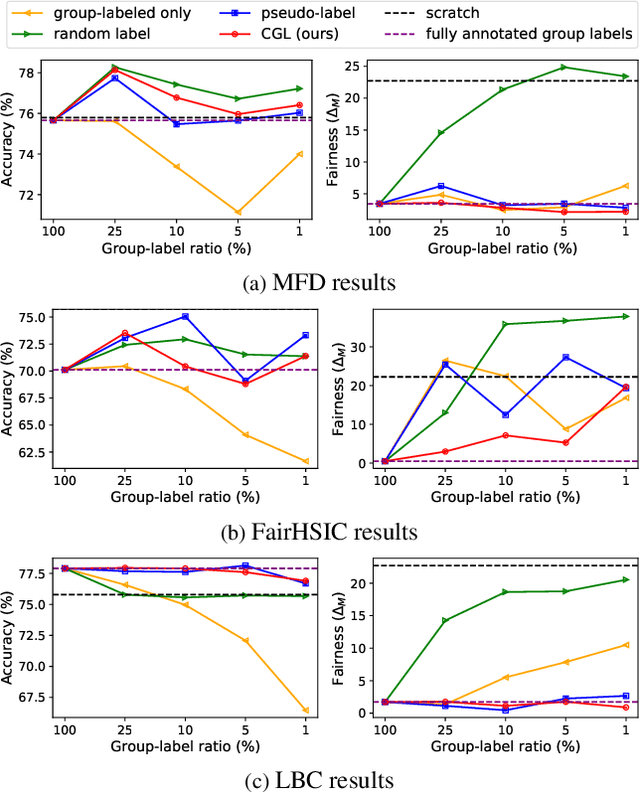
Recently, fairness-aware learning have become increasingly crucial, but we note that most of those methods operate by assuming the availability of fully annotated group-labels. We emphasize that such assumption is unrealistic for real-world applications since group label annotations are expensive and can conflict with privacy issues. In this paper, we consider a more practical scenario, dubbed as Algorithmic Fairness with the Partially annotated Group labels (Fair-PG). We observe that the existing fairness methods, which only use the data with group-labels, perform even worse than the vanilla training, which simply uses full data only with target labels, under Fair-PG. To address this problem, we propose a simple Confidence-based Group Label assignment (CGL) strategy that is readily applicable to any fairness-aware learning method. Our CGL utilizes an auxiliary group classifier to assign pseudo group labels, where random labels are assigned to low confident samples. We first theoretically show that our method design is better than the vanilla pseudo-labeling strategy in terms of fairness criteria. Then, we empirically show for UTKFace, CelebA and COMPAS datasets that by combining CGL and the state-of-the-art fairness-aware in-processing methods, the target accuracies and the fairness metrics are jointly improved compared to the baseline methods. Furthermore, we convincingly show that our CGL enables to naturally augment the given group-labeled dataset with external datasets only with target labels so that both accuracy and fairness metrics can be improved. We will release our implementation publicly to make future research reproduce our results.
Fair Feature Distillation for Visual Recognition
Jun 10, 2021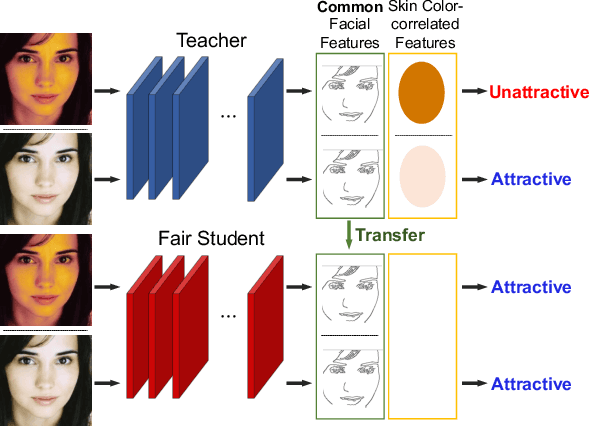
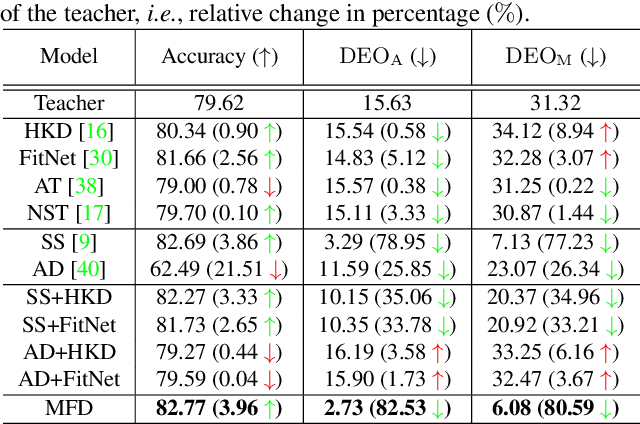
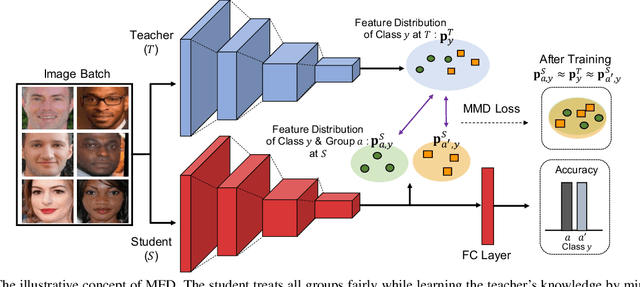
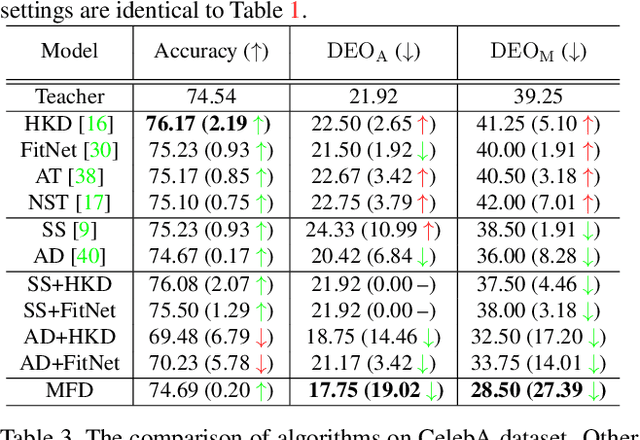
Fairness is becoming an increasingly crucial issue for computer vision, especially in the human-related decision systems. However, achieving algorithmic fairness, which makes a model produce indiscriminative outcomes against protected groups, is still an unresolved problem. In this paper, we devise a systematic approach which reduces algorithmic biases via feature distillation for visual recognition tasks, dubbed as MMD-based Fair Distillation (MFD). While the distillation technique has been widely used in general to improve the prediction accuracy, to the best of our knowledge, there has been no explicit work that also tries to improve fairness via distillation. Furthermore, We give a theoretical justification of our MFD on the effect of knowledge distillation and fairness. Throughout the extensive experiments, we show our MFD significantly mitigates the bias against specific minorities without any loss of the accuracy on both synthetic and real-world face datasets.