 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDataset Condensation with Contrastive Signals
Paper and Code

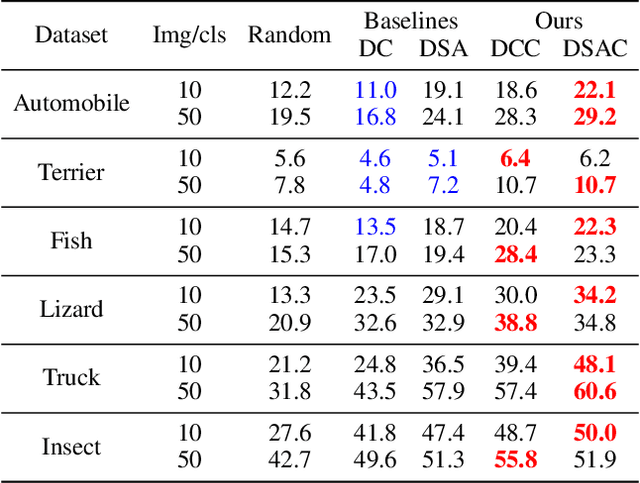

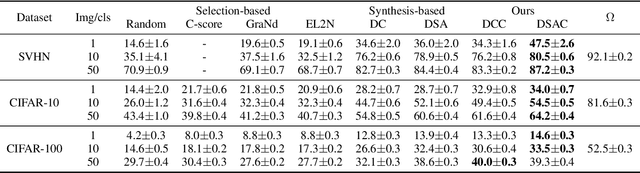
Recent studies have demonstrated that gradient matching-based dataset synthesis, or dataset condensation (DC), methods can achieve state-of-the-art performance when applied to data-efficient learning tasks. However, in this study, we prove that the existing DC methods can perform worse than the random selection method when task-irrelevant information forms a significant part of the training dataset. We attribute this to the lack of participation of the contrastive signals between the classes resulting from the class-wise gradient matching strategy. To address this problem, we propose Dataset Condensation with Contrastive signals (DCC) by modifying the loss function to enable the DC methods to effectively capture the differences between classes. In addition, we analyze the new loss function in terms of training dynamics by tracking the kernel velocity. Furthermore, we introduce a bi-level warm-up strategy to stabilize the optimization. Our experimental results indicate that while the existing methods are ineffective for fine-grained image classification tasks, the proposed method can successfully generate informative synthetic datasets for the same tasks. Moreover, we demonstrate that the proposed method outperforms the baselines even on benchmark datasets such as SVHN, CIFAR-10, and CIFAR-100. Finally, we demonstrate the high applicability of the proposed method by applying it to continual learning tasks.