 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRe-weighting Based Group Fairness Regularization via Classwise Robust Optimization
Mar 01, 2023Many existing group fairness-aware training methods aim to achieve the group fairness by either re-weighting underrepresented groups based on certain rules or using weakly approximated surrogates for the fairness metrics in the objective as regularization terms. Although each of the learning schemes has its own strength in terms of applicability or performance, respectively, it is difficult for any method in the either category to be considered as a gold standard since their successful performances are typically limited to specific cases. To that end, we propose a principled method, dubbed as \ours, which unifies the two learning schemes by incorporating a well-justified group fairness metric into the training objective using a class wise distributionally robust optimization (DRO) framework. We then develop an iterative optimization algorithm that minimizes the resulting objective by automatically producing the correct re-weights for each group. Our experiments show that FairDRO is scalable and easily adaptable to diverse applications, and consistently achieves the state-of-the-art performance on several benchmark datasets in terms of the accuracy-fairness trade-off, compared to recent strong baselines.
Fair Feature Distillation for Visual Recognition
Jun 10, 2021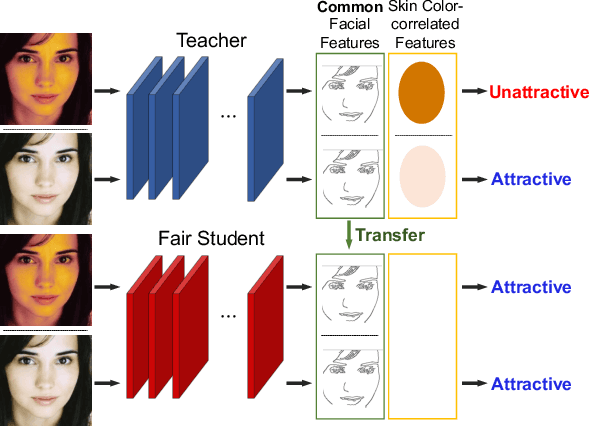
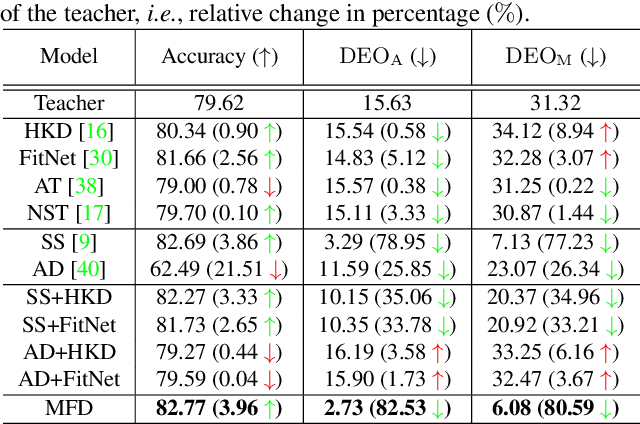
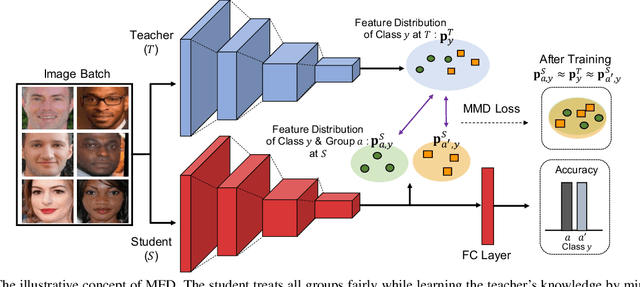
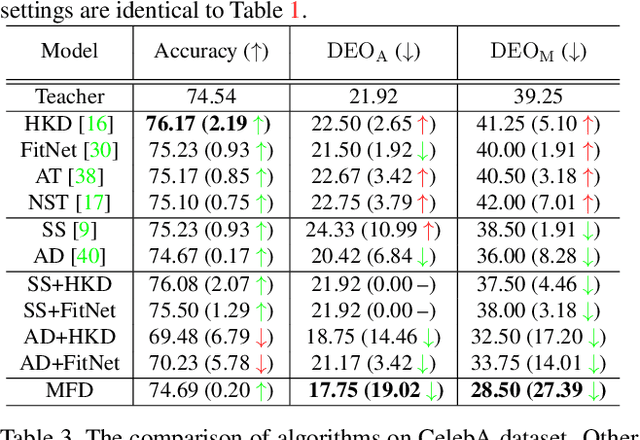
Fairness is becoming an increasingly crucial issue for computer vision, especially in the human-related decision systems. However, achieving algorithmic fairness, which makes a model produce indiscriminative outcomes against protected groups, is still an unresolved problem. In this paper, we devise a systematic approach which reduces algorithmic biases via feature distillation for visual recognition tasks, dubbed as MMD-based Fair Distillation (MFD). While the distillation technique has been widely used in general to improve the prediction accuracy, to the best of our knowledge, there has been no explicit work that also tries to improve fairness via distillation. Furthermore, We give a theoretical justification of our MFD on the effect of knowledge distillation and fairness. Throughout the extensive experiments, we show our MFD significantly mitigates the bias against specific minorities without any loss of the accuracy on both synthetic and real-world face datasets.
GAN2GAN: Generative Noise Learning for Blind Image Denoising with Single Noisy Images
May 25, 2019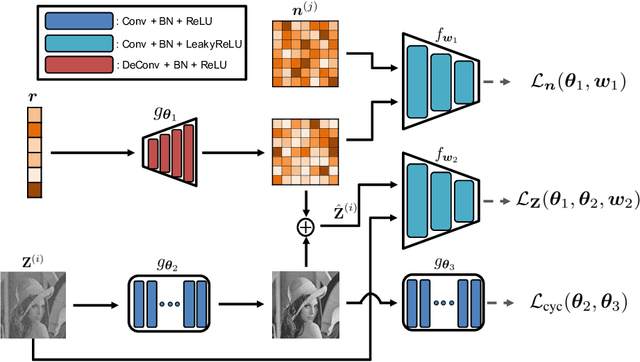

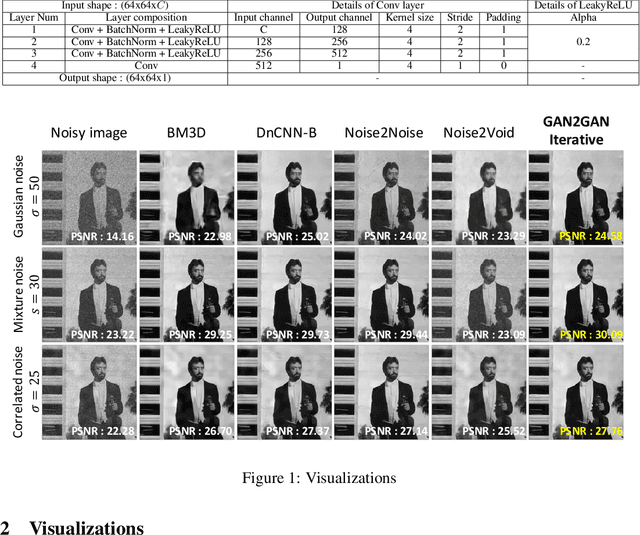
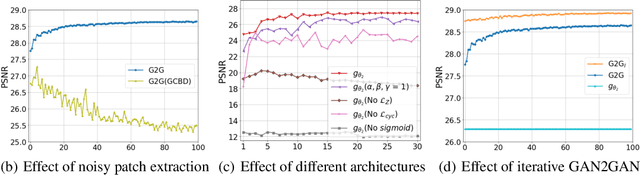
We tackle a challenging blind image denoising problem, in which only single noisy images are available for training a denoiser and no information about noise is known, except for it being zero-mean, additive, and independent of the clean image. In such a setting, which often occurs in practice, it is not possible to train a denoiser with the standard discriminative training or with the recently developed Noise2Noise (N2N) training; the former requires the underlying clean image for the given noisy image, and the latter requires two independently realized noisy image pair for a clean image. To that end, we propose GAN2GAN (Generated-Artificial-Noise to Generated-Artificial-Noise) method that can first learn to generate synthetic noisy image pairs that simulate independent realizations of the noise in the given images, then carry out the N2N training of a denoiser with those synthetically generated noisy image pairs. Our method consists of three parts: extracting smooth noisy patches to learn the noise distribution in the given images, training a generative model to synthesize the noisy image pairs, and devising an iterative N2N training of a denoiser. In results, we show the denoiser trained with our GAN2GAN, solely based on single noisy images, achieves an impressive denoising performance, almost approaching the performance of the standard discriminatively-trained or N2N-trained models that have more information than ours, and significantly outperforming the recent baselines for the same setting.