 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOption-aware Temporally Abstracted Value for Offline Goal-Conditioned Reinforcement Learning
May 19, 2025Offline goal-conditioned reinforcement learning (GCRL) offers a practical learning paradigm where goal-reaching policies are trained from abundant unlabeled (reward-free) datasets without additional environment interaction. However, offline GCRL still struggles with long-horizon tasks, even with recent advances that employ hierarchical policy structures, such as HIQL. By identifying the root cause of this challenge, we observe the following insights: First, performance bottlenecks mainly stem from the high-level policy's inability to generate appropriate subgoals. Second, when learning the high-level policy in the long-horizon regime, the sign of the advantage signal frequently becomes incorrect. Thus, we argue that improving the value function to produce a clear advantage signal for learning the high-level policy is essential. In this paper, we propose a simple yet effective solution: Option-aware Temporally Abstracted value learning, dubbed OTA, which incorporates temporal abstraction into the temporal-difference learning process. By modifying the value update to be option-aware, the proposed learning scheme contracts the effective horizon length, enabling better advantage estimates even in long-horizon regimes. We experimentally show that the high-level policy extracted using the OTA value function achieves strong performance on complex tasks from OGBench, a recently proposed offline GCRL benchmark, including maze navigation and visual robotic manipulation environments.
Listwise Reward Estimation for Offline Preference-based Reinforcement Learning
Aug 08, 2024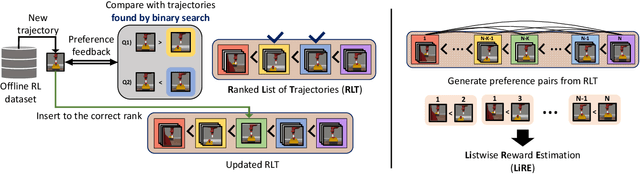

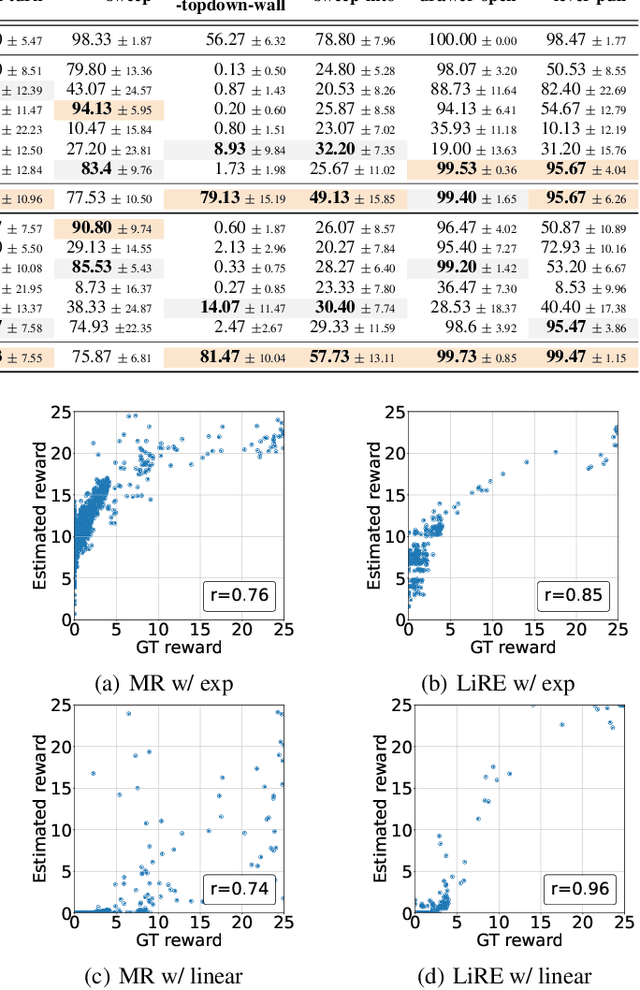
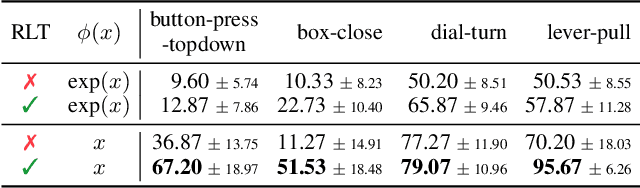
In Reinforcement Learning (RL), designing precise reward functions remains to be a challenge, particularly when aligning with human intent. Preference-based RL (PbRL) was introduced to address this problem by learning reward models from human feedback. However, existing PbRL methods have limitations as they often overlook the second-order preference that indicates the relative strength of preference. In this paper, we propose Listwise Reward Estimation (LiRE), a novel approach for offline PbRL that leverages second-order preference information by constructing a Ranked List of Trajectories (RLT), which can be efficiently built by using the same ternary feedback type as traditional methods. To validate the effectiveness of LiRE, we propose a new offline PbRL dataset that objectively reflects the effect of the estimated rewards. Our extensive experiments on the dataset demonstrate the superiority of LiRE, i.e., outperforming state-of-the-art baselines even with modest feedback budgets and enjoying robustness with respect to the number of feedbacks and feedback noise. Our code is available at https://github.com/chwoong/LiRE