 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Level Explanations for Generative Language Models
Paper and Code

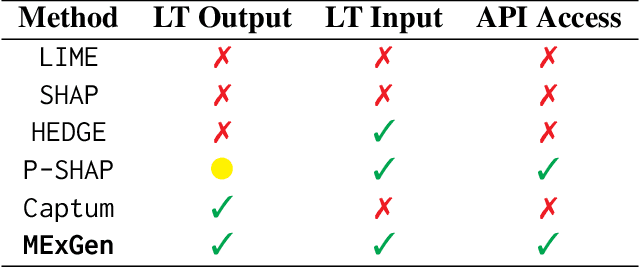
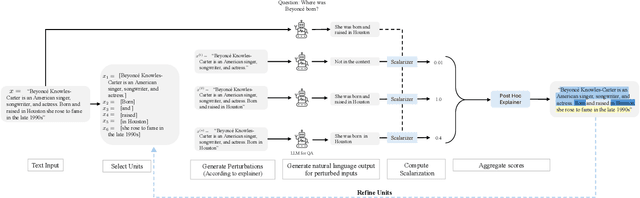

Perturbation-based explanation methods such as LIME and SHAP are commonly applied to text classification. This work focuses on their extension to generative language models. To address the challenges of text as output and long text inputs, we propose a general framework called MExGen that can be instantiated with different attribution algorithms. To handle text output, we introduce the notion of scalarizers for mapping text to real numbers and investigate multiple possibilities. To handle long inputs, we take a multi-level approach, proceeding from coarser levels of granularity to finer ones, and focus on algorithms with linear scaling in model queries. We conduct a systematic evaluation, both automated and human, of perturbation-based attribution methods for summarization and context-grounded question answering. The results show that our framework can provide more locally faithful explanations of generated outputs.