 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerate, Evaluate, Iterate: Synthetic Data for Human-in-the-Loop Refinement of LLM Judges
Nov 06, 2025The LLM-as-a-judge paradigm enables flexible, user-defined evaluation, but its effectiveness is often limited by the scarcity of diverse, representative data for refining criteria. We present a tool that integrates synthetic data generation into the LLM-as-a-judge workflow, empowering users to create tailored and challenging test cases with configurable domains, personas, lengths, and desired outcomes, including borderline cases. The tool also supports AI-assisted inline editing of existing test cases. To enhance transparency and interpretability, it reveals the prompts and explanations behind each generation. In a user study (N=24), 83% of participants preferred the tool over manually creating or selecting test cases, as it allowed them to rapidly generate diverse synthetic data without additional workload. The generated synthetic data proved as effective as hand-crafted data for both refining evaluation criteria and aligning with human preferences. These findings highlight synthetic data as a promising alternative, particularly in contexts where efficiency and scalability are critical.
Hide or Highlight: Understanding the Impact of Factuality Expression on User Trust
Aug 09, 2025Large language models are known to produce outputs that are plausible but factually incorrect. To prevent people from making erroneous decisions by blindly trusting AI, researchers have explored various ways of communicating factuality estimates in AI-generated outputs to end-users. However, little is known about whether revealing content estimated to be factually incorrect influences users' trust when compared to hiding it altogether. We tested four different ways of disclosing an AI-generated output with factuality assessments: transparent (highlights less factual content), attention (highlights factual content), opaque (removes less factual content), ambiguity (makes less factual content vague), and compared them with a baseline response without factuality information. We conducted a human subjects research (N = 148) using the strategies in question-answering scenarios. We found that the opaque and ambiguity strategies led to higher trust while maintaining perceived answer quality, compared to the other strategies. We discuss the efficacy of hiding presumably less factual content to build end-user trust.
Highlight All the Phrases: Enhancing LLM Transparency through Visual Factuality Indicators
Aug 09, 2025Large language models (LLMs) are susceptible to generating inaccurate or false information, often referred to as "hallucinations" or "confabulations." While several technical advancements have been made to detect hallucinated content by assessing the factuality of the model's responses, there is still limited research on how to effectively communicate this information to users. To address this gap, we conducted two scenario-based experiments with a total of 208 participants to systematically compare the effects of various design strategies for communicating factuality scores by assessing participants' ratings of trust, ease in validating response accuracy, and preference. Our findings reveal that participants preferred and trusted a design in which all phrases within a response were color-coded based on factuality scores. Participants also found it easier to validate accuracy of the response in this style compared to a baseline with no style applied. Our study offers practical design guidelines for LLM application developers and designers, aimed at calibrating user trust, aligning with user preferences, and enhancing users' ability to scrutinize LLM outputs.
Facilitating Human-LLM Collaboration through Factuality Scores and Source Attributions
May 30, 2024



While humans increasingly rely on large language models (LLMs), they are susceptible to generating inaccurate or false information, also known as "hallucinations". Technical advancements have been made in algorithms that detect hallucinated content by assessing the factuality of the model's responses and attributing sections of those responses to specific source documents. However, there is limited research on how to effectively communicate this information to users in ways that will help them appropriately calibrate their trust toward LLMs. To address this issue, we conducted a scenario-based study (N=104) to systematically compare the impact of various design strategies for communicating factuality and source attribution on participants' ratings of trust, preferences, and ease in validating response accuracy. Our findings reveal that participants preferred a design in which phrases within a response were color-coded based on the computed factuality scores. Additionally, participants increased their trust ratings when relevant sections of the source material were highlighted or responses were annotated with reference numbers corresponding to those sources, compared to when they received no annotation in the source material. Our study offers practical design guidelines to facilitate human-LLM collaboration and it promotes a new human role to carefully evaluate and take responsibility for their use of LLM outputs.
Multi-Level Explanations for Generative Language Models
Mar 21, 2024
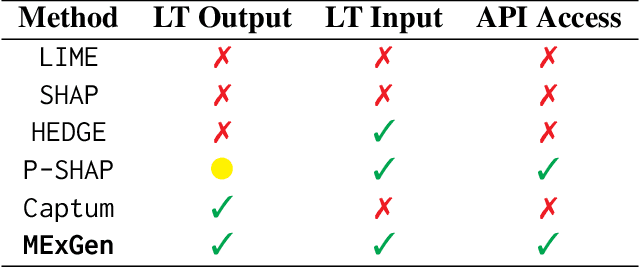
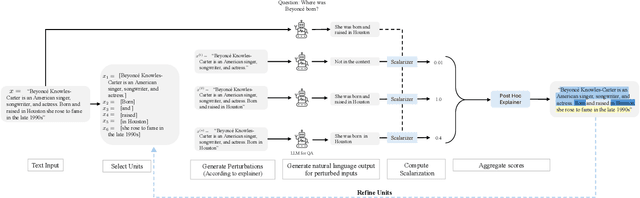

Perturbation-based explanation methods such as LIME and SHAP are commonly applied to text classification. This work focuses on their extension to generative language models. To address the challenges of text as output and long text inputs, we propose a general framework called MExGen that can be instantiated with different attribution algorithms. To handle text output, we introduce the notion of scalarizers for mapping text to real numbers and investigate multiple possibilities. To handle long inputs, we take a multi-level approach, proceeding from coarser levels of granularity to finer ones, and focus on algorithms with linear scaling in model queries. We conduct a systematic evaluation, both automated and human, of perturbation-based attribution methods for summarization and context-grounded question answering. The results show that our framework can provide more locally faithful explanations of generated outputs.