 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Hardness of Faithful Chain-of-Thought Reasoning in Large Language Models
Jun 15, 2024



As Large Language Models (LLMs) are increasingly being employed in real-world applications in critical domains such as healthcare, it is important to ensure that the Chain-of-Thought (CoT) reasoning generated by these models faithfully captures their underlying behavior. While LLMs are known to generate CoT reasoning that is appealing to humans, prior studies have shown that these explanations do not accurately reflect the actual behavior of the underlying LLMs. In this work, we explore the promise of three broad approaches commonly employed to steer the behavior of LLMs to enhance the faithfulness of the CoT reasoning generated by LLMs: in-context learning, fine-tuning, and activation editing. Specifically, we introduce novel strategies for in-context learning, fine-tuning, and activation editing aimed at improving the faithfulness of the CoT reasoning. We then carry out extensive empirical analyses with multiple benchmark datasets to explore the promise of these strategies. Our analyses indicate that these strategies offer limited success in improving the faithfulness of the CoT reasoning, with only slight performance enhancements in controlled scenarios. Activation editing demonstrated minimal success, while fine-tuning and in-context learning achieved marginal improvements that failed to generalize across diverse reasoning and truthful question-answering benchmarks. In summary, our work underscores the inherent difficulty in eliciting faithful CoT reasoning from LLMs, suggesting that the current array of approaches may not be sufficient to address this complex challenge.
Faithfulness vs. Plausibility: On the (Un)Reliability of Explanations from Large Language Models
Feb 08, 2024
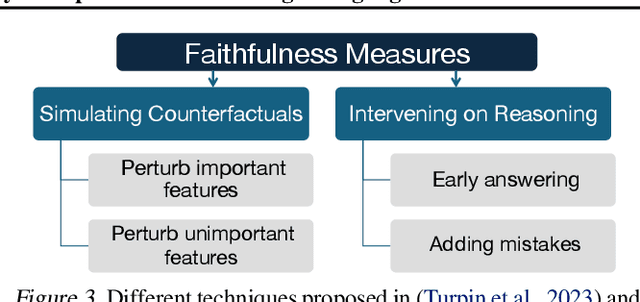

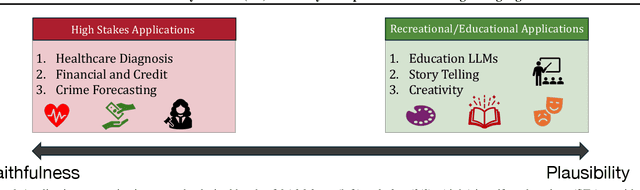
Large Language Models (LLMs) are deployed as powerful tools for several natural language processing (NLP) applications. Recent works show that modern LLMs can generate self-explanations (SEs), which elicit their intermediate reasoning steps for explaining their behavior. Self-explanations have seen widespread adoption owing to their conversational and plausible nature. However, there is little to no understanding of their faithfulness. In this work, we discuss the dichotomy between faithfulness and plausibility in SEs generated by LLMs. We argue that while LLMs are adept at generating plausible explanations -- seemingly logical and coherent to human users -- these explanations do not necessarily align with the reasoning processes of the LLMs, raising concerns about their faithfulness. We highlight that the current trend towards increasing the plausibility of explanations, primarily driven by the demand for user-friendly interfaces, may come at the cost of diminishing their faithfulness. We assert that the faithfulness of explanations is critical in LLMs employed for high-stakes decision-making. Moreover, we urge the community to identify the faithfulness requirements of real-world applications and ensure explanations meet those needs. Finally, we propose some directions for future work, emphasizing the need for novel methodologies and frameworks that can enhance the faithfulness of self-explanations without compromising their plausibility, essential for the transparent deployment of LLMs in diverse high-stakes domains.
Quantifying Uncertainty in Natural Language Explanations of Large Language Models
Nov 06, 2023



Large Language Models (LLMs) are increasingly used as powerful tools for several high-stakes natural language processing (NLP) applications. Recent prompting works claim to elicit intermediate reasoning steps and key tokens that serve as proxy explanations for LLM predictions. However, there is no certainty whether these explanations are reliable and reflect the LLMs behavior. In this work, we make one of the first attempts at quantifying the uncertainty in explanations of LLMs. To this end, we propose two novel metrics -- $\textit{Verbalized Uncertainty}$ and $\textit{Probing Uncertainty}$ -- to quantify the uncertainty of generated explanations. While verbalized uncertainty involves prompting the LLM to express its confidence in its explanations, probing uncertainty leverages sample and model perturbations as a means to quantify the uncertainty. Our empirical analysis of benchmark datasets reveals that verbalized uncertainty is not a reliable estimate of explanation confidence. Further, we show that the probing uncertainty estimates are correlated with the faithfulness of an explanation, with lower uncertainty corresponding to explanations with higher faithfulness. Our study provides insights into the challenges and opportunities of quantifying uncertainty in LLM explanations, contributing to the broader discussion of the trustworthiness of foundation models.
Word-Level Explanations for Analyzing Bias in Text-to-Image Models
Jun 03, 2023Text-to-image models take a sentence (i.e., prompt) and generate images associated with this input prompt. These models have created award wining-art, videos, and even synthetic datasets. However, text-to-image (T2I) models can generate images that underrepresent minorities based on race and sex. This paper investigates which word in the input prompt is responsible for bias in generated images. We introduce a method for computing scores for each word in the prompt; these scores represent its influence on biases in the model's output. Our method follows the principle of \emph{explaining by removing}, leveraging masked language models to calculate the influence scores. We perform experiments on Stable Diffusion to demonstrate that our method identifies the replication of societal stereotypes in generated images.