 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralized Group Data Attribution
Oct 13, 2024



Data Attribution (DA) methods quantify the influence of individual training data points on model outputs and have broad applications such as explainability, data selection, and noisy label identification. However, existing DA methods are often computationally intensive, limiting their applicability to large-scale machine learning models. To address this challenge, we introduce the Generalized Group Data Attribution (GGDA) framework, which computationally simplifies DA by attributing to groups of training points instead of individual ones. GGDA is a general framework that subsumes existing attribution methods and can be applied to new DA techniques as they emerge. It allows users to optimize the trade-off between efficiency and fidelity based on their needs. Our empirical results demonstrate that GGDA applied to popular DA methods such as Influence Functions, TracIn, and TRAK results in upto 10x-50x speedups over standard DA methods while gracefully trading off attribution fidelity. For downstream applications such as dataset pruning and noisy label identification, we demonstrate that GGDA significantly improves computational efficiency and maintains effectiveness, enabling practical applications in large-scale machine learning scenarios that were previously infeasible.
On the Hardness of Faithful Chain-of-Thought Reasoning in Large Language Models
Jun 15, 2024



As Large Language Models (LLMs) are increasingly being employed in real-world applications in critical domains such as healthcare, it is important to ensure that the Chain-of-Thought (CoT) reasoning generated by these models faithfully captures their underlying behavior. While LLMs are known to generate CoT reasoning that is appealing to humans, prior studies have shown that these explanations do not accurately reflect the actual behavior of the underlying LLMs. In this work, we explore the promise of three broad approaches commonly employed to steer the behavior of LLMs to enhance the faithfulness of the CoT reasoning generated by LLMs: in-context learning, fine-tuning, and activation editing. Specifically, we introduce novel strategies for in-context learning, fine-tuning, and activation editing aimed at improving the faithfulness of the CoT reasoning. We then carry out extensive empirical analyses with multiple benchmark datasets to explore the promise of these strategies. Our analyses indicate that these strategies offer limited success in improving the faithfulness of the CoT reasoning, with only slight performance enhancements in controlled scenarios. Activation editing demonstrated minimal success, while fine-tuning and in-context learning achieved marginal improvements that failed to generalize across diverse reasoning and truthful question-answering benchmarks. In summary, our work underscores the inherent difficulty in eliciting faithful CoT reasoning from LLMs, suggesting that the current array of approaches may not be sufficient to address this complex challenge.
Are Large Language Models Post Hoc Explainers?
Oct 10, 2023



Large Language Models (LLMs) are increasingly used as powerful tools for a plethora of natural language processing (NLP) applications. A recent innovation, in-context learning (ICL), enables LLMs to learn new tasks by supplying a few examples in the prompt during inference time, thereby eliminating the need for model fine-tuning. While LLMs have been utilized in several applications, their applicability in explaining the behavior of other models remains relatively unexplored. Despite the growing number of new explanation techniques, many require white-box access to the model and/or are computationally expensive, highlighting a need for next-generation post hoc explainers. In this work, we present the first framework to study the effectiveness of LLMs in explaining other predictive models. More specifically, we propose a novel framework encompassing multiple prompting strategies: i) Perturbation-based ICL, ii) Prediction-based ICL, iii) Instruction-based ICL, and iv) Explanation-based ICL, with varying levels of information about the underlying ML model and the local neighborhood of the test sample. We conduct extensive experiments with real-world benchmark datasets to demonstrate that LLM-generated explanations perform on par with state-of-the-art post hoc explainers using their ability to leverage ICL examples and their internal knowledge in generating model explanations. On average, across four datasets and two ML models, we observe that LLMs identify the most important feature with 72.19% accuracy, opening up new frontiers in explainable artificial intelligence (XAI) to explore LLM-based explanation frameworks.
Consistent Explanations in the Face of Model Indeterminacy via Ensembling
Jun 13, 2023



This work addresses the challenge of providing consistent explanations for predictive models in the presence of model indeterminacy, which arises due to the existence of multiple (nearly) equally well-performing models for a given dataset and task. Despite their similar performance, such models often exhibit inconsistent or even contradictory explanations for their predictions, posing challenges to end users who rely on these models to make critical decisions. Recognizing this issue, we introduce ensemble methods as an approach to enhance the consistency of the explanations provided in these scenarios. Leveraging insights from recent work on neural network loss landscapes and mode connectivity, we devise ensemble strategies to efficiently explore the underspecification set -- the set of models with performance variations resulting solely from changes in the random seed during training. Experiments on five benchmark financial datasets reveal that ensembling can yield significant improvements when it comes to explanation similarity, and demonstrate the potential of existing ensemble methods to explore the underspecification set efficiently. Our findings highlight the importance of considering model indeterminacy when interpreting explanations and showcase the effectiveness of ensembles in enhancing the reliability of explanations in machine learning.
On Minimizing the Impact of Dataset Shifts on Actionable Explanations
Jun 11, 2023



The Right to Explanation is an important regulatory principle that allows individuals to request actionable explanations for algorithmic decisions. However, several technical challenges arise when providing such actionable explanations in practice. For instance, models are periodically retrained to handle dataset shifts. This process may invalidate some of the previously prescribed explanations, thus rendering them unactionable. But, it is unclear if and when such invalidations occur, and what factors determine explanation stability i.e., if an explanation remains unchanged amidst model retraining due to dataset shifts. In this paper, we address the aforementioned gaps and provide one of the first theoretical and empirical characterizations of the factors influencing explanation stability. To this end, we conduct rigorous theoretical analysis to demonstrate that model curvature, weight decay parameters while training, and the magnitude of the dataset shift are key factors that determine the extent of explanation (in)stability. Extensive experimentation with real-world datasets not only validates our theoretical results, but also demonstrates that the aforementioned factors dramatically impact the stability of explanations produced by various state-of-the-art methods.
Degraded Polygons Raise Fundamental Questions of Neural Network Perception
Jun 08, 2023



It is well-known that modern computer vision systems often exhibit behaviors misaligned with those of humans: from adversarial attacks to image corruptions, deep learning vision models suffer in a variety of settings that humans capably handle. In light of these phenomena, here we introduce another, orthogonal perspective studying the human-machine vision gap. We revisit the task of recovering images under degradation, first introduced over 30 years ago in the Recognition-by-Components theory of human vision. Specifically, we study the performance and behavior of neural networks on the seemingly simple task of classifying regular polygons at varying orders of degradation along their perimeters. To this end, we implement the Automated Shape Recoverability Test for rapidly generating large-scale datasets of perimeter-degraded regular polygons, modernizing the historically manual creation of image recoverability experiments. We then investigate the capacity of neural networks to recognize and recover such degraded shapes when initialized with different priors. Ultimately, we find that neural networks' behavior on this simple task conflicts with human behavior, raising a fundamental question of the robustness and learning capabilities of modern computer vision models.
GLOBE-CE: A Translation-Based Approach for Global Counterfactual Explanations
May 26, 2023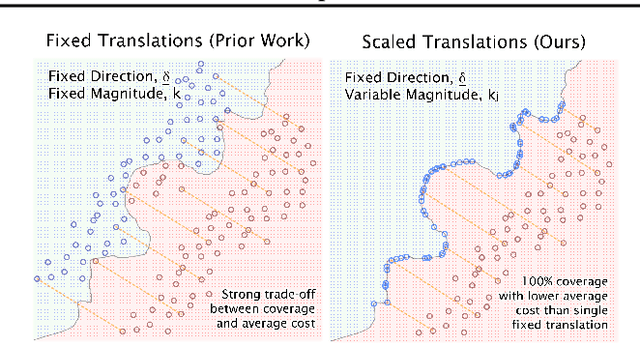

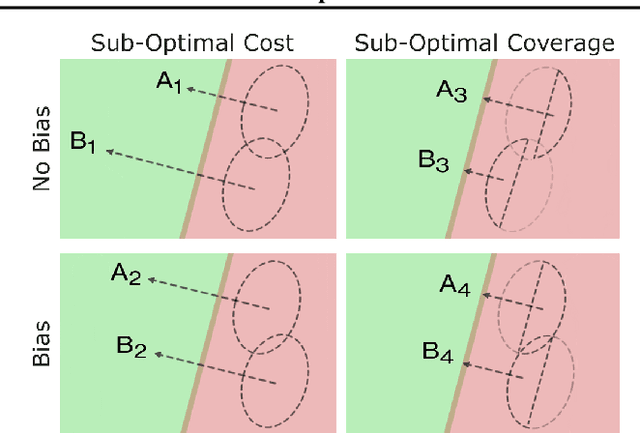

Counterfactual explanations have been widely studied in explainability, with a range of application dependent methods prominent in fairness, recourse and model understanding. The major shortcoming associated with these methods, however, is their inability to provide explanations beyond the local or instance-level. While many works touch upon the notion of a global explanation, typically suggesting to aggregate masses of local explanations in the hope of ascertaining global properties, few provide frameworks that are both reliable and computationally tractable. Meanwhile, practitioners are requesting more efficient and interactive explainability tools. We take this opportunity to propose Global & Efficient Counterfactual Explanations (GLOBE-CE), a flexible framework that tackles the reliability and scalability issues associated with current state-of-the-art, particularly on higher dimensional datasets and in the presence of continuous features. Furthermore, we provide a unique mathematical analysis of categorical feature translations, utilising it in our method. Experimental evaluation with publicly available datasets and user studies demonstrate that GLOBE-CE performs significantly better than the current state-of-the-art across multiple metrics (e.g., speed, reliability).
Global Counterfactual Explanations: Investigations, Implementations and Improvements
Apr 14, 2022


Counterfactual explanations have been widely studied in explainability, with a range of application dependent methods emerging in fairness, recourse and model understanding. However, the major shortcoming associated with these methods is their inability to provide explanations beyond the local or instance-level. While some works touch upon the notion of a global explanation, typically suggesting to aggregate masses of local explanations in the hope of ascertaining global properties, few provide frameworks that are either reliable or computationally tractable. Meanwhile, practitioners are requesting more efficient and interactive explainability tools. We take this opportunity to investigate existing global methods, with a focus on implementing and improving Actionable Recourse Summaries (AReS), the only known global counterfactual explanation framework for recourse.
Diverse, Global and Amortised Counterfactual Explanations for Uncertainty Estimates
Dec 09, 2021
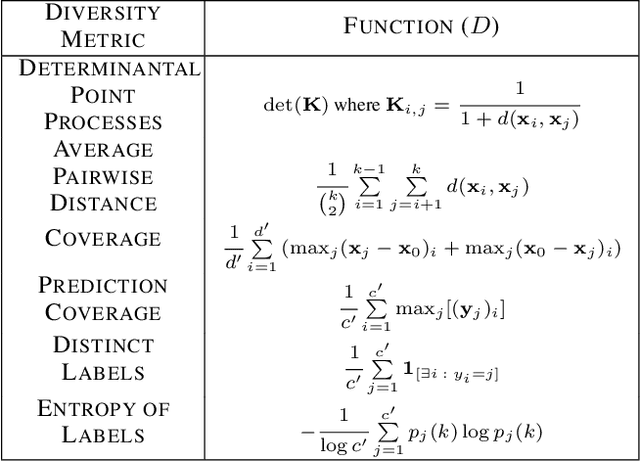


To interpret uncertainty estimates from differentiable probabilistic models, recent work has proposed generating a single Counterfactual Latent Uncertainty Explanation (CLUE) for a given data point where the model is uncertain, identifying a single, on-manifold change to the input such that the model becomes more certain in its prediction. We broaden the exploration to examine $\delta$-CLUE, the set of potential CLUEs within a $\delta$ ball of the original input in latent space. We study the diversity of such sets and find that many CLUEs are redundant; as such, we propose DIVerse CLUE ($\nabla$-CLUE), a set of CLUEs which each propose a distinct explanation as to how one can decrease the uncertainty associated with an input. We then further propose GLobal AMortised CLUE (GLAM-CLUE), a distinct and novel method which learns amortised mappings on specific groups of uncertain inputs, taking them and efficiently transforming them in a single function call into inputs for which a model will be certain. Our experiments show that $\delta$-CLUE, $\nabla$-CLUE, and GLAM-CLUE all address shortcomings of CLUE and provide beneficial explanations of uncertainty estimates to practitioners.
δ-CLUE: Diverse Sets of Explanations for Uncertainty Estimates
May 08, 2021
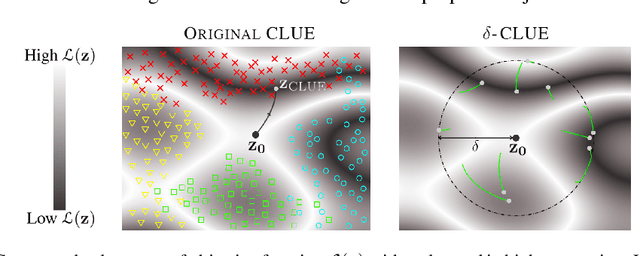


To interpret uncertainty estimates from differentiable probabilistic models, recent work has proposed generating Counterfactual Latent Uncertainty Explanations (CLUEs). However, for a single input, such approaches could output a variety of explanations due to the lack of constraints placed on the explanation. Here we augment the original CLUE approach, to provide what we call $\delta$-CLUE. CLUE indicates $\it{one}$ way to change an input, while remaining on the data manifold, such that the model becomes more confident about its prediction. We instead return a $\it{set}$ of plausible CLUEs: multiple, diverse inputs that are within a $\delta$ ball of the original input in latent space, all yielding confident predictions.