 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVerified Training for Counterfactual Explanation Robustness under Data Shift
Mar 06, 2024Counterfactual explanations (CEs) enhance the interpretability of machine learning models by describing what changes to an input are necessary to change its prediction to a desired class. These explanations are commonly used to guide users' actions, e.g., by describing how a user whose loan application was denied can be approved for a loan in the future. Existing approaches generate CEs by focusing on a single, fixed model, and do not provide any formal guarantees on the CEs' future validity. When models are updated periodically to account for data shift, if the generated CEs are not robust to the shifts, users' actions may no longer have the desired impacts on their predictions. This paper introduces VeriTraCER, an approach that jointly trains a classifier and an explainer to explicitly consider the robustness of the generated CEs to small model shifts. VeriTraCER optimizes over a carefully designed loss function that ensures the verifiable robustness of CEs to local model updates, thus providing deterministic guarantees to CE validity. Our empirical evaluation demonstrates that VeriTraCER generates CEs that (1) are verifiably robust to small model updates and (2) display competitive robustness to state-of-the-art approaches in handling empirical model updates including random initialization, leave-one-out, and distribution shifts.
On Minimizing the Impact of Dataset Shifts on Actionable Explanations
Jun 11, 2023



The Right to Explanation is an important regulatory principle that allows individuals to request actionable explanations for algorithmic decisions. However, several technical challenges arise when providing such actionable explanations in practice. For instance, models are periodically retrained to handle dataset shifts. This process may invalidate some of the previously prescribed explanations, thus rendering them unactionable. But, it is unclear if and when such invalidations occur, and what factors determine explanation stability i.e., if an explanation remains unchanged amidst model retraining due to dataset shifts. In this paper, we address the aforementioned gaps and provide one of the first theoretical and empirical characterizations of the factors influencing explanation stability. To this end, we conduct rigorous theoretical analysis to demonstrate that model curvature, weight decay parameters while training, and the magnitude of the dataset shift are key factors that determine the extent of explanation (in)stability. Extensive experimentation with real-world datasets not only validates our theoretical results, but also demonstrates that the aforementioned factors dramatically impact the stability of explanations produced by various state-of-the-art methods.
The Dataset Multiplicity Problem: How Unreliable Data Impacts Predictions
Apr 20, 2023We introduce dataset multiplicity, a way to study how inaccuracies, uncertainty, and social bias in training datasets impact test-time predictions. The dataset multiplicity framework asks a counterfactual question of what the set of resultant models (and associated test-time predictions) would be if we could somehow access all hypothetical, unbiased versions of the dataset. We discuss how to use this framework to encapsulate various sources of uncertainty in datasets' factualness, including systemic social bias, data collection practices, and noisy labels or features. We show how to exactly analyze the impacts of dataset multiplicity for a specific model architecture and type of uncertainty: linear models with label errors. Our empirical analysis shows that real-world datasets, under reasonable assumptions, contain many test samples whose predictions are affected by dataset multiplicity. Furthermore, the choice of domain-specific dataset multiplicity definition determines what samples are affected, and whether different demographic groups are disparately impacted. Finally, we discuss implications of dataset multiplicity for machine learning practice and research, including considerations for when model outcomes should not be trusted.
Certifying Data-Bias Robustness in Linear Regression
Jun 07, 2022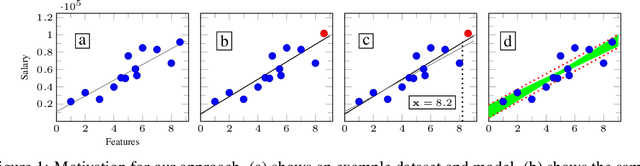

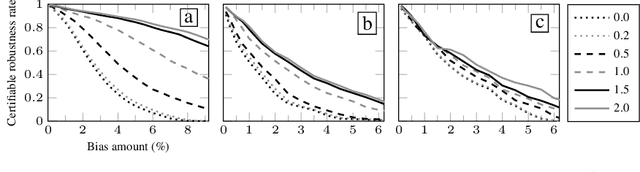
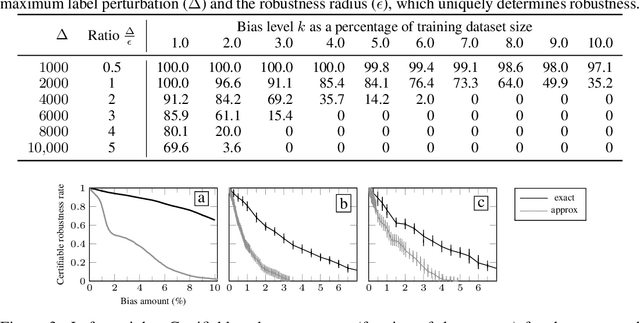
Datasets typically contain inaccuracies due to human error and societal biases, and these inaccuracies can affect the outcomes of models trained on such datasets. We present a technique for certifying whether linear regression models are pointwise-robust to label bias in the training dataset, i.e., whether bounded perturbations to the labels of a training dataset result in models that change the prediction of test points. We show how to solve this problem exactly for individual test points, and provide an approximate but more scalable method that does not require advance knowledge of the test point. We extensively evaluate both techniques and find that linear models -- both regression- and classification-based -- often display high levels of bias-robustness. However, we also unearth gaps in bias-robustness, such as high levels of non-robustness for certain bias assumptions on some datasets. Overall, our approach can serve as a guide for when to trust, or question, a model's output.
Certifying Robustness to Programmable Data Bias in Decision Trees
Oct 08, 2021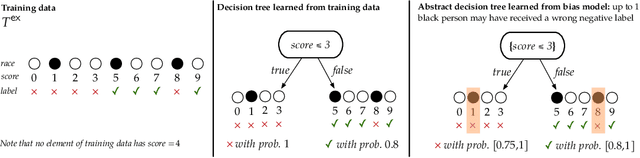
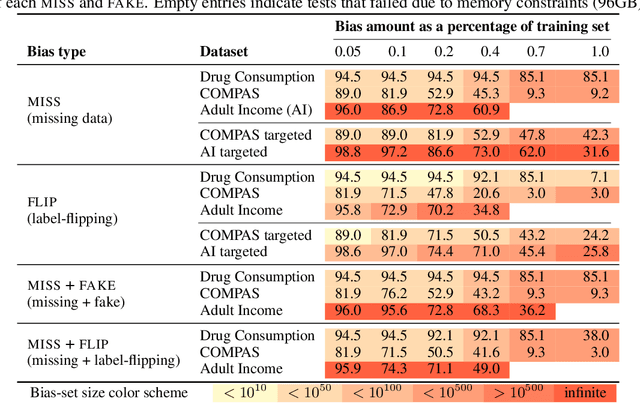

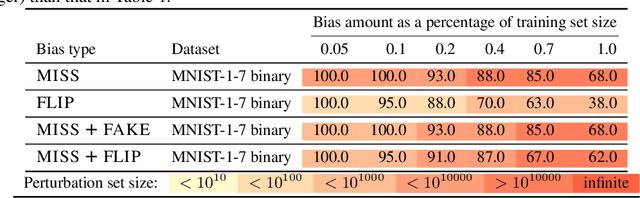
Datasets can be biased due to societal inequities, human biases, under-representation of minorities, etc. Our goal is to certify that models produced by a learning algorithm are pointwise-robust to potential dataset biases. This is a challenging problem: it entails learning models for a large, or even infinite, number of datasets, ensuring that they all produce the same prediction. We focus on decision-tree learning due to the interpretable nature of the models. Our approach allows programmatically specifying bias models across a variety of dimensions (e.g., missing data for minorities), composing types of bias, and targeting bias towards a specific group. To certify robustness, we use a novel symbolic technique to evaluate a decision-tree learner on a large, or infinite, number of datasets, certifying that each and every dataset produces the same prediction for a specific test point. We evaluate our approach on datasets that are commonly used in the fairness literature, and demonstrate our approach's viability on a range of bias models.