 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeU-Define: Designing User Workflows for Hard and Soft Constraints in LLM-Based Planning
May 04, 2026LLMs are increasingly used for end-user task planning, yet their black-box nature limits users' ability to ensure reliability and control. While recent systems incorporate verification techniques, it remains unclear how users can effectively apply such rigid constraints to represent intent or adapt to real-world variability. For example, prior work finds that hard-only constraints are too rigid, and numeric flexibility weights confuse users. We investigate how interaction workflows can better support users in applying constraints to guide LLM-generated plans, examining whether abstracting strictness into high-level types (i.e., hard and soft) paired with distinct verification mechanisms helps users more reliably express and align intent. We present U-Define, a system that lets users define constraints in natural language and categorize them as either hard rules that must not be violated or soft preferences that allow flexibility. U-Define verifies these types through complementary methods: formal model checking for hard constraints and LLM-as-judge evaluation for soft ones. Through a technical evaluation and user studies with general and expert participants, we find that user-defined constraint types improve perceived usefulness, performance, and satisfaction while maintaining usability. These findings provide insights for designing flexible yet reliable constraint-based workflows.
Test-Time Scaling Makes Overtraining Compute-Optimal
Apr 01, 2026Modern LLMs scale at test-time, e.g. via repeated sampling, where inference cost grows with model size and the number of samples. This creates a trade-off that pretraining scaling laws, such as Chinchilla, do not address. We present Train-to-Test ($T^2$) scaling laws that jointly optimize model size, training tokens, and number of inference samples under fixed end-to-end budgets. $T^2$ modernizes pretraining scaling laws with pass@$k$ modeling used for test-time scaling, then jointly optimizes pretraining and test-time decisions. Forecasts from $T^2$ are robust over distinct modeling approaches: measuring joint scaling effect on the task loss and modeling impact on task accuracy. Across eight downstream tasks, we find that when accounting for inference cost, optimal pretraining decisions shift radically into the overtraining regime, well-outside of the range of standard pretraining scaling suites. We validate our results by pretraining heavily overtrained models in the optimal region that $T^2$ scaling forecasts, confirming their substantially stronger performance compared to pretraining scaling alone. Finally, as frontier LLMs are post-trained, we show that our findings survive the post-training stage, making $T^2$ scaling meaningful in modern deployments.
SlopCodeBench: Benchmarking How Coding Agents Degrade Over Long-Horizon Iterative Tasks
Mar 25, 2026Software development is iterative, yet agentic coding benchmarks overwhelmingly evaluate single-shot solutions against complete specifications. Code can pass the test suite but become progressively harder to extend. Recent iterative benchmarks attempt to close this gap, but constrain the agent's design decisions too tightly to faithfully measure how code quality shapes future extensions. We introduce SlopCodeBench, a language-agnostic benchmark comprising 20 problems and 93 checkpoints, in which agents repeatedly extend their own prior solutions under evolving specifications that force architectural decisions without prescribing internal structure. We track two trajectory-level quality signals: verbosity, the fraction of redundant or duplicated code, and structural erosion, the share of complexity mass concentrated in high-complexity functions. No agent solves any problem end-to-end across 11 models; the highest checkpoint solve rate is 17.2%. Quality degrades steadily: erosion rises in 80% of trajectories and verbosity in 89.8%. Against 48 open-source Python repositories, agent code is 2.2x more verbose and markedly more eroded. Tracking 20 of those repositories over time shows that human code stays flat, while agent code deteriorates with each iteration. A prompt-intervention study shows that initial quality can be improved, but it does not halt degradation. These results demonstrate that pass-rate benchmarks systematically undermeasure extension robustness, and that current agents lack the design discipline iterative software development demands.
SkillOrchestra: Learning to Route Agents via Skill Transfer
Feb 23, 2026Compound AI systems promise capabilities beyond those of individual models, yet their success depends critically on effective orchestration. Existing routing approaches face two limitations: (1) input-level routers make coarse query-level decisions that ignore evolving task requirements; (2) RL-trained orchestrators are expensive to adapt and often suffer from routing collapse, repeatedly invoking one strong but costly option in multi-turn scenarios. We introduce SkillOrchestra, a framework for skill-aware orchestration. Instead of directly learning a routing policy end-to-end, SkillOrchestra learns fine-grained skills from execution experience and models agent-specific competence and cost under those skills. At deployment, the orchestrator infers the skill demands of the current interaction and selects agents that best satisfy them under an explicit performance-cost trade-off. Extensive experiments across ten benchmarks demonstrate that SkillOrchestra outperforms SoTA RL-based orchestrators by up to 22.5% with 700x and 300x learning cost reduction compared to Router-R1 and ToolOrchestra, respectively. These results show that explicit skill modeling enables scalable, interpretable, and sample-efficient orchestration, offering a principled alternative to data-intensive RL-based approaches. The code is available at: https://github.com/jiayuww/SkillOrchestra.
LiveResearchBench: A Live Benchmark for User-Centric Deep Research in the Wild
Oct 16, 2025Deep research -- producing comprehensive, citation-grounded reports by searching and synthesizing information from hundreds of live web sources -- marks an important frontier for agentic systems. To rigorously evaluate this ability, four principles are essential: tasks should be (1) user-centric, reflecting realistic information needs, (2) dynamic, requiring up-to-date information beyond parametric knowledge, (3) unambiguous, ensuring consistent interpretation across users, and (4) multi-faceted and search-intensive, requiring search over numerous web sources and in-depth analysis. Existing benchmarks fall short of these principles, often focusing on narrow domains or posing ambiguous questions that hinder fair comparison. Guided by these principles, we introduce LiveResearchBench, a benchmark of 100 expert-curated tasks spanning daily life, enterprise, and academia, each requiring extensive, dynamic, real-time web search and synthesis. Built with over 1,500 hours of human labor, LiveResearchBench provides a rigorous basis for systematic evaluation. To evaluate citation-grounded long-form reports, we introduce DeepEval, a comprehensive suite covering both content- and report-level quality, including coverage, presentation, citation accuracy and association, consistency and depth of analysis. DeepEval integrates four complementary evaluation protocols, each designed to ensure stable assessment and high agreement with human judgments. Using LiveResearchBench and DeepEval, we conduct a comprehensive evaluation of 17 frontier deep research systems, including single-agent web search, single-agent deep research, and multi-agent systems. Our analysis reveals current strengths, recurring failure modes, and key system components needed to advance reliable, insightful deep research.
Beyond Accuracy: Dissecting Mathematical Reasoning for LLMs Under Reinforcement Learning
Jun 05, 2025Reinforcement learning (RL) has become the dominant paradigm for endowing language models with advanced reasoning capabilities. Despite the substantial empirical gains demonstrated by RL-based training methods like GRPO, a granular understanding of their advantages is still lacking. To address this gap, we introduce a fine-grained analytic framework to dissect the impact of RL on reasoning. Our framework specifically investigates key elements that have been hypothesized to benefit from RL training: (1) plan-following and execution, (2) problem decomposition, and (3) improved reasoning and knowledge utilization. Using this framework, we gain insights beyond mere accuracy. For instance, providing models with explicit step-by-step plans surprisingly degrades performance on the most challenging benchmarks, yet RL-tuned models exhibit greater robustness, experiencing markedly smaller performance drops than their base counterparts. This suggests that RL may not primarily enhance the execution of external plans but rather empower models to formulate and follow internal strategies better suited to their reasoning processes. Conversely, we observe that RL enhances the model's capacity to integrate provided knowledge into its reasoning process, leading to performance improvements across diverse tasks. We also study difficulty, showing improved training by developing new ways to exploit hard problems. Our findings lay a foundation for more principled training and evaluation of reasoning models.
COSMOS: Predictable and Cost-Effective Adaptation of LLMs
Apr 30, 2025Large language models (LLMs) achieve remarkable performance across numerous tasks by using a diverse array of adaptation strategies. However, optimally selecting a model and adaptation strategy under resource constraints is challenging and often requires extensive experimentation. We investigate whether it is possible to accurately predict both performance and cost without expensive trials. We formalize the strategy selection problem for LLMs and introduce COSMOS, a unified prediction framework that efficiently estimates adaptation outcomes at minimal cost. We instantiate and study the capability of our framework via a pair of powerful predictors: embedding-augmented lightweight proxy models to predict fine-tuning performance, and low-sample scaling laws to forecast retrieval-augmented in-context learning. Extensive evaluation across eight representative benchmarks demonstrates that COSMOS achieves high prediction accuracy while reducing computational costs by 92.72% on average, and up to 98.71% in resource-intensive scenarios. Our results show that efficient prediction of adaptation outcomes is not only feasible but can substantially reduce the computational overhead of LLM deployment while maintaining performance standards.
A One-Layer Decoder-Only Transformer is a Two-Layer RNN: With an Application to Certified Robustness
May 27, 2024This paper reveals a key insight that a one-layer decoder-only Transformer is equivalent to a two-layer Recurrent Neural Network (RNN). Building on this insight, we propose ARC-Tran, a novel approach for verifying the robustness of decoder-only Transformers against arbitrary perturbation spaces. Compared to ARC-Tran, current robustness verification techniques are limited either to specific and length-preserving perturbations like word substitutions or to recursive models like LSTMs. ARC-Tran addresses these limitations by meticulously managing position encoding to prevent mismatches and by utilizing our key insight to achieve precise and scalable verification. Our evaluation shows that ARC-Tran (1) trains models more robust to arbitrary perturbation spaces than those produced by existing techniques and (2) shows high certification accuracy of the resulting models.
Crowdsourcing Task Traces for Service Robotics
Mar 20, 2024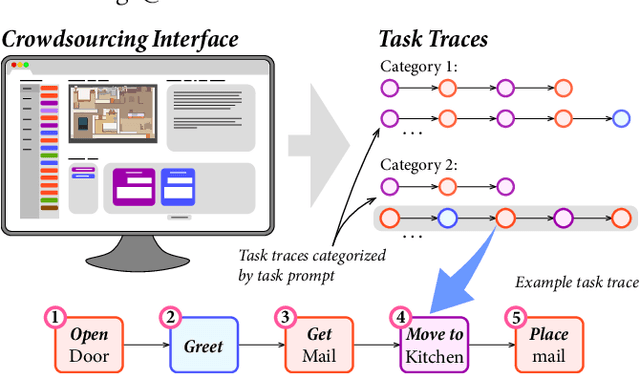
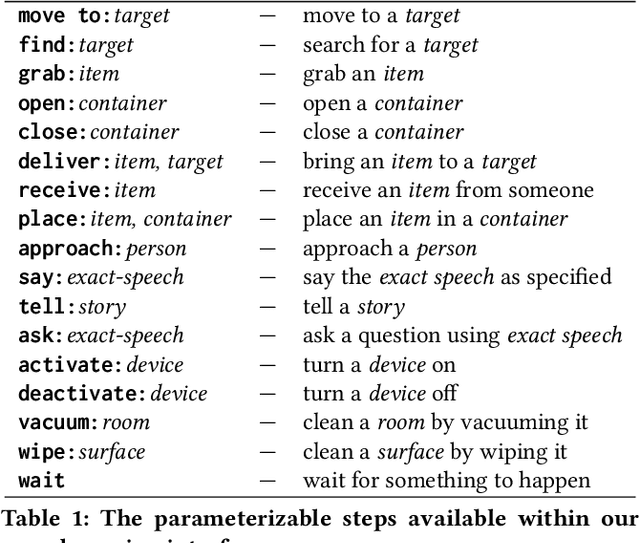
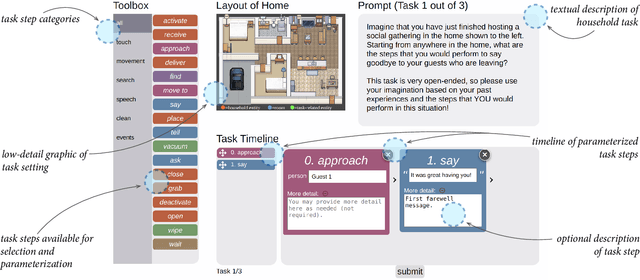
Demonstration is an effective end-user development paradigm for teaching robots how to perform new tasks. In this paper, we posit that demonstration is useful not only as a teaching tool, but also as a way to understand and assist end-user developers in thinking about a task at hand. As a first step toward gaining this understanding, we constructed a lightweight web interface to crowdsource step-by-step instructions of common household tasks, leveraging the imaginations and past experiences of potential end-user developers. As evidence of the utility of our interface, we deployed the interface on Amazon Mechanical Turk and collected 207 task traces that span 18 different task categories. We describe our vision for how these task traces can be operationalized as task models within end-user development tools and provide a roadmap for future work.
Verified Training for Counterfactual Explanation Robustness under Data Shift
Mar 06, 2024Counterfactual explanations (CEs) enhance the interpretability of machine learning models by describing what changes to an input are necessary to change its prediction to a desired class. These explanations are commonly used to guide users' actions, e.g., by describing how a user whose loan application was denied can be approved for a loan in the future. Existing approaches generate CEs by focusing on a single, fixed model, and do not provide any formal guarantees on the CEs' future validity. When models are updated periodically to account for data shift, if the generated CEs are not robust to the shifts, users' actions may no longer have the desired impacts on their predictions. This paper introduces VeriTraCER, an approach that jointly trains a classifier and an explainer to explicitly consider the robustness of the generated CEs to small model shifts. VeriTraCER optimizes over a carefully designed loss function that ensures the verifiable robustness of CEs to local model updates, thus providing deterministic guarantees to CE validity. Our empirical evaluation demonstrates that VeriTraCER generates CEs that (1) are verifiably robust to small model updates and (2) display competitive robustness to state-of-the-art approaches in handling empirical model updates including random initialization, leave-one-out, and distribution shifts.