 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre Large Language Models Post Hoc Explainers?
Oct 10, 2023



Large Language Models (LLMs) are increasingly used as powerful tools for a plethora of natural language processing (NLP) applications. A recent innovation, in-context learning (ICL), enables LLMs to learn new tasks by supplying a few examples in the prompt during inference time, thereby eliminating the need for model fine-tuning. While LLMs have been utilized in several applications, their applicability in explaining the behavior of other models remains relatively unexplored. Despite the growing number of new explanation techniques, many require white-box access to the model and/or are computationally expensive, highlighting a need for next-generation post hoc explainers. In this work, we present the first framework to study the effectiveness of LLMs in explaining other predictive models. More specifically, we propose a novel framework encompassing multiple prompting strategies: i) Perturbation-based ICL, ii) Prediction-based ICL, iii) Instruction-based ICL, and iv) Explanation-based ICL, with varying levels of information about the underlying ML model and the local neighborhood of the test sample. We conduct extensive experiments with real-world benchmark datasets to demonstrate that LLM-generated explanations perform on par with state-of-the-art post hoc explainers using their ability to leverage ICL examples and their internal knowledge in generating model explanations. On average, across four datasets and two ML models, we observe that LLMs identify the most important feature with 72.19% accuracy, opening up new frontiers in explainable artificial intelligence (XAI) to explore LLM-based explanation frameworks.
Multi-Target Multiple Instance Learning for Hyperspectral Target Detection
Sep 07, 2019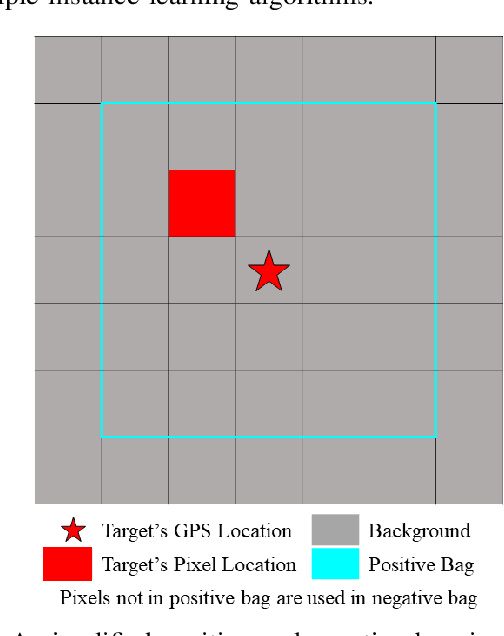
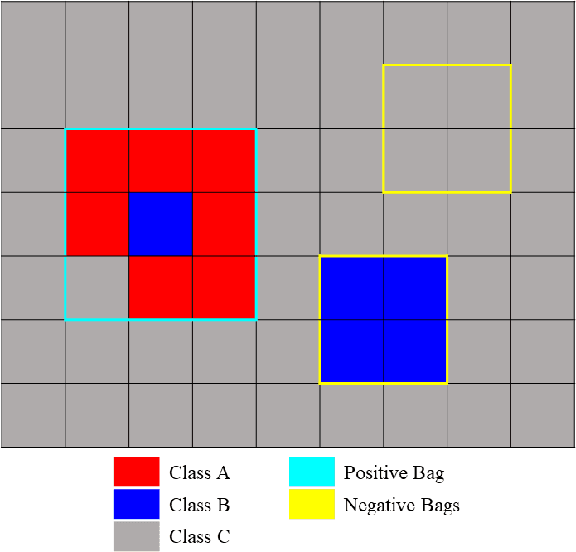
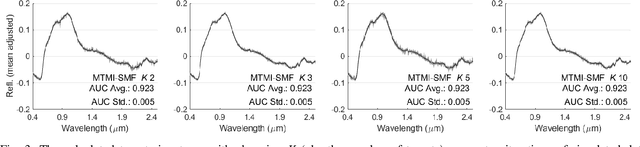
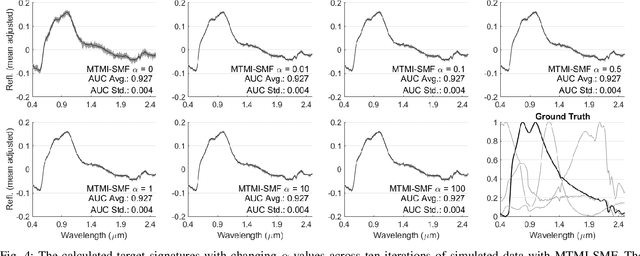
In remote sensing, it is often difficult to acquire or collect a large dataset that is accurately labeled. This difficulty is often due to several issues including but not limited to the study site's spatial area and accessibility, errors in global positioning system (GPS), and mixed pixels caused by an image's spatial resolution. An approach, with two variations, is proposed that estimates multiple target signatures from mixed training samples with imprecise labels: Multi-Target Multiple Instance Adaptive Cosine Estimator (Multi-Target MI-ACE) and Multi-Target Multiple Instance Spectral Match Filter (Multi-Target MI-SMF). The proposed methods address the problems above by directly considering the multiple-instance, imprecisely labeled dataset and learns a dictionary of target signatures that optimizes detection using the Adaptive Cosine Estimator (ACE) and Spectral Match Filter (SMF) against a background. The algorithms have two primary steps, initialization and optimization. The initialization process determines diverse target representatives, while the optimization process simultaneously updates the target representatives to maximize detection while learning the number of optimal signatures to describe the target class. Three designed experiments were done to test the proposed algorithms: a simulated hyperspectral dataset, the MUUFL Gulfport hyperspectral dataset collected over the University of Southern Mississippi-Gulfpark Campus, and the AVIRIS hyperspectral dataset collected over Santa Barbara County, California. Both simulated and real hyperspectral target detection experiments show the proposed algorithms are effective at learning target signatures and performing target detection.