 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShared Manifold Learning Using a Triplet Network for Multiple Sensor Translation and Fusion with Missing Data
Oct 25, 2022
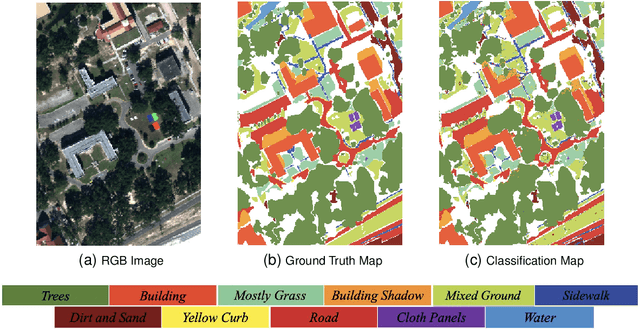
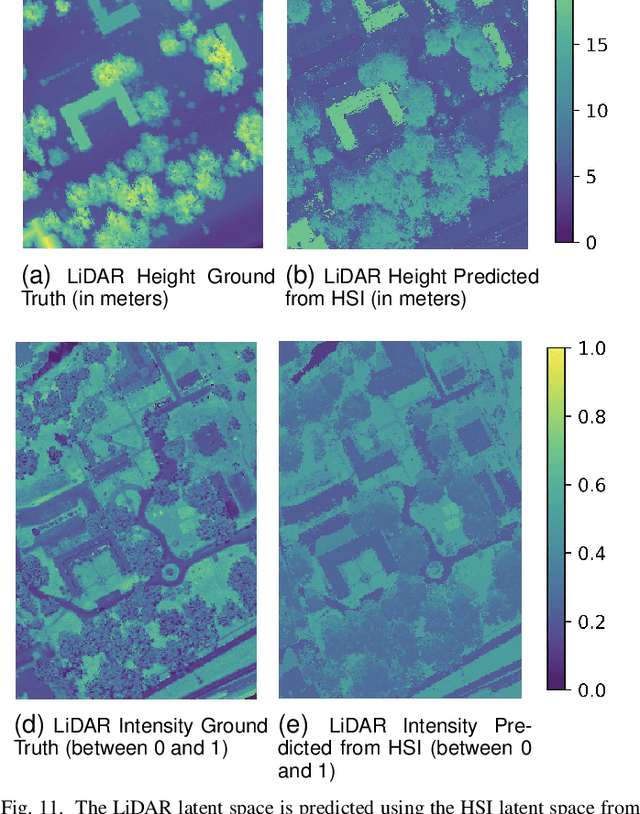
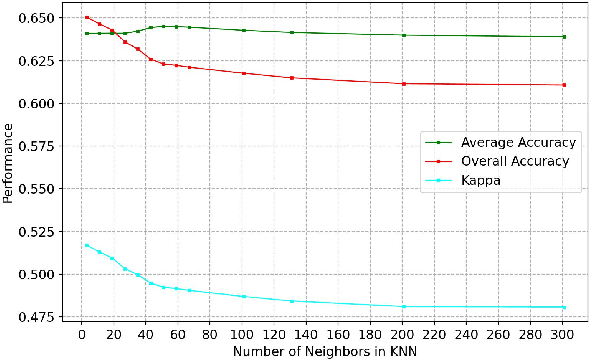
Heterogeneous data fusion can enhance the robustness and accuracy of an algorithm on a given task. However, due to the difference in various modalities, aligning the sensors and embedding their information into discriminative and compact representations is challenging. In this paper, we propose a Contrastive learning based MultiModal Alignment Network (CoMMANet) to align data from different sensors into a shared and discriminative manifold where class information is preserved. The proposed architecture uses a multimodal triplet autoencoder to cluster the latent space in such a way that samples of the same classes from each heterogeneous modality are mapped close to each other. Since all the modalities exist in a shared manifold, a unified classification framework is proposed. The resulting latent space representations are fused to perform more robust and accurate classification. In a missing sensor scenario, the latent space of one sensor is easily and efficiently predicted using another sensor's latent space, thereby allowing sensor translation. We conducted extensive experiments on a manually labeled multimodal dataset containing hyperspectral data from AVIRIS-NG and NEON, and LiDAR (light detection and ranging) data from NEON. Lastly, the model is validated on two benchmark datasets: Berlin Dataset (hyperspectral and synthetic aperture radar) and MUUFL Gulfport Dataset (hyperspectral and LiDAR). A comparison made with other methods demonstrates the superiority of this method. We achieved a mean overall accuracy of 94.3% on the MUUFL dataset and the best overall accuracy of 71.26% on the Berlin dataset, which is better than other state-of-the-art approaches.
Robust Semi-Supervised Classification using GANs with Self-Organizing Maps
Oct 19, 2021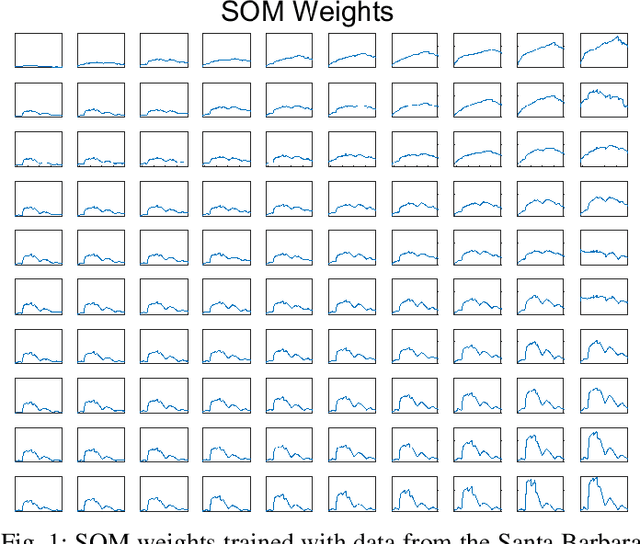
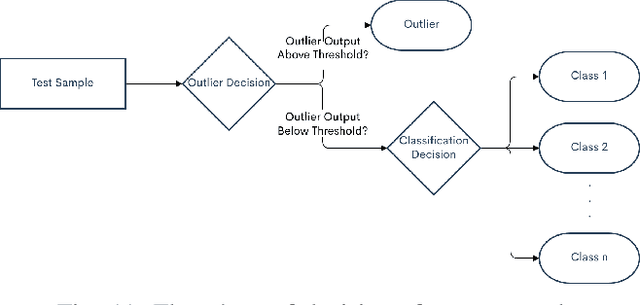
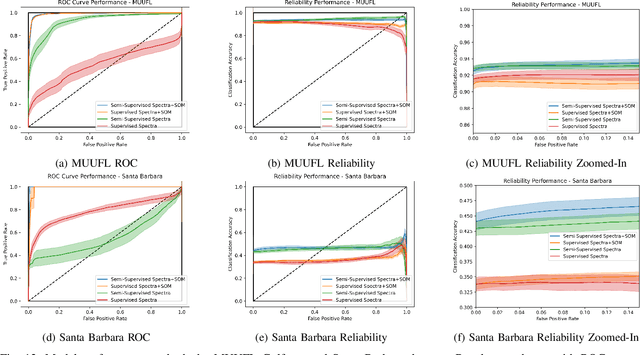
Generative adversarial networks (GANs) have shown tremendous promise in learning to generate data and effective at aiding semi-supervised classification. However, to this point, semi-supervised GAN methods make the assumption that the unlabeled data set contains only samples of the joint distribution of the classes of interest, referred to as inliers. Consequently, when presented with a sample from other distributions, referred to as outliers, GANs perform poorly at determining that it is not qualified to make a decision on the sample. The problem of discriminating outliers from inliers while maintaining classification accuracy is referred to here as the DOIC problem. In this work, we describe an architecture that combines self-organizing maps (SOMs) with SS-GANS with the goal of mitigating the DOIC problem and experimental results indicating that the architecture achieves the goal. Multiple experiments were conducted on hyperspectral image data sets. The SS-GANS performed slightly better than supervised GANS on classification problems with and without the SOM. Incorporating the SOMs into the SS-GANs and the supervised GANS led to substantially mitigation of the DOIC problem when compared to SS-GANS and GANs without the SOMs. Furthermore, the SS-GANS performed much better than GANS on the DOIC problem, even without the SOMs.
Outlier Detection through Null Space Analysis of Neural Networks
Jul 02, 2020
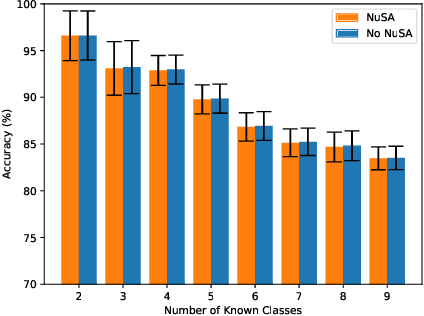
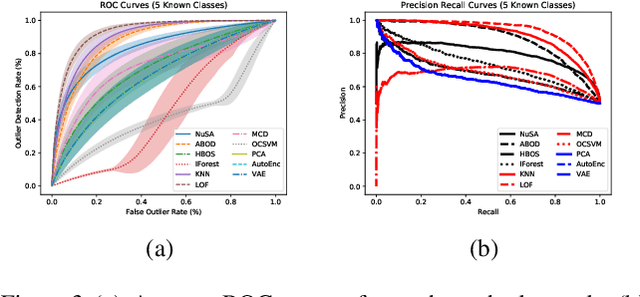
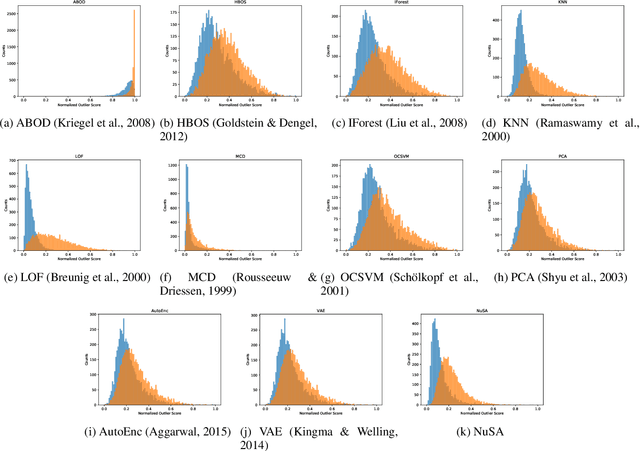
Many machine learning classification systems lack competency awareness. Specifically, many systems lack the ability to identify when outliers (e.g., samples that are distinct from and not represented in the training data distribution) are being presented to the system. The ability to detect outliers is of practical significance since it can help the system behave in an reasonable way when encountering unexpected data. In prior work, outlier detection is commonly carried out in a processing pipeline that is distinct from the classification model. Thus, for a complete system that incorporates outlier detection and classification, two models must be trained, increasing the overall complexity of the approach. In this paper we use the concept of the null space to integrate an outlier detection method directly into a neural network used for classification. Our method, called Null Space Analysis (NuSA) of neural networks, works by computing and controlling the magnitude of the null space projection as data is passed through a network. Using these projections, we can then calculate a score that can differentiate between normal and abnormal data. Results are shown that indicate networks trained with NuSA retain their classification performance while also being able to detect outliers at rates similar to commonly used outlier detection algorithms.
Multi-Target Multiple Instance Learning for Hyperspectral Target Detection
Sep 07, 2019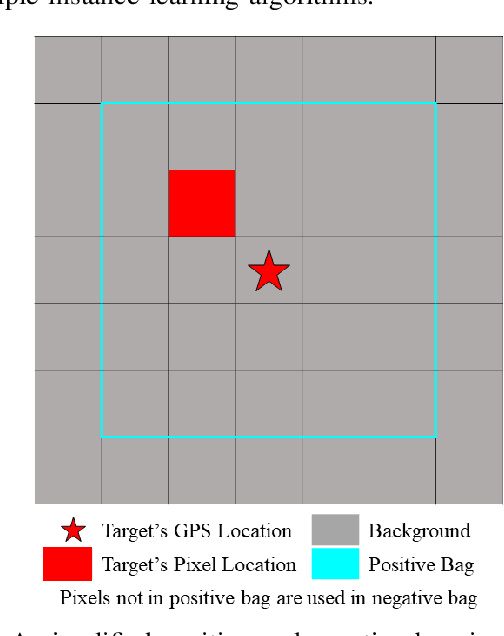
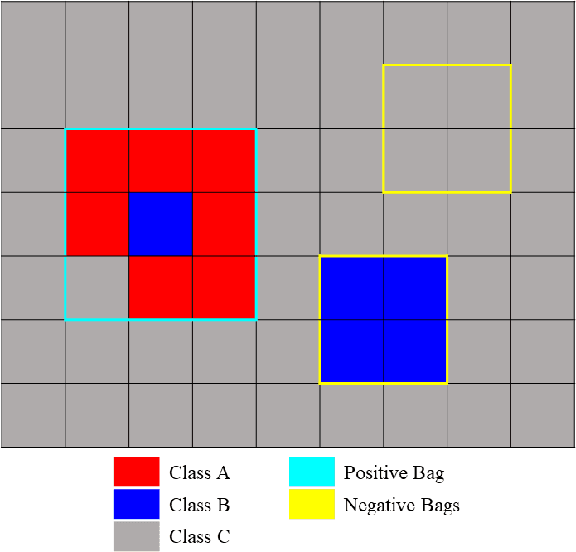
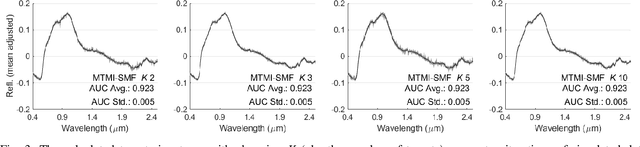
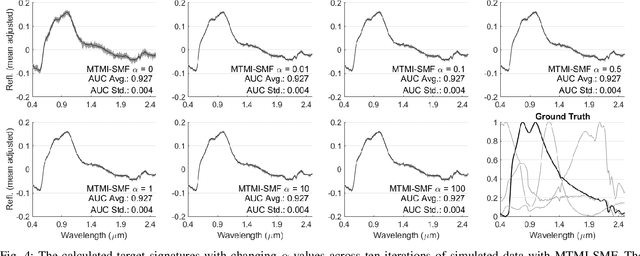
In remote sensing, it is often difficult to acquire or collect a large dataset that is accurately labeled. This difficulty is often due to several issues including but not limited to the study site's spatial area and accessibility, errors in global positioning system (GPS), and mixed pixels caused by an image's spatial resolution. An approach, with two variations, is proposed that estimates multiple target signatures from mixed training samples with imprecise labels: Multi-Target Multiple Instance Adaptive Cosine Estimator (Multi-Target MI-ACE) and Multi-Target Multiple Instance Spectral Match Filter (Multi-Target MI-SMF). The proposed methods address the problems above by directly considering the multiple-instance, imprecisely labeled dataset and learns a dictionary of target signatures that optimizes detection using the Adaptive Cosine Estimator (ACE) and Spectral Match Filter (SMF) against a background. The algorithms have two primary steps, initialization and optimization. The initialization process determines diverse target representatives, while the optimization process simultaneously updates the target representatives to maximize detection while learning the number of optimal signatures to describe the target class. Three designed experiments were done to test the proposed algorithms: a simulated hyperspectral dataset, the MUUFL Gulfport hyperspectral dataset collected over the University of Southern Mississippi-Gulfpark Campus, and the AVIRIS hyperspectral dataset collected over Santa Barbara County, California. Both simulated and real hyperspectral target detection experiments show the proposed algorithms are effective at learning target signatures and performing target detection.
A spatial compositional model (SCM) for linear unmixing and endmember uncertainty estimation
Sep 30, 2015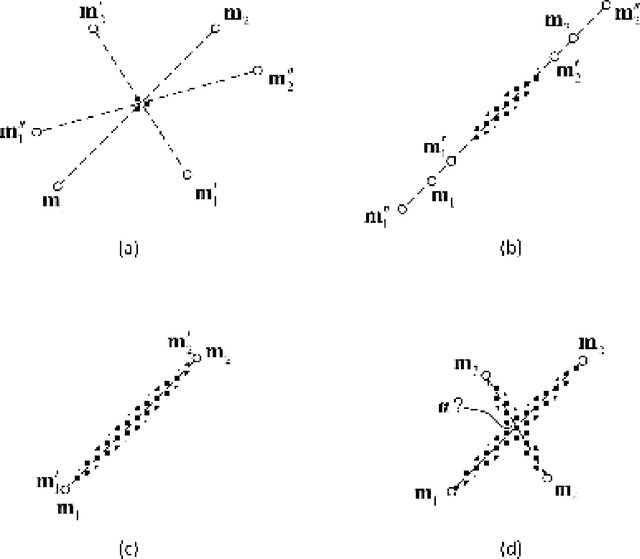
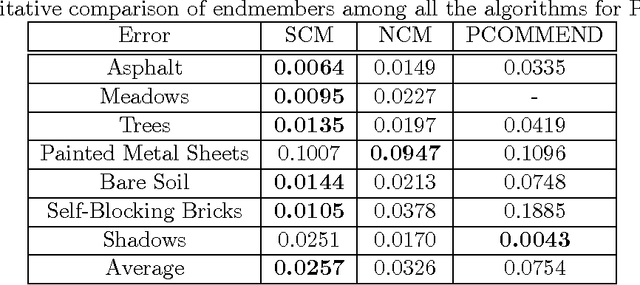
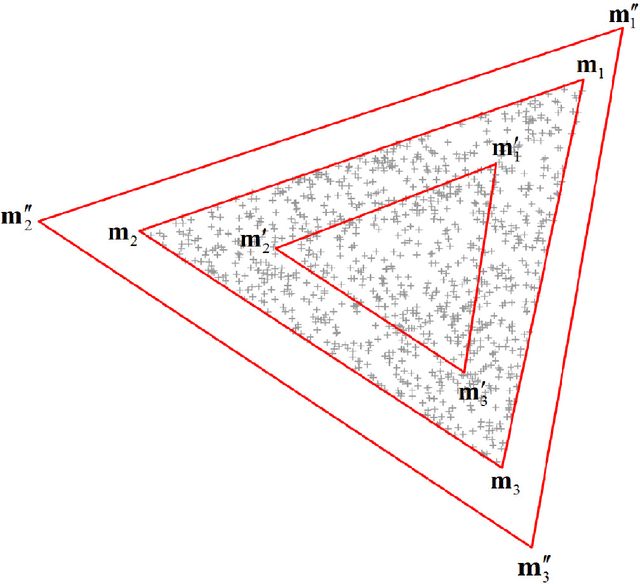
The normal compositional model (NCM) has been extensively used in hyperspectral unmixing. However, most of the previous research has focused on estimation of endmembers and/or their variability. Also, little work has employed spatial information in NCM. In this paper, we show that NCM can be used for calculating the uncertainty of the estimated endmembers with spatial priors incorporated for better unmixing. This results in a spatial compositional model (SCM) which features (i) spatial priors that force neighboring abundances to be similar based on their pixel similarity and (ii) a posterior that is obtained from a likelihood model which does not assume pixel independence. The resulting algorithm turns out to be easy to implement and efficient to run. We compared SCM with current state-of-the-art algorithms on synthetic and real images. The results show that SCM can in the main provide more accurate endmembers and abundances. Moreover, the estimated uncertainty can serve as a prediction of endmember error under certain conditions.
Hyperspectral Unmixing Overview: Geometrical, Statistical, and Sparse Regression-Based Approaches
Apr 24, 2012
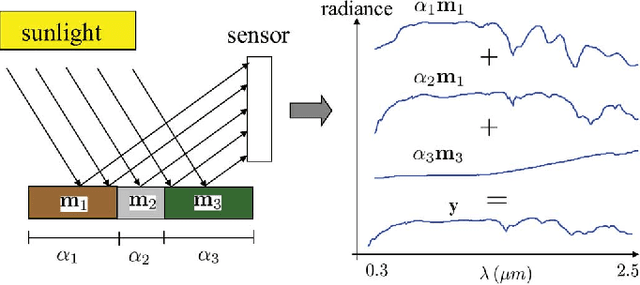
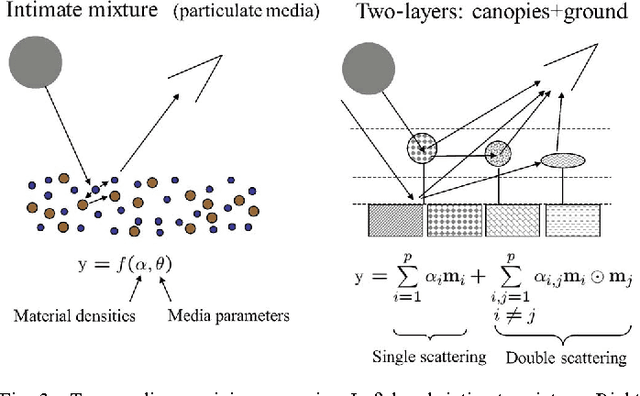
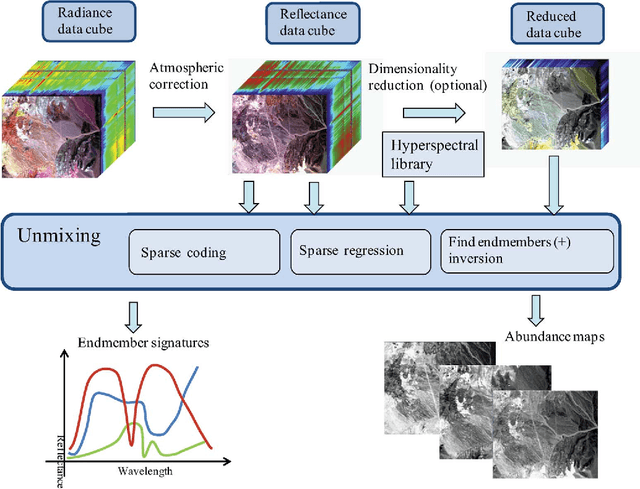
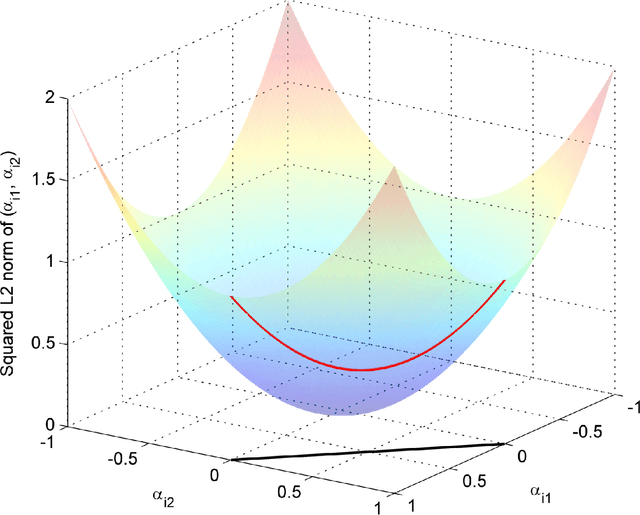
Imaging spectrometers measure electromagnetic energy scattered in their instantaneous field view in hundreds or thousands of spectral channels with higher spectral resolution than multispectral cameras. Imaging spectrometers are therefore often referred to as hyperspectral cameras (HSCs). Higher spectral resolution enables material identification via spectroscopic analysis, which facilitates countless applications that require identifying materials in scenarios unsuitable for classical spectroscopic analysis. Due to low spatial resolution of HSCs, microscopic material mixing, and multiple scattering, spectra measured by HSCs are mixtures of spectra of materials in a scene. Thus, accurate estimation requires unmixing. Pixels are assumed to be mixtures of a few materials, called endmembers. Unmixing involves estimating all or some of: the number of endmembers, their spectral signatures, and their abundances at each pixel. Unmixing is a challenging, ill-posed inverse problem because of model inaccuracies, observation noise, environmental conditions, endmember variability, and data set size. Researchers have devised and investigated many models searching for robust, stable, tractable, and accurate unmixing algorithms. This paper presents an overview of unmixing methods from the time of Keshava and Mustard's unmixing tutorial [1] to the present. Mixing models are first discussed. Signal-subspace, geometrical, statistical, sparsity-based, and spatial-contextual unmixing algorithms are described. Mathematical problems and potential solutions are described. Algorithm characteristics are illustrated experimentally.