 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePDRs4All XX. Haute Couture: Spectral stitching of JWST MIRI-IFU cubes with matrix completion
Nov 17, 2025MIRI is the imager and spectrograph covering wavelengths from $4.9$ to $27.9$ $μ$m onboard the James Webb Space Telescope (JWST). The Medium-Resolution Spectrometer (MRS) consists of four integral field units (IFU), each of which has three sub-channels. The twelve resulting spectral data cubes have different fields of view, spatial, and spectral resolutions. The wavelength range of each cube partially overlaps with the neighboring bands, and the overlap regions typically show flux mismatches which have to be corrected by spectral stitching methods. Stitching methods aim to produce a single data cube incorporating the data of the individual sub-channels, which requires matching the spatial resolution and the flux discrepancies. We present Haute Couture, a novel stitching algorithm which uses non-negative matrix factorization (NMF) to perform a matrix completion, where the available MRS data cubes are treated as twelve sub-matrices of a larger incomplete matrix. Prior to matrix completion, we also introduce a novel pre-processing to homogenize the global intensities of the twelve cubes. Our pre-processing consists in jointly optimizing a set of global scale parameters that maximize the fit between the cubes where spectral overlap occurs. We apply our novel stitching method to JWST data obtained as part of the PDRs4All observing program of the Orion Bar, and produce a uniform cube reconstructed with the best spatial resolution over the full range of wavelengths.
Bregman geometry-aware split Gibbs sampling for Bayesian Poisson inverse problems
Nov 15, 2025This paper proposes a novel Bayesian framework for solving Poisson inverse problems by devising a Monte Carlo sampling algorithm which accounts for the underlying non-Euclidean geometry. To address the challenges posed by the Poisson likelihood -- such as non-Lipschitz gradients and positivity constraints -- we derive a Bayesian model which leverages exact and asymptotically exact data augmentations. In particular, the augmented model incorporates two sets of splitting variables both derived through a Bregman divergence based on the Burg entropy. Interestingly the resulting augmented posterior distribution is characterized by conditional distributions which benefit from natural conjugacy properties and preserve the intrinsic geometry of the latent and splitting variables. This allows for efficient sampling via Gibbs steps, which can be performed explicitly for all conditionals, except the one incorporating the regularization potential. For this latter, we resort to a Hessian Riemannian Langevin Monte Carlo (HRLMC) algorithm which is well suited to handle priors with explicit or easily computable score functions. By operating on a mirror manifold, this Langevin step ensures that the sampling satisfies the positivity constraints and more accurately reflects the underlying problem structure. Performance results obtained on denoising, deblurring, and positron emission tomography (PET) experiments demonstrate that the method achieves competitive performance in terms of reconstruction quality compared to optimization- and sampling-based approaches.
Determined blind source separation via modeling adjacent frequency band correlations in speech signals
Apr 05, 2025Multichannel blind source separation (MBSS), which focuses on separating signals of interest from mixed observations, has been extensively studied in acoustic and speech processing. Existing MBSS algorithms, such as independent low-rank matrix analysis (ILRMA) and multichannel nonnegative matrix factorization (MNMF), utilize the low-rank structure of source models but assume that frequency bins are independent. In contrast, independent vector analysis (IVA) does not rely on a low-rank source model but rather captures frequency dependencies based on a uniform correlation assumption. In this work, we demonstrate that dependencies between adjacent frequency bins are significantly stronger than those between bins that are farther apart in typical speech signals. To address this, we introduce a weighted Sinkhorn divergence-based ILRMA (wsILRMA) that simultaneously captures these inter-frequency dependencies and models joint probability distributions. Our approach incorporates an inter-frequency correlation constraint, leading to improved source separation performance compared to existing methods, as evidenced by higher Signal-to-Distortion Ratios (SDRs) and Source-to-Interference Ratios (SIRs).
Joint Tensor and Inter-View Low-Rank Recovery for Incomplete Multiview Clustering
Mar 04, 2025



Incomplete multiview clustering (IMVC) has gained significant attention for its effectiveness in handling missing sample challenges across various views in real-world multiview clustering applications. Most IMVC approaches tackle this problem by either learning consensus representations from available views or reconstructing missing samples using the underlying manifold structure. However, the reconstruction of learned similarity graph tensor in prior studies only exploits the low-tubal-rank information, neglecting the exploration of inter-view correlations. This paper propose a novel joint tensor and inter-view low-rank Recovery (JTIV-LRR), framing IMVC as a joint optimization problem that integrates incomplete similarity graph learning and tensor representation recovery. By leveraging both intra-view and inter-view low rank information, the method achieves robust estimation of the complete similarity graph tensor through sparse noise removal and low-tubal-rank constraints along different modes. Extensive experiments on both synthetic and real-world datasets demonstrate the superiority of the proposed approach, achieving significant improvements in clustering accuracy and robustness compared to state-of-the-art methods.
Determined Blind Source Separation with Sinkhorn Divergence-based Optimal Allocation of the Source Power
Feb 25, 2025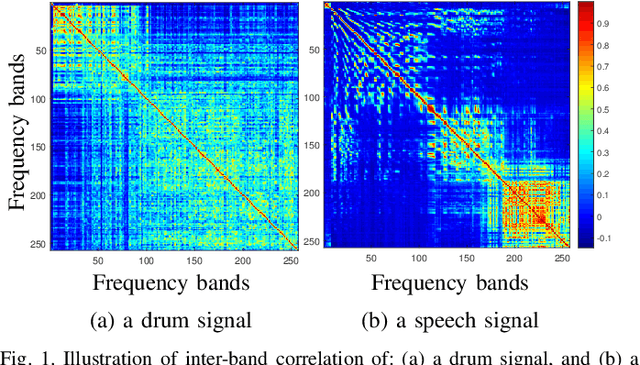
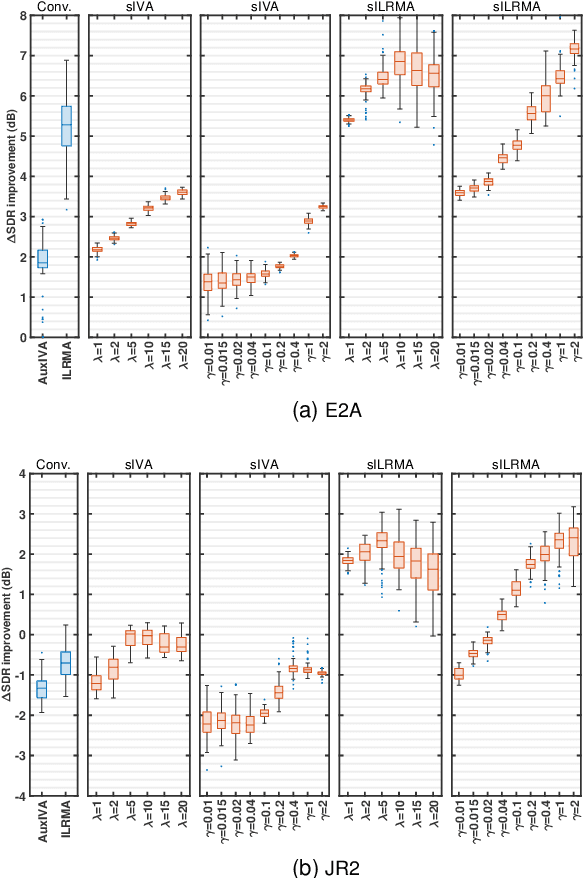
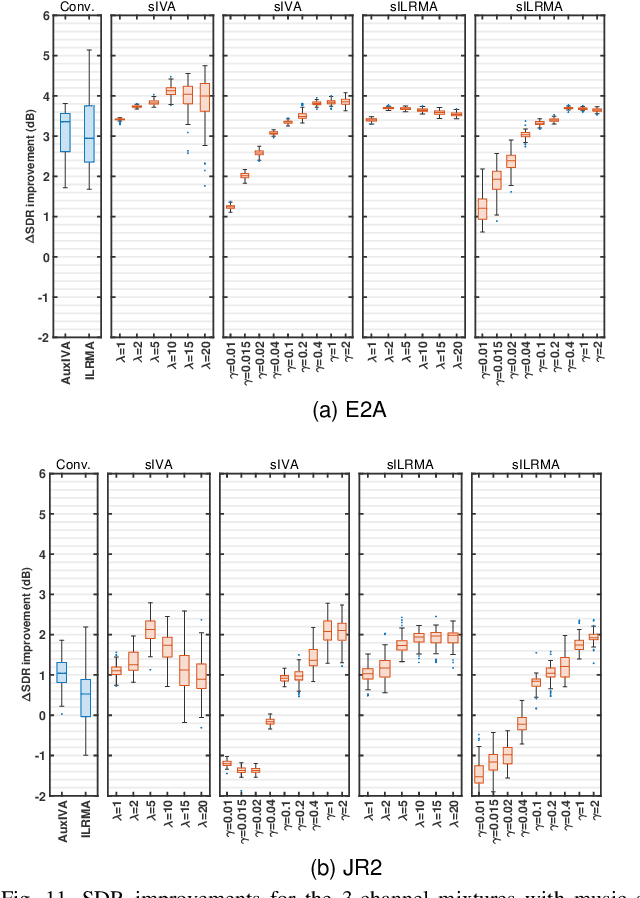
Blind source separation (BSS) refers to the process of recovering multiple source signals from observations recorded by an array of sensors. Common approaches to BSS, including independent vector analysis (IVA), and independent low-rank matrix analysis (ILRMA), typically rely on second-order models to capture the statistical independence of source signals for separation. However, these methods generally do not account for the implicit structural information across frequency bands, which may lead to model mismatches between the assumed source distributions and the distributions of the separated source signals estimated from the observed mixtures. To tackle these limitations, this paper shows that conventional approaches such as IVA and ILRMA can easily be leveraged by the Sinkhorn divergence, incorporating an optimal transport (OT) framework to adaptively correct source variance estimates. This allows for the recovery of the source distribution while modeling the inter-band signal dependence and reallocating source power across bands. As a result, enhanced versions of these algorithms are developed, integrating a Sinkhorn iterative scheme into their standard implementations. Extensive simulations demonstrate that the proposed methods consistently enhance BSS performance.
On-the-fly spectral unmixing based on Kalman filtering
Jul 22, 2024
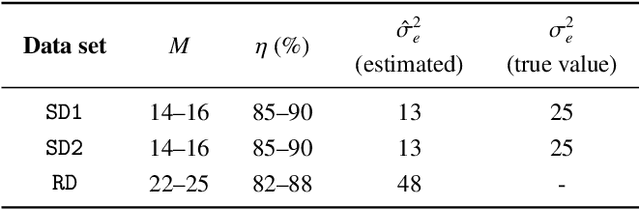
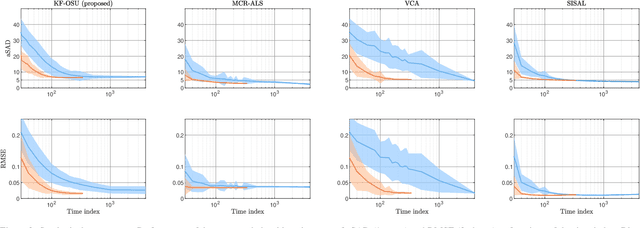
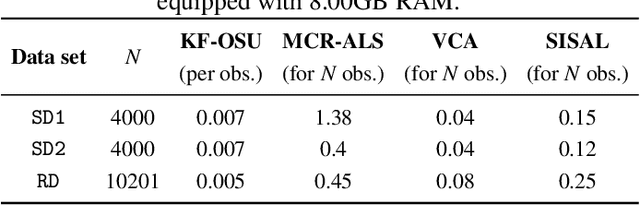
This work introduces an on-the-fly (i.e., online) linear unmixing method which is able to sequentially analyze spectral data acquired on a spectrum-by-spectrum basis. After deriving a sequential counterpart of the conventional linear mixing model, the proposed approach recasts the linear unmixing problem into a linear state-space estimation framework. Under Gaussian noise and state models, the estimation of the pure spectra can be efficiently conducted by resorting to Kalman filtering. Interestingly, it is shown that this Kalman filter can operate in a lower-dimensional subspace while ensuring the nonnegativity constraint inherent to pure spectra. This dimensionality reduction allows significantly lightening the computational burden, while leveraging recent advances related to the representation of essential spectral information. The proposed method is evaluated through extensive numerical experiments conducted on synthetic and real Raman data sets. The results show that this Kalman filter-based method offers a convenient trade-off between unmixing accuracy and computational efficiency, which is crucial for operating in an on-the-fly setting. To the best of the authors' knowledge, this is the first operational method which is able to solve the spectral unmixing problem efficiently in a dynamic fashion. It also constitutes a valuable building block for benefiting from acquisition and processing frameworks recently proposed in the microscopy literature, which are motivated by practical issues such as reducing acquisition time and avoiding potential damages being inflicted to photosensitive samples.
RFI-DRUnet: Restoring dynamic spectra corrupted by radio frequency interference -- Application to pulsar observations
Feb 21, 2024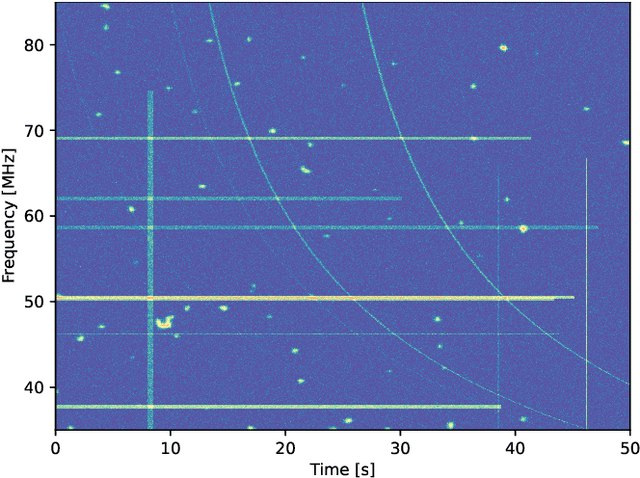


Radio frequency interference (RFI) have been an enduring concern in radio astronomy, particularly for the observations of pulsars which require high timing precision and data sensitivity. In most works of the literature, RFI mitigation has been formulated as a detection task that consists of localizing possible RFI in dynamic spectra. This strategy inevitably leads to a potential loss of information since parts of the signal identified as possibly RFI-corrupted are generally not considered in the subsequent data processing pipeline. Conversely, this work proposes to tackle RFI mitigation as a joint detection and restoration that allows parts of the dynamic spectrum affected by RFI to be not only identified but also recovered. The proposed supervised method relies on a deep convolutional network whose architecture inherits the performance reached by a recent yet popular image-denoising network. To train this network, a whole simulation framework is built to generate large data sets according to physics-inspired and statistical models of the pulsar signals and of the RFI. The relevance of the proposed approach is quantitatively assessed by conducting extensive experiments. In particular, the results show that the restored dynamic spectra are sufficiently reliable to estimate pulsar times-of-arrivals with an accuracy close to the one that would be obtained from RFI-free signals.
Regularization by denoising: Bayesian model and Langevin-within-split Gibbs sampling
Feb 19, 2024This paper introduces a Bayesian framework for image inversion by deriving a probabilistic counterpart to the regularization-by-denoising (RED) paradigm. It additionally implements a Monte Carlo algorithm specifically tailored for sampling from the resulting posterior distribution, based on an asymptotically exact data augmentation (AXDA). The proposed algorithm is an approximate instance of split Gibbs sampling (SGS) which embeds one Langevin Monte Carlo step. The proposed method is applied to common imaging tasks such as deblurring, inpainting and super-resolution, demonstrating its efficacy through extensive numerical experiments. These contributions advance Bayesian inference in imaging by leveraging data-driven regularization strategies within a probabilistic framework.
AE-RED: A Hyperspectral Unmixing Framework Powered by Deep Autoencoder and Regularization by Denoising
Jul 01, 2023



Spectral unmixing has been extensively studied with a variety of methods and used in many applications. Recently, data-driven techniques with deep learning methods have obtained great attention to spectral unmixing for its superior learning ability to automatically learn the structure information. In particular, autoencoder based architectures are elaborately designed to solve blind unmixing and model complex nonlinear mixtures. Nevertheless, these methods perform unmixing task as blackboxes and lack of interpretability. On the other hand, conventional unmixing methods carefully design the regularizer to add explicit information, in which algorithms such as plug-and-play (PnP) strategies utilize off-the-shelf denoisers to plug powerful priors. In this paper, we propose a generic unmixing framework to integrate the autoencoder network with regularization by denoising (RED), named AE-RED. More specially, we decompose the unmixing optimized problem into two subproblems. The first one is solved using deep autoencoders to implicitly regularize the estimates and model the mixture mechanism. The second one leverages the denoiser to bring in the explicit information. In this way, both the characteristics of the deep autoencoder based unmixing methods and priors provided by denoisers are merged into our well-designed framework to enhance the unmixing performance. Experiment results on both synthetic and real data sets show the superiority of our proposed framework compared with state-of-the-art unmixing approaches.
Guided Deep Generative Model-based Spatial Regularization for Multiband Imaging Inverse Problems
Jun 29, 2023

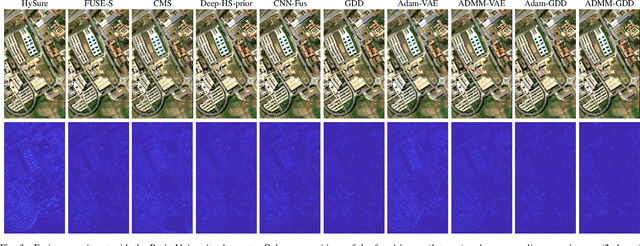

When adopting a model-based formulation, solving inverse problems encountered in multiband imaging requires to define spatial and spectral regularizations. In most of the works of the literature, spectral information is extracted from the observations directly to derive data-driven spectral priors. Conversely, the choice of the spatial regularization often boils down to the use of conventional penalizations (e.g., total variation) promoting expected features of the reconstructed image (e.g., piecewise constant). In this work, we propose a generic framework able to capitalize on an auxiliary acquisition of high spatial resolution to derive tailored data-driven spatial regularizations. This approach leverages on the ability of deep learning to extract high level features. More precisely, the regularization is conceived as a deep generative network able to encode spatial semantic features contained in this auxiliary image of high spatial resolution. To illustrate the versatility of this approach, it is instantiated to conduct two particular tasks, namely multiband image fusion and multiband image inpainting. Experimental results obtained on these two tasks demonstrate the benefit of this class of informed regularizations when compared to more conventional ones.