 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetermined blind source separation via modeling adjacent frequency band correlations in speech signals
Apr 05, 2025Multichannel blind source separation (MBSS), which focuses on separating signals of interest from mixed observations, has been extensively studied in acoustic and speech processing. Existing MBSS algorithms, such as independent low-rank matrix analysis (ILRMA) and multichannel nonnegative matrix factorization (MNMF), utilize the low-rank structure of source models but assume that frequency bins are independent. In contrast, independent vector analysis (IVA) does not rely on a low-rank source model but rather captures frequency dependencies based on a uniform correlation assumption. In this work, we demonstrate that dependencies between adjacent frequency bins are significantly stronger than those between bins that are farther apart in typical speech signals. To address this, we introduce a weighted Sinkhorn divergence-based ILRMA (wsILRMA) that simultaneously captures these inter-frequency dependencies and models joint probability distributions. Our approach incorporates an inter-frequency correlation constraint, leading to improved source separation performance compared to existing methods, as evidenced by higher Signal-to-Distortion Ratios (SDRs) and Source-to-Interference Ratios (SIRs).
Determined Blind Source Separation with Sinkhorn Divergence-based Optimal Allocation of the Source Power
Feb 25, 2025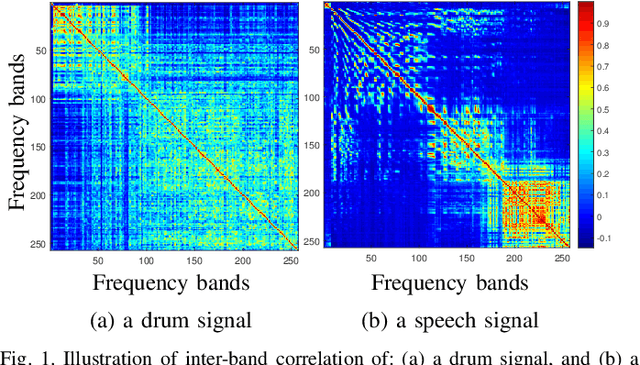
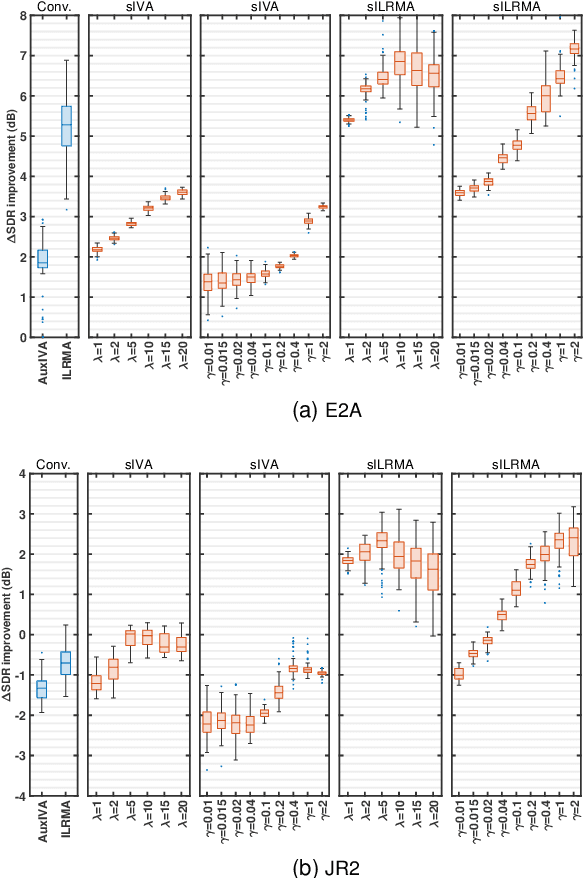
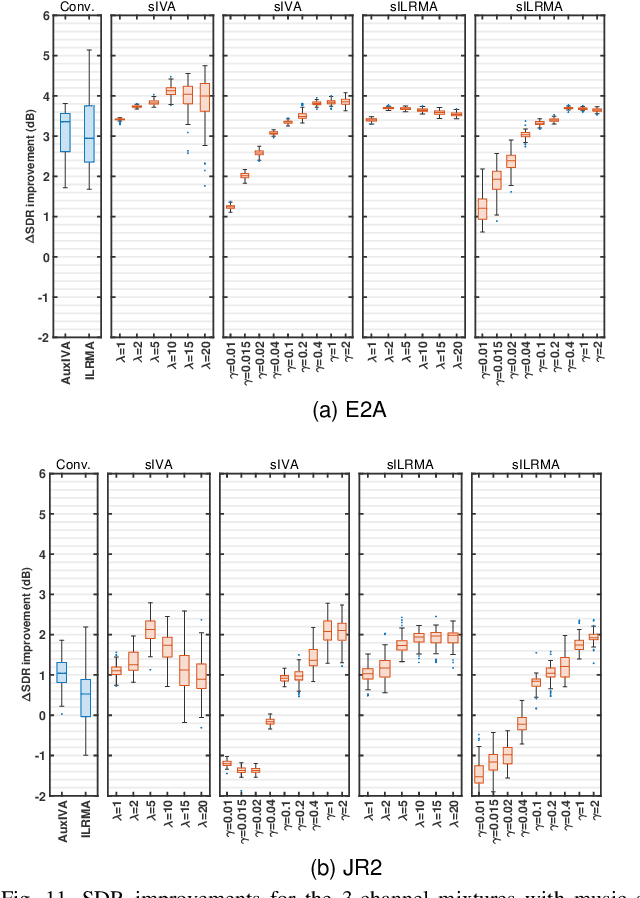
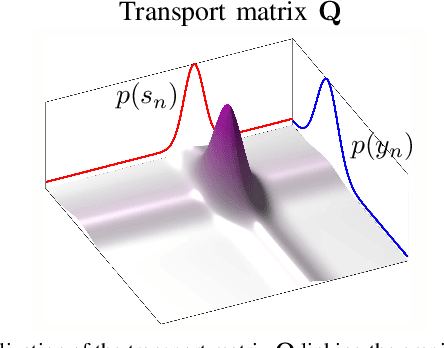
Blind source separation (BSS) refers to the process of recovering multiple source signals from observations recorded by an array of sensors. Common approaches to BSS, including independent vector analysis (IVA), and independent low-rank matrix analysis (ILRMA), typically rely on second-order models to capture the statistical independence of source signals for separation. However, these methods generally do not account for the implicit structural information across frequency bands, which may lead to model mismatches between the assumed source distributions and the distributions of the separated source signals estimated from the observed mixtures. To tackle these limitations, this paper shows that conventional approaches such as IVA and ILRMA can easily be leveraged by the Sinkhorn divergence, incorporating an optimal transport (OT) framework to adaptively correct source variance estimates. This allows for the recovery of the source distribution while modeling the inter-band signal dependence and reallocating source power across bands. As a result, enhanced versions of these algorithms are developed, integrating a Sinkhorn iterative scheme into their standard implementations. Extensive simulations demonstrate that the proposed methods consistently enhance BSS performance.
Determined Multichannel Blind Source Separation with Clustered Source Model
May 06, 2024



The independent low-rank matrix analysis (ILRMA) method stands out as a prominent technique for multichannel blind audio source separation. It leverages nonnegative matrix factorization (NMF) and nonnegative canonical polyadic decomposition (NCPD) to model source parameters. While it effectively captures the low-rank structure of sources, the NMF model overlooks inter-channel dependencies. On the other hand, NCPD preserves intrinsic structure but lacks interpretable latent factors, making it challenging to incorporate prior information as constraints. To address these limitations, we introduce a clustered source model based on nonnegative block-term decomposition (NBTD). This model defines blocks as outer products of vectors (clusters) and matrices (for spectral structure modeling), offering interpretable latent vectors. Moreover, it enables straightforward integration of orthogonality constraints to ensure independence among source images. Experimental results demonstrate that our proposed method outperforms ILRMA and its extensions in anechoic conditions and surpasses the original ILRMA in simulated reverberant environments.
Multichannel blind speech source separation with a disjoint constraint source model
Jan 03, 2024Multichannel convolutive blind speech source separation refers to the problem of separating different speech sources from the observed multichannel mixtures without much a priori information about the mixing system. Multichannel nonnegative matrix factorization (MNMF) has been proven to be one of the most powerful separation frameworks and the representative algorithms such as MNMF and the independent low-rank matrix analysis (ILRMA) have demonstrated great performance. However, the sparseness properties of speech source signals are not fully taken into account in such a framework. It is well known that speech signals are sparse in nature, which is considered in this work to improve the separation performance. Specifically, we utilize the Bingham and Laplace distributions to formulate a disjoint constraint regularizer, which is subsequently incorporated into both MNMF and ILRMA. We then derive majorization-minimization rules for updating parameters related to the source model, resulting in the development of two enhanced algorithms: s-MNMF and s-ILRMA. Comprehensive simulations are conducted, and the results unequivocally demonstrate the efficacy of our proposed methodologies.
Independent low-rank matrix analysis based on the Sinkhorn divergence source model for blind source separation
Jan 03, 2024

The so-called independent low-rank matrix analysis (ILRMA) has demonstrated a great potential for dealing with the problem of determined blind source separation (BSS) for audio and speech signals. This method assumes that the spectra from different frequency bands are independent and the spectral coefficients in any frequency band are Gaussian distributed. The Itakura-Saito divergence is then employed to estimate the source model related parameters. In reality, however, the spectral coefficients from different frequency bands may be dependent, which is not considered in the existing ILRMA algorithm. This paper presents an improved version of ILRMA, which considers the dependency between the spectral coefficients from different frequency bands. The Sinkhorn divergence is then exploited to optimize the source model parameters. As a result of using the cross-band information, the BSS performance is improved. But the number of parameters to be estimated also increases significantly, and so is the computational complexity. To reduce the algorithm complexity, we apply the Kronecker product to decompose the modeling matrix into the product of a number of matrices of much smaller dimensionality. An efficient algorithm is then developed to implement the Sinkhorn divergence based BSS algorithm and the complexity is reduced by an order of magnitude.
Attention-based multi-channel speaker verification with ad-hoc microphone arrays
Jul 01, 2021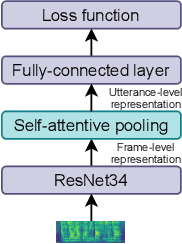
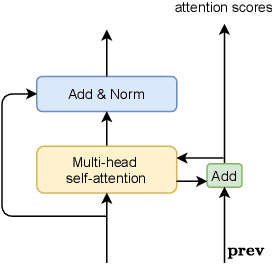
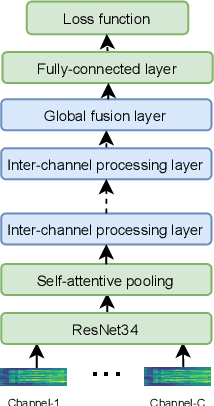
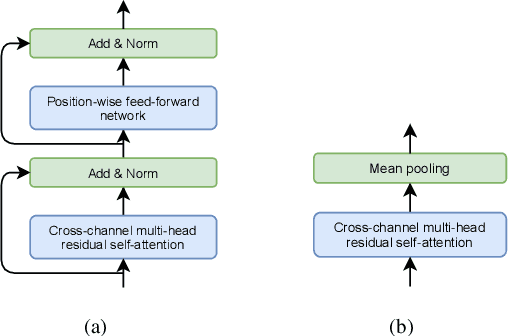
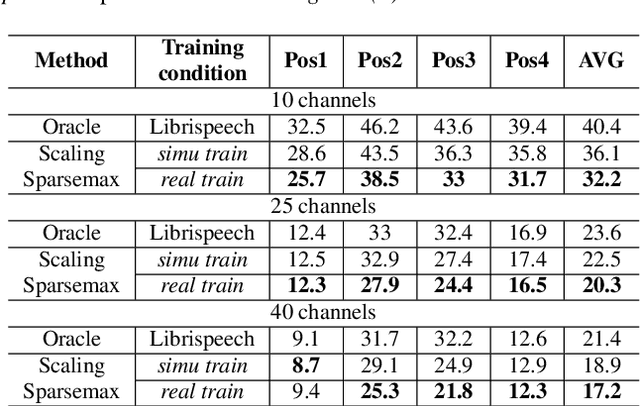
Recently, ad-hoc microphone array has been widely studied. Unlike traditional microphone array settings, the spatial arrangement and number of microphones of ad-hoc microphone arrays are not known in advance, which hinders the adaptation of traditional speaker verification technologies to ad-hoc microphone arrays. To overcome this weakness, in this paper, we propose attention-based multi-channel speaker verification with ad-hoc microphone arrays. Specifically, we add an inter-channel processing layer and a global fusion layer after the pooling layer of a single-channel speaker verification system. The inter-channel processing layer applies a so-called residual self-attention along the channel dimension for allocating weights to different microphones. The global fusion layer integrates all channels in a way that is independent to the number of the input channels. We further replace the softmax operator in the residual self-attention with sparsemax, which forces the channel weights of very noisy channels to zero. Experimental results with ad-hoc microphone arrays of over 30 channels demonstrate the effectiveness of the proposed methods. For example, the multi-channel speaker verification with sparsemax achieves an equal error rate (EER) of over 20% lower than oracle one-best system on semi-real data sets, and over 30% lower on simulation data sets, in test scenarios with both matched and mismatched channel numbers.
Libri-adhoc40: A dataset collected from synchronized ad-hoc microphone arrays
Apr 07, 2021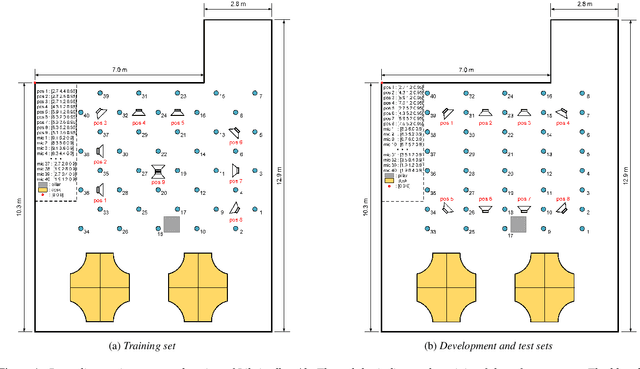
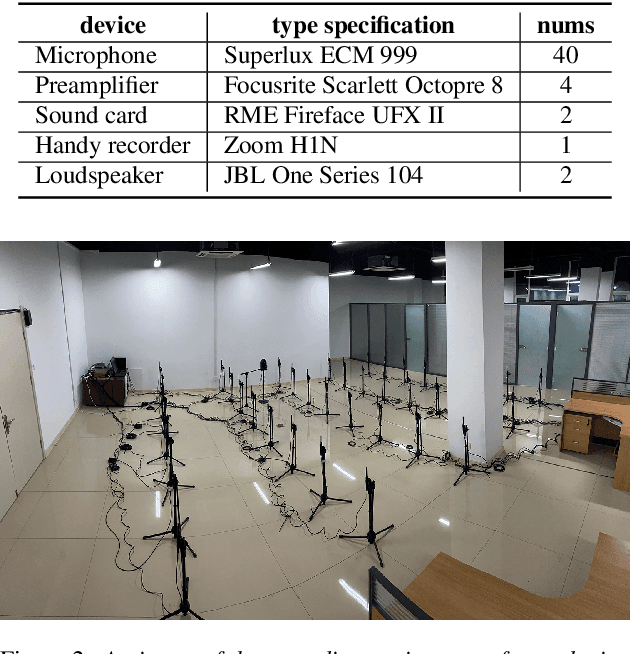

Recently, there is a research trend on ad-hoc microphone arrays. However, most research was conducted on simulated data. Although some data sets were collected with a small number of distributed devices, they were not synchronized which hinders the fundamental theoretical research to ad-hoc microphone arrays. To address this issue, this paper presents a synchronized speech corpus, named Libri-adhoc40, which collects the replayed Librispeech data from loudspeakers by ad-hoc microphone arrays of 40 strongly synchronized distributed nodes in a real office environment. Besides, to provide the evaluation target for speech frontend processing and other applications, we also recorded the replayed speech in an anechoic chamber. We trained several multi-device speech recognition systems on both the Libri-adhoc40 dataset and a simulated dataset. Experimental results demonstrate the validness of the proposed corpus which can be used as a benchmark to reflect the trend and difference of the models with different ad-hoc microphone arrays. The dataset is online available at https://github.com/ISmallFish/Libri-adhoc40.
Minimum-volume Multichannel Nonnegative matrix factorization for blind source separation
Jan 16, 2021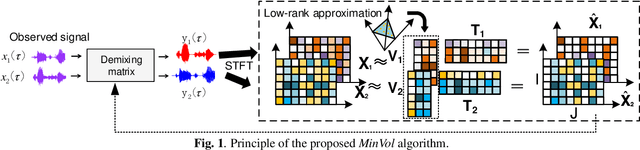
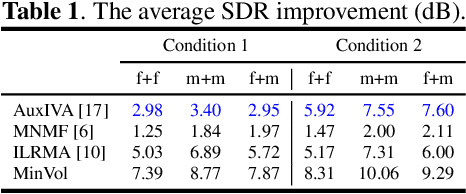
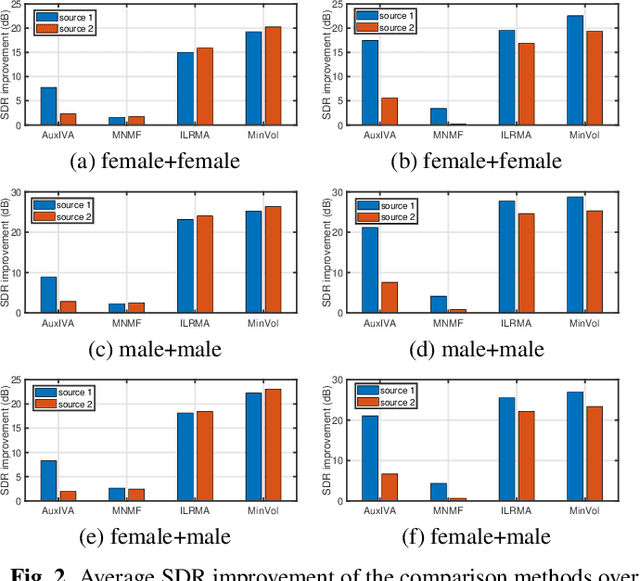
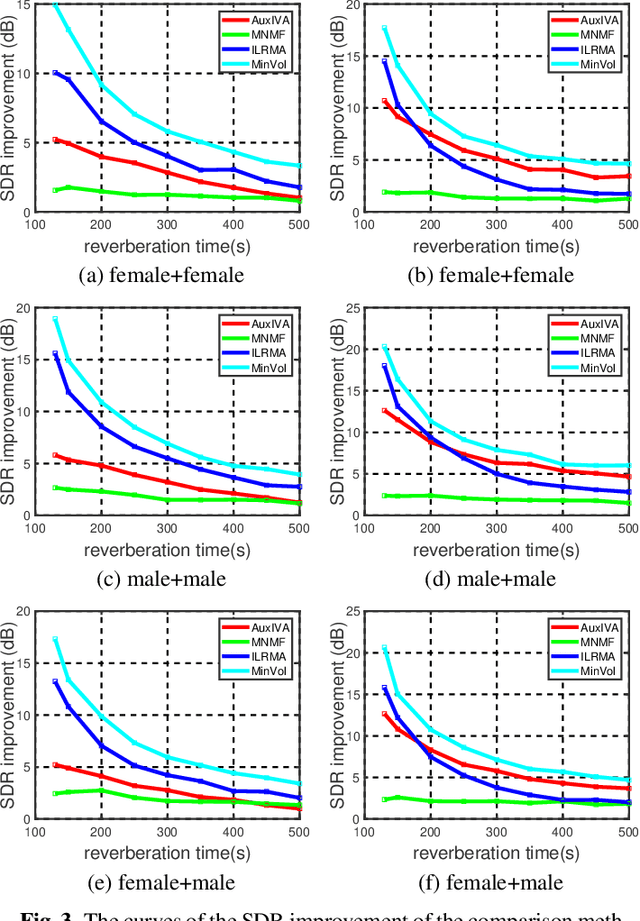
Multichannel blind source separation aims to recover the latent sources from their multichannel mixture without priors. A state-of-art blind source separation method called independent low-rank matrix analysis (ILRMA) unified independent vector analysis (IVA) and nonnegative matrix factorization (NMF). However, speech spectra modeled by NMF may not find a compact representation and it may not guarantee that each source is identifiable. To address the problem, here we propose a modified blind source separation method that enhances the identifiability of the source model. It combines ILRMA with penalty item of volume constraint. The proposed method is optimized by standard majorization-minimization framework based multiplication updating rule, which ensures the stability of convergence. Experimental results demonstrate the effectiveness of the proposed method compared with AuxIVA, MNMF and ILRMA.
Deep Ad-hoc Beamforming Based on Speaker Extraction for Target-Dependent Speech Separation
Dec 01, 2020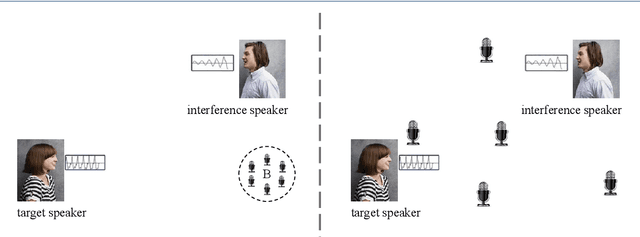
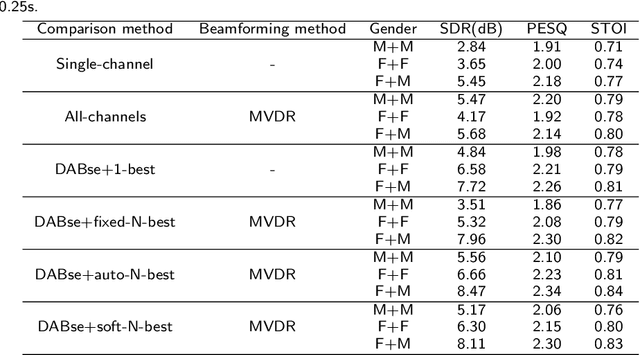
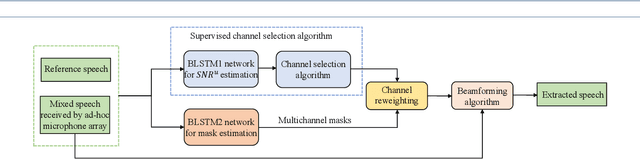
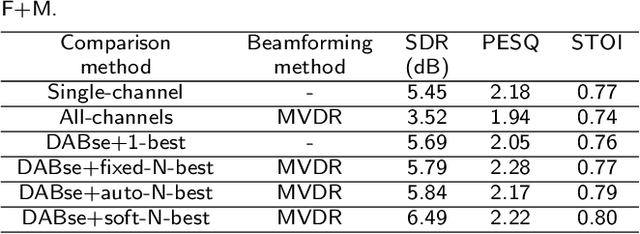
Recently, the research on ad-hoc microphone arrays with deep learning has drawn much attention, especially in speech enhancement and separation. Because an ad-hoc microphone array may cover such a large area that multiple speakers may locate far apart and talk independently, target-dependent speech separation, which aims to extract a target speaker from a mixed speech, is important for extracting and tracing a specific speaker in the ad-hoc array. However, this technique has not been explored yet. In this paper, we propose deep ad-hoc beamforming based on speaker extraction, which is to our knowledge the first work for target-dependent speech separation based on ad-hoc microphone arrays and deep learning. The algorithm contains three components. First, we propose a supervised channel selection framework based on speaker extraction, where the estimated utterance-level SNRs of the target speech are used as the basis for the channel selection. Second, we apply the selected channels to a deep learning based MVDR algorithm, where a single-channel speaker extraction algorithm is applied to each selected channel for estimating the mask of the target speech. We conducted an extensive experiment on a WSJ0-adhoc corpus. Experimental results demonstrate the effectiveness of the proposed method.