 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning Based Two-dimensional Speaker Localization With Large Ad-hoc Microphone Arrays
Oct 19, 2022
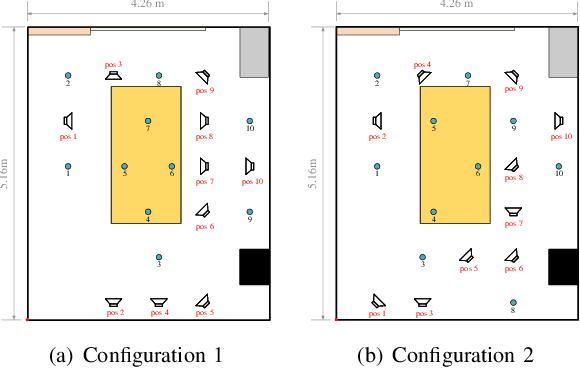
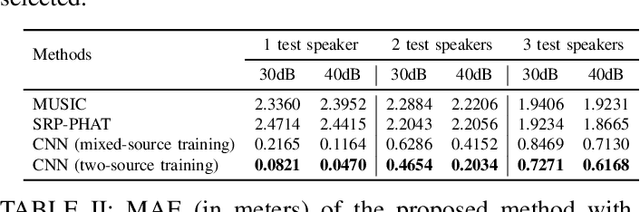
Deep learning based speaker localization has shown its advantage in reverberant scenarios. However, it mostly focuses on the direction-of-arrival (DOA) estimation subtask of speaker localization, where the DOA instead of the 2-dimensional (2D) coordinates is obtained only. To obtain the 2D coordinates of multiple speakers with random positions, this paper proposes a deep-learning-based 2D speaker localization method with large ad-hoc microphone arrays, where an ad-hoc microphone array is a set of randomly-distributed microphone nodes with each node set to a traditional microphone array, e.g. a linear array. Specifically, a convolutional neural network is applied to each node to get the direction-of-arrival (DOA) estimation of speech sources. Then, a triangulation and clustering method integrates the DOA estimations of the nodes for estimating the 2D positions of the speech sources. To further improve the estimation accuracy, we propose a softmax-based node selection algorithm. Experimental results with large-scale ad-hoc microphone arrays show that the proposed method achieves significantly better performance than conventional methods in both simulated and real-world environments. The softmax-based node selection further improves the performance.
End-to-end Two-dimensional Sound Source Localization With Ad-hoc Microphone Arrays
Oct 16, 2022Conventional sound source localization methods are mostly based on a single microphone array that consists of multiple microphones. They are usually formulated as the estimation of the direction of arrival problem. In this paper, we propose a deep-learning-based end-to-end sound source localization method with ad-hoc microphone arrays, where an ad-hoc microphone array is a set of randomly distributed microphone arrays that collaborate with each other. It can produce two-dimensional locations of speakers with only a single microphone per node. Specifically, we divide a targeted indoor space into multiple local areas. We encode each local area by a one-hot code, therefore, the node and speaker locations can be represented by the one-hot codes. Accordingly, the sound source localization problem is formulated as such a classification task of recognizing the one-hot code of the speaker given the one hot codes of the microphone nodes and their speech recordings. An end-to-end spatial-temporal deep model is designed for the classification problem. It utilizes a spatial-temporal attention architecture with a fusion layer inserted in the middle of the architecture, which is able to handle arbitrarily different numbers of microphone nodes during the model training and test. Experimental results show that the proposed method yields good performance in highly reverberant and noisy environments.
Libri-adhoc40: A dataset collected from synchronized ad-hoc microphone arrays
Apr 07, 2021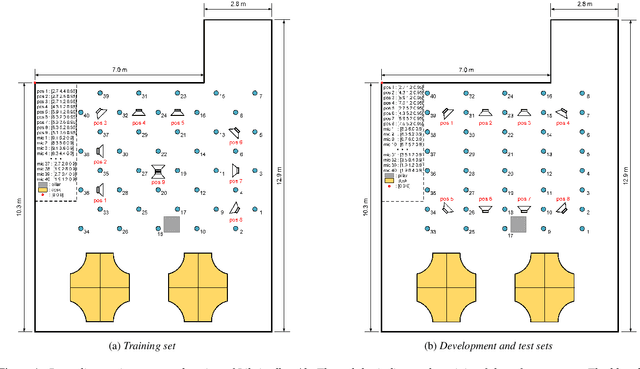
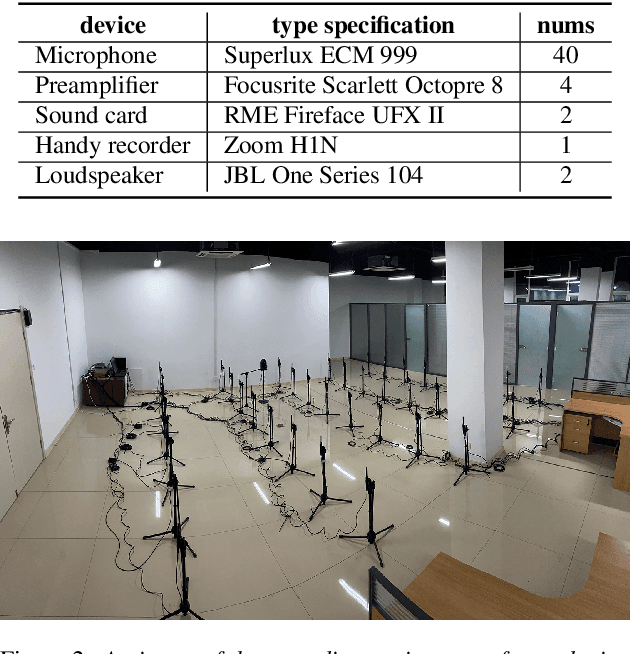

Recently, there is a research trend on ad-hoc microphone arrays. However, most research was conducted on simulated data. Although some data sets were collected with a small number of distributed devices, they were not synchronized which hinders the fundamental theoretical research to ad-hoc microphone arrays. To address this issue, this paper presents a synchronized speech corpus, named Libri-adhoc40, which collects the replayed Librispeech data from loudspeakers by ad-hoc microphone arrays of 40 strongly synchronized distributed nodes in a real office environment. Besides, to provide the evaluation target for speech frontend processing and other applications, we also recorded the replayed speech in an anechoic chamber. We trained several multi-device speech recognition systems on both the Libri-adhoc40 dataset and a simulated dataset. Experimental results demonstrate the validness of the proposed corpus which can be used as a benchmark to reflect the trend and difference of the models with different ad-hoc microphone arrays. The dataset is online available at https://github.com/ISmallFish/Libri-adhoc40.