 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Black-Litterman Portfolio via Hybrid Forecasting Model Combining Multivariate Decomposition and Noise Reduction
May 03, 2025The sensitivity to input parameters and lack of flexibility limits the traditional Mean-Variance model. In contrast, the Black-Litterman model has attracted widespread attention by integrating market equilibrium returns with investors' subjective views. This paper proposes a novel hybrid deep learning model combining Singular Spectrum analysis (SSA), Multivariate Aligned Empirical Mode Decomposition (MA-EMD), and Temporal Convolutional Networks (TCNs), aiming to improve the prediction accuracy of asset prices and thus enhance the ability of the Black-Litterman model to generate subjective views. Experimental results show that noise reduction pre-processing can improve the model's accuracy, and the prediction performance of the proposed model is significantly better than that of three multivariate decomposition benchmark models. We construct an investment portfolio by using 20 representative stocks from the NASDAQ 100 index. By combining the hybrid forecasting model with the Black-Litterman model, the generated investment portfolio exhibits better returns and risk control capabilities than the Mean-Variance, Equal-Weighted, and Market-Weighted models in the short holding period.
Integrating Plug-and-Play Data Priors with Weighted Prediction Error for Speech Dereverberation
Dec 05, 2023



Speech dereverberation aims to alleviate the detrimental effects of late-reverberant components. While the weighted prediction error (WPE) method has shown superior performance in dereverberation, there is still room for further improvement in terms of performance and robustness in complex and noisy environments. Recent research has highlighted the effectiveness of integrating physics-based and data-driven methods, enhancing the performance of various signal processing tasks while maintaining interpretability. Motivated by these advancements, this paper presents a novel dereverberation frame-work, which incorporates data-driven methods for capturing speech priors within the WPE framework. The plug-and-play strategy (PnP), specifically the regularization by denoising (RED) strategy, is utilized to incorporate speech prior information learnt from data during the optimization problem solving iterations. Experimental results validate the effectiveness of the proposed approach.
Distributed Speech Dereverberation Using Weighted Prediction Error
Dec 05, 2023


Speech dereverberation aims to alleviate the negative impact of late reverberant reflections. The weighted prediction error (WPE) method is a well-established technique known for its superior performance in dereverberation. However, in scenarios where microphone nodes are dispersed, the centralized approach of the WPE method requires aggregating all observations for inverse filtering, resulting in a significant computational burden. This paper introduces a distributed speech dereverberation method that emphasizes low computational complexity at each node. Specifically, we leverage the distributed adaptive node-specific signal estimation (DANSE) algorithm within the multichannel linear prediction (MCLP) process. This approach empowers each node to perform local operations with reduced complexity while achieving the global performance through inter-node cooperation. Experimental results validate the effectiveness of our proposed method, showcasing its ability to achieve efficient speech dereverberation in dispersed microphone node scenarios.
Libri-adhoc40: A dataset collected from synchronized ad-hoc microphone arrays
Apr 07, 2021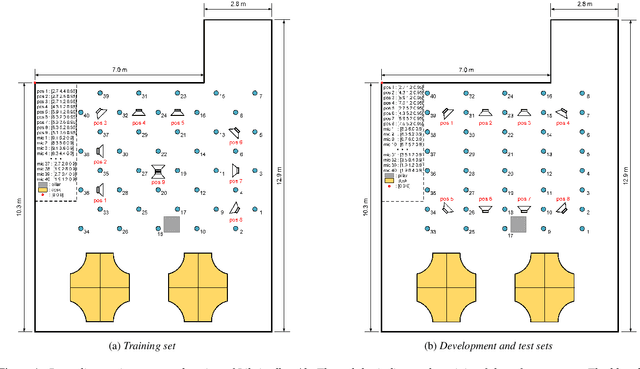
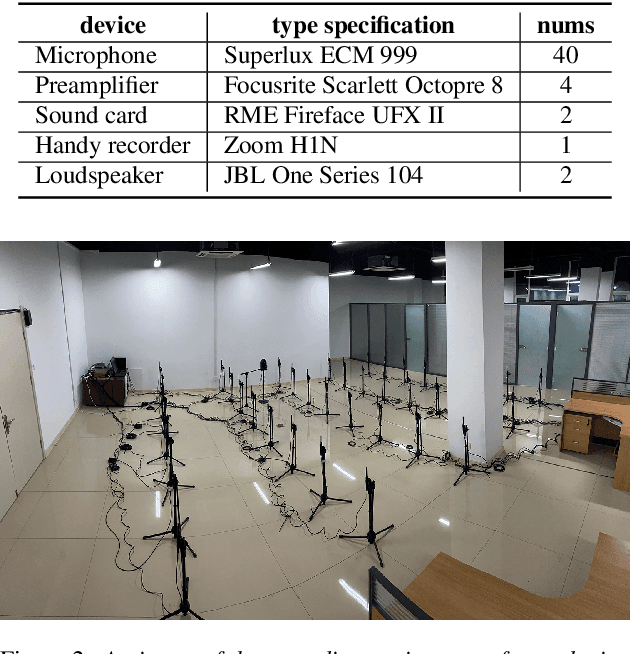

Recently, there is a research trend on ad-hoc microphone arrays. However, most research was conducted on simulated data. Although some data sets were collected with a small number of distributed devices, they were not synchronized which hinders the fundamental theoretical research to ad-hoc microphone arrays. To address this issue, this paper presents a synchronized speech corpus, named Libri-adhoc40, which collects the replayed Librispeech data from loudspeakers by ad-hoc microphone arrays of 40 strongly synchronized distributed nodes in a real office environment. Besides, to provide the evaluation target for speech frontend processing and other applications, we also recorded the replayed speech in an anechoic chamber. We trained several multi-device speech recognition systems on both the Libri-adhoc40 dataset and a simulated dataset. Experimental results demonstrate the validness of the proposed corpus which can be used as a benchmark to reflect the trend and difference of the models with different ad-hoc microphone arrays. The dataset is online available at https://github.com/ISmallFish/Libri-adhoc40.
Deep Ad-hoc Beamforming Based on Speaker Extraction for Target-Dependent Speech Separation
Dec 01, 2020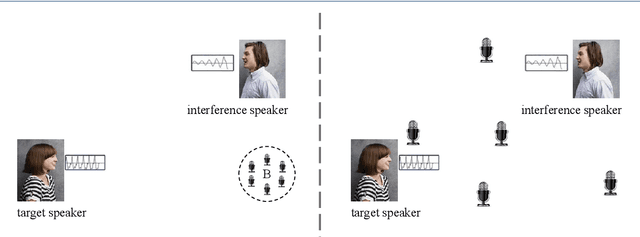
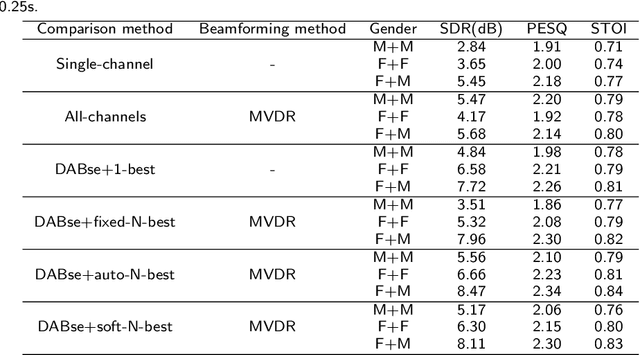
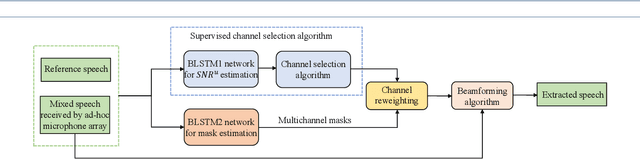
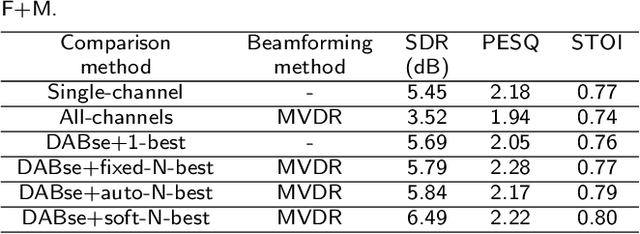
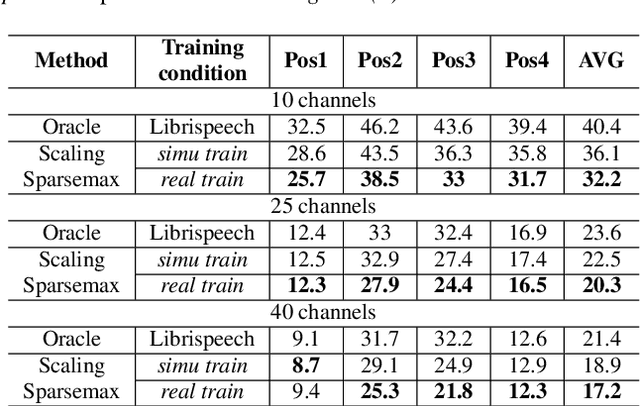
Recently, the research on ad-hoc microphone arrays with deep learning has drawn much attention, especially in speech enhancement and separation. Because an ad-hoc microphone array may cover such a large area that multiple speakers may locate far apart and talk independently, target-dependent speech separation, which aims to extract a target speaker from a mixed speech, is important for extracting and tracing a specific speaker in the ad-hoc array. However, this technique has not been explored yet. In this paper, we propose deep ad-hoc beamforming based on speaker extraction, which is to our knowledge the first work for target-dependent speech separation based on ad-hoc microphone arrays and deep learning. The algorithm contains three components. First, we propose a supervised channel selection framework based on speaker extraction, where the estimated utterance-level SNRs of the target speech are used as the basis for the channel selection. Second, we apply the selected channels to a deep learning based MVDR algorithm, where a single-channel speaker extraction algorithm is applied to each selected channel for estimating the mask of the target speech. We conducted an extensive experiment on a WSJ0-adhoc corpus. Experimental results demonstrate the effectiveness of the proposed method.
Multi-channel Speech Separation Using Deep Embedding Model with Multilayer Bootstrap Networks
Oct 24, 2019

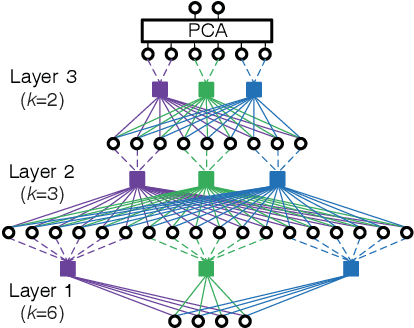

Recently, deep clustering (DPCL) based speaker-independent speech separation has drawn much attention, since it needs little speaker prior information. However, it still has much room of improvement, particularly in reverberant environments. If the training and test environments mismatch which is a common case, the embedding vectors produced by DPCL may contain much noise and many small variations. To deal with the problem, we propose a variant of DPCL, named DPCL++, by applying a recent unsupervised deep learning method---multilayer bootstrap networks(MBN)---to further reduce the noise and small variations of the embedding vectors in an unsupervised way in the test stage, which fascinates k-means to produce a good result. MBN builds a gradually narrowed network from bottom-up via a stack of k-centroids clustering ensembles, where the k-centroids clusterings are trained independently by random sampling and one-nearest-neighbor optimization. To further improve the robustness of DPCL++ in reverberant environments, we take spatial features as part of its input. Experimental results demonstrate the effectiveness of the proposed method.