 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly-supervised anomaly detection for multimodal data distributions
Jun 13, 2024



Weakly-supervised anomaly detection can outperform existing unsupervised methods with the assistance of a very small number of labeled anomalies, which attracts increasing attention from researchers. However, existing weakly-supervised anomaly detection methods are limited as these methods do not factor in the multimodel nature of the real-world data distribution. To mitigate this, we propose the Weakly-supervised Variational-mixture-model-based Anomaly Detector (WVAD). WVAD excels in multimodal datasets. It consists of two components: a deep variational mixture model, and an anomaly score estimator. The deep variational mixture model captures various features of the data from different clusters, then these features are delivered to the anomaly score estimator to assess the anomaly levels. Experimental results on three real-world datasets demonstrate WVAD's superiority.
Joint Selective State Space Model and Detrending for Robust Time Series Anomaly Detection
May 30, 2024



Deep learning-based sequence models are extensively employed in Time Series Anomaly Detection (TSAD) tasks due to their effective sequential modeling capabilities. However, the ability of TSAD is limited by two key challenges: (i) the ability to model long-range dependency and (ii) the generalization issue in the presence of non-stationary data. To tackle these challenges, an anomaly detector that leverages the selective state space model known for its proficiency in capturing long-term dependencies across various domains is proposed. Additionally, a multi-stage detrending mechanism is introduced to mitigate the prominent trend component in non-stationary data to address the generalization issue. Extensive experiments conducted on realworld public datasets demonstrate that the proposed methods surpass all 12 compared baseline methods.
StyleGAN3: Generative Networks for Improving the Equivariance of Translation and Rotation
Jul 08, 2023



StyleGAN can use style to affect facial posture and identity features, and noise to affect hair, wrinkles, skin color and other details. Among these, the outcomes of the picture processing will vary slightly between different versions of styleGAN. As a result, the comparison of performance differences between styleGAN2 and the two modified versions of styleGAN3 will be the main focus of this study. We used the FFHQ dataset as the dataset and FID, EQ-T, and EQ-R were used to be the assessment of the model. In the end, we discovered that Stylegan3 version is a better generative network to improve the equivariance. Our findings have a positive impact on the creation of animation and videos.
Improving Autoencoder-based Outlier Detection with Adjustable Probabilistic Reconstruction Error and Mean-shift Outlier Scoring
Apr 03, 2023



Autoencoders were widely used in many machine learning tasks thanks to their strong learning ability which has drawn great interest among researchers in the field of outlier detection. However, conventional autoencoder-based methods lacked considerations in two aspects. This limited their performance in outlier detection. First, the mean squared error used in conventional autoencoders ignored the judgment uncertainty of the autoencoder, which limited their representation ability. Second, autoencoders suffered from the abnormal reconstruction problem: some outliers can be unexpectedly reconstructed well, making them difficult to identify from the inliers. To mitigate the aforementioned issues, two novel methods were proposed in this paper. First, a novel loss function named Probabilistic Reconstruction Error (PRE) was constructed to factor in both reconstruction bias and judgment uncertainty. To further control the trade-off of these two factors, two weights were introduced in PRE producing Adjustable Probabilistic Reconstruction Error (APRE), which benefited the outlier detection in different applications. Second, a conceptually new outlier scoring method based on mean-shift (MSS) was proposed to reduce the false inliers caused by the autoencoder. Experiments on 32 real-world outlier detection datasets proved the effectiveness of the proposed methods. The combination of the proposed methods achieved 41% of the relative performance improvement compared to the best baseline. The MSS improved the performance of multiple autoencoder-based outlier detectors by an average of 20%. The proposed two methods have the potential to advance autoencoder's development in outlier detection. The code is available on www.OutlierNet.com for reproducibility.
Attention-based multi-channel speaker verification with ad-hoc microphone arrays
Jul 01, 2021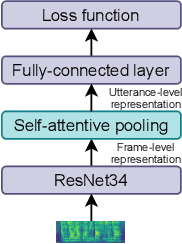
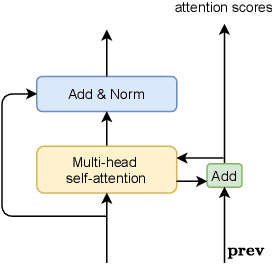
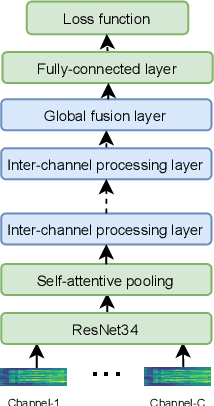
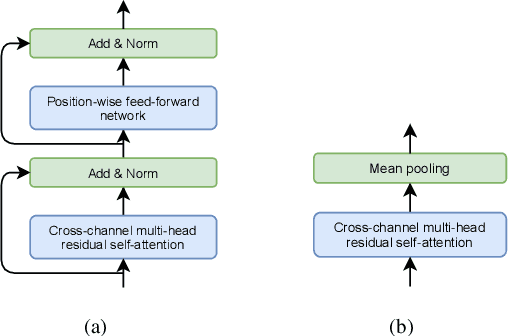
Recently, ad-hoc microphone array has been widely studied. Unlike traditional microphone array settings, the spatial arrangement and number of microphones of ad-hoc microphone arrays are not known in advance, which hinders the adaptation of traditional speaker verification technologies to ad-hoc microphone arrays. To overcome this weakness, in this paper, we propose attention-based multi-channel speaker verification with ad-hoc microphone arrays. Specifically, we add an inter-channel processing layer and a global fusion layer after the pooling layer of a single-channel speaker verification system. The inter-channel processing layer applies a so-called residual self-attention along the channel dimension for allocating weights to different microphones. The global fusion layer integrates all channels in a way that is independent to the number of the input channels. We further replace the softmax operator in the residual self-attention with sparsemax, which forces the channel weights of very noisy channels to zero. Experimental results with ad-hoc microphone arrays of over 30 channels demonstrate the effectiveness of the proposed methods. For example, the multi-channel speaker verification with sparsemax achieves an equal error rate (EER) of over 20% lower than oracle one-best system on semi-real data sets, and over 30% lower on simulation data sets, in test scenarios with both matched and mismatched channel numbers.
Libri-adhoc40: A dataset collected from synchronized ad-hoc microphone arrays
Apr 07, 2021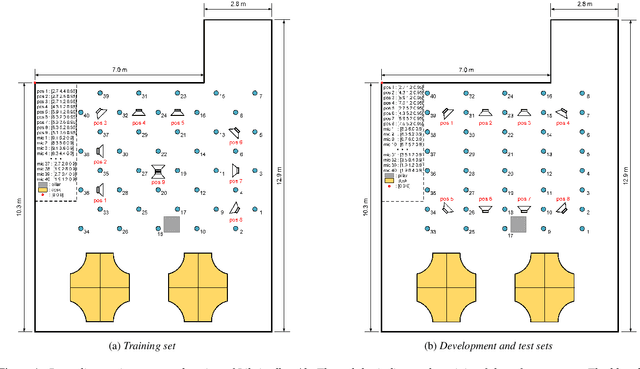
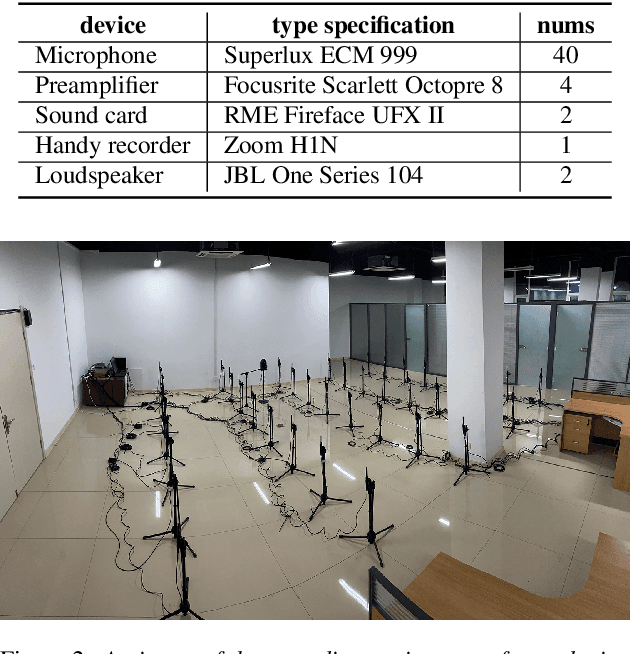

Recently, there is a research trend on ad-hoc microphone arrays. However, most research was conducted on simulated data. Although some data sets were collected with a small number of distributed devices, they were not synchronized which hinders the fundamental theoretical research to ad-hoc microphone arrays. To address this issue, this paper presents a synchronized speech corpus, named Libri-adhoc40, which collects the replayed Librispeech data from loudspeakers by ad-hoc microphone arrays of 40 strongly synchronized distributed nodes in a real office environment. Besides, to provide the evaluation target for speech frontend processing and other applications, we also recorded the replayed speech in an anechoic chamber. We trained several multi-device speech recognition systems on both the Libri-adhoc40 dataset and a simulated dataset. Experimental results demonstrate the validness of the proposed corpus which can be used as a benchmark to reflect the trend and difference of the models with different ad-hoc microphone arrays. The dataset is online available at https://github.com/ISmallFish/Libri-adhoc40.
Scaling sparsemax based channel selection for speech recognition with ad-hoc microphone arrays
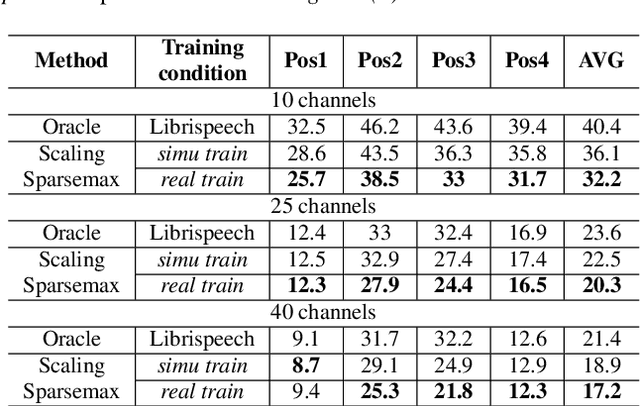
Apr 01, 2021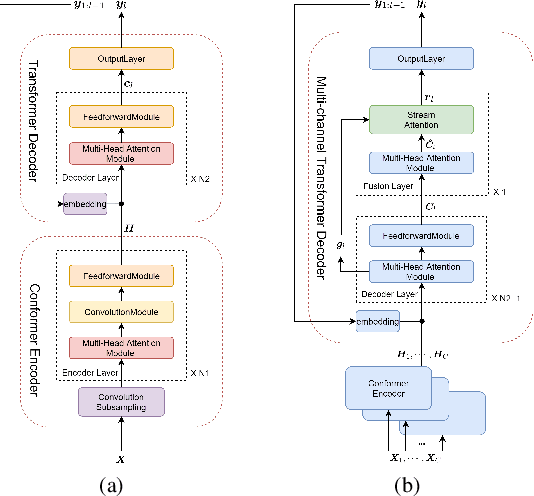
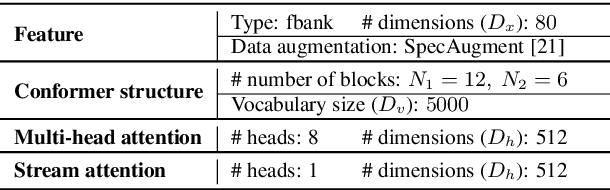
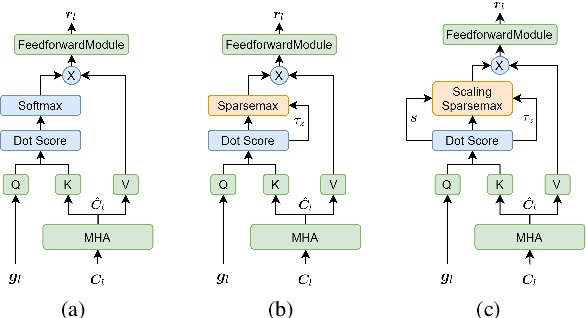
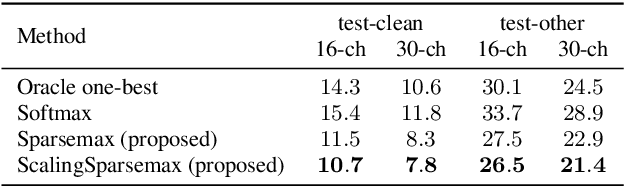
Recently, speech recognition with ad-hoc microphone arrays has received much attention. It is known that channel selection is an important problem of ad-hoc microphone arrays, however, this topic seems far from explored in speech recognition yet, particularly with a large-scale ad-hoc microphone array. To address this problem, we propose a Scaling Sparsemax algorithm for the channel selection problem of the speech recognition with large-scale ad-hoc microphone arrays. Specifically, we first replace the conventional Softmax operator in the stream attention mechanism of a multichannel end-to-end speech recognition system with Sparsemax, which conducts channel selection by forcing the channel weights of noisy channels to zero. Because Sparsemax punishes the weights of many channels to zero harshly, we propose Scaling Sparsemax which punishes the channels mildly by setting the weights of very noisy channels to zero only. Experimental results with ad-hoc microphone arrays of over 30 channels under the conformer speech recognition architecture show that the proposed Scaling Sparsemax yields a word error rate of over 30% lower than Softmax on simulation data sets, and over 20% lower on semi-real data sets, in test scenarios with both matched and mismatched channel numbers.