 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeDefense: A Toolkit to Defend Against Fake Audio
Jan 21, 2026The advances in generative AI have enabled the creation of synthetic audio which is perceptually indistinguishable from real, genuine audio. Although this stellar progress enables many positive applications, it also raises risks of misuse, such as for impersonation, disinformation and fraud. Despite a growing number of open-source fake audio detection codes released through numerous challenges and initiatives, most are tailored to specific competitions, datasets or models. A standardized and unified toolkit that supports the fair benchmarking and comparison of competing solutions with not just common databases, protocols, metrics, but also a shared codebase, is missing. To address this, we propose WeDefense, the first open-source toolkit to support both fake audio detection and localization. Beyond model training, WeDefense emphasizes critical yet often overlooked components: flexible input and augmentation, calibration, score fusion, standardized evaluation metrics, and analysis tools for deeper understanding and interpretation. The toolkit is publicly available at https://github.com/zlin0/wedefense with interactive demos for fake audio detection and localization.
PadAug: Robust Speaker Verification with Simple Waveform-Level Silence Padding
Aug 20, 2025



The presence of non-speech segments in utterances often leads to the performance degradation of speaker verification. Existing systems usually use voice activation detection as a preprocessing step to cut off long silence segments. However, short silence segments, particularly those between speech segments, still remain a problem for speaker verification. To address this issue, in this paper, we propose a simple wave-level data augmentation method, \textit{PadAug}, which aims to enhance the system's robustness to silence segments. The core idea of \textit{PadAug} is to concatenate silence segments with speech segments at the waveform level for model training. Due to its simplicity, it can be directly applied to the current state-of-the art architectures. Experimental results demonstrate the effectiveness of the proposed \textit{PadAug}. For example, applying \textit{PadAug} to ResNet34 achieves a relative equal error rate reduction of 5.0\% on the voxceleb dataset. Moreover, the \textit{PadAug} based systems are robust to different lengths and proportions of silence segments in the test data.
TouchASP: Elastic Automatic Speech Perception that Everyone Can Touch
Dec 20, 2024



Large Automatic Speech Recognition (ASR) models demand a vast number of parameters, copious amounts of data, and significant computational resources during the training process. However, such models can merely be deployed on high-compute cloud platforms and are only capable of performing speech recognition tasks. This leads to high costs and restricted capabilities. In this report, we initially propose the elastic mixture of the expert (eMoE) model. This model can be trained just once and then be elastically scaled in accordance with deployment requirements. Secondly, we devise an unsupervised data creation and validation procedure and gather millions of hours of audio data from diverse domains for training. Using these two techniques, our system achieves elastic deployment capabilities while reducing the Character Error Rate (CER) on the SpeechIO testsets from 4.98\% to 2.45\%. Thirdly, our model is not only competent in Mandarin speech recognition but also proficient in multilingual, multi-dialect, emotion, gender, and sound event perception. We refer to this as Automatic Speech Perception (ASP), and the perception results are presented in the experimental section.
Spatial-temporal Graph Based Multi-channel Speaker Verification With Ad-hoc Microphone Arrays
Jul 03, 2023



The performance of speaker verification degrades significantly in adverse acoustic environments with strong reverberation and noise. To address this issue, this paper proposes a spatial-temporal graph convolutional network (GCN) method for the multi-channel speaker verification with ad-hoc microphone arrays. It includes a feature aggregation block and a channel selection block, both of which are built on graphs. The feature aggregation block fuses speaker features among different time and channels by a spatial-temporal GCN. The graph-based channel selection block discards the noisy channels that may contribute negatively to the system. The proposed method is flexible in incorporating various kinds of graphs and prior knowledge. We compared the proposed method with six representative methods in both real-world and simulated environments. Experimental results show that the proposed method achieves a relative equal error rate (EER) reduction of $\mathbf{15.39\%}$ lower than the strongest referenced method in the simulated datasets, and $\mathbf{17.70\%}$ lower than the latter in the real datasets. Moreover, its performance is robust across different signal-to-noise ratios and reverberation time.
Wespeaker baselines for VoxSRC2023
Jun 28, 2023



This report showcases the results achieved using the wespeaker toolkit for the VoxSRC2023 Challenge. Our aim is to provide participants, especially those with limited experience, with clear and straightforward guidelines to develop their initial systems. Via well-structured recipes and strong results, we hope to offer an accessible and good enough start point for all interested individuals. In this report, we describe the results achieved on the VoxSRC2023 dev set using the pretrained models, you can check the CodaLab evaluation server for the results on the evaluation set.
Fast-U2++: Fast and Accurate End-to-End Speech Recognition in Joint CTC/Attention Frames
Nov 02, 2022Recently, the unified streaming and non-streaming two-pass (U2/U2++) end-to-end model for speech recognition has shown great performance in terms of streaming capability, accuracy and latency. In this paper, we present fast-U2++, an enhanced version of U2++ to further reduce partial latency. The core idea of fast-U2++ is to output partial results of the bottom layers in its encoder with a small chunk, while using a large chunk in the top layers of its encoder to compensate the performance degradation caused by the small chunk. Moreover, we use knowledge distillation method to reduce the token emission latency. We present extensive experiments on Aishell-1 dataset. Experiments and ablation studies show that compared to U2++, fast-U2++ reduces model latency from 320ms to 80ms, and achieves a character error rate (CER) of 5.06% with a streaming setup.
Wespeaker: A Research and Production oriented Speaker Embedding Learning Toolkit
Nov 01, 2022



Speaker modeling is essential for many related tasks, such as speaker recognition and speaker diarization. The dominant modeling approach is fixed-dimensional vector representation, i.e., speaker embedding. This paper introduces a research and production oriented speaker embedding learning toolkit, Wespeaker. Wespeaker contains the implementation of scalable data management, state-of-the-art speaker embedding models, loss functions, and scoring back-ends, with highly competitive results achieved by structured recipes which were adopted in the winning systems in several speaker verification challenges. The application to other downstream tasks such as speaker diarization is also exhibited in the related recipe. Moreover, CPU- and GPU-compatible deployment codes are integrated for production-oriented development. The toolkit is publicly available at https://github.com/wenet-e2e/wespeaker.
Frame-level multi-channel speaker verification with large-scale ad-hoc microphone arrays
Oct 15, 2021Ad-hoc microphone arrays has recieved attention, in which the number and arrangement of microphones are unknown. Traditional multi-channel processing methods can not be directly used in ad-hoc. Recently, to solve this problem, an utterance-level ASV with ad-hoc microphone arrays has been proposed, which first extracts utterance-level speaker embeddings from each channel of an ad-hoc microphone array, and then fuses the embeddings for the final verification. However, this method cannot make full use of the cross-channel information. In this paper, we present a novel multi-channel ASV model at the frame-level. Specifically, we add spatio-temporal processing blocks (STB) before the pooling layer, which models the contextual relationship within and between channels and across time, respectively. The channel-attended outputs from STB are sent to the pooling layer to obtain an utterance-level speaker representation. Experimental results demonstrate the effectiveness of the proposed method.
AUC Optimization for Robust Small-footprint Keyword Spotting with Limited Training Data
Jul 13, 2021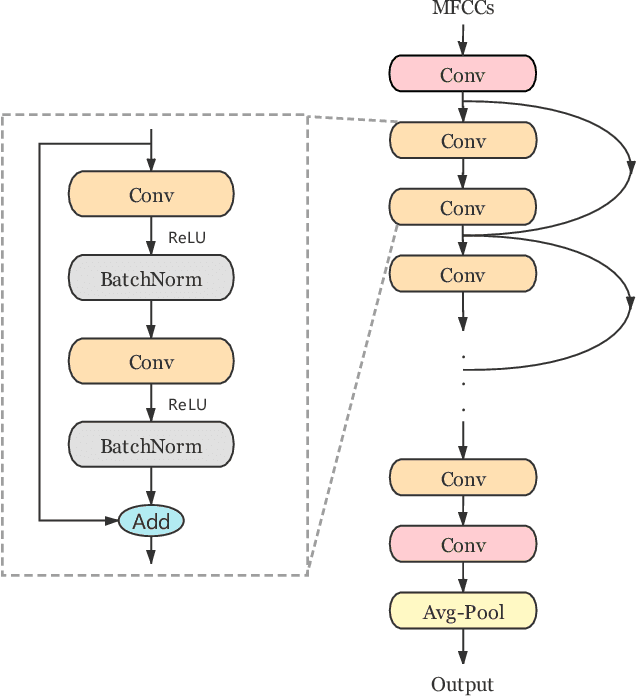

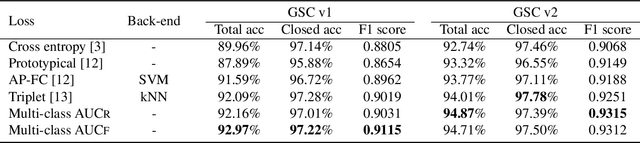

Deep neural networks provide effective solutions to small-footprint keyword spotting (KWS). However, if training data is limited, it remains challenging to achieve robust and highly accurate KWS in real-world scenarios where unseen sounds that are out of the training data are frequently encountered. Most conventional methods aim to maximize the classification accuracy on the training set, without taking the unseen sounds into account. To enhance the robustness of the deep neural networks based KWS, in this paper, we introduce a new loss function, named the maximization of the area under the receiver-operating-characteristic curve (AUC). The proposed method not only maximizes the classification accuracy of keywords on the closed training set, but also maximizes the AUC score for optimizing the performance of non-keyword segments detection. Experimental results on the Google Speech Commands dataset v1 and v2 show that our method achieves new state-of-the-art performance in terms of most evaluation metrics.
Attention-based multi-channel speaker verification with ad-hoc microphone arrays
Jul 01, 2021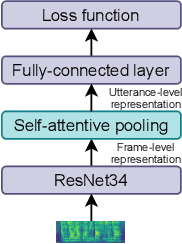
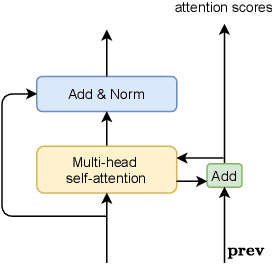
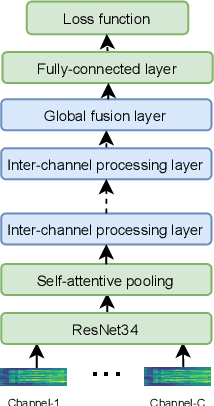
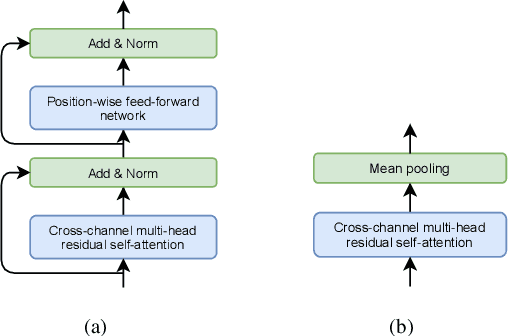
Recently, ad-hoc microphone array has been widely studied. Unlike traditional microphone array settings, the spatial arrangement and number of microphones of ad-hoc microphone arrays are not known in advance, which hinders the adaptation of traditional speaker verification technologies to ad-hoc microphone arrays. To overcome this weakness, in this paper, we propose attention-based multi-channel speaker verification with ad-hoc microphone arrays. Specifically, we add an inter-channel processing layer and a global fusion layer after the pooling layer of a single-channel speaker verification system. The inter-channel processing layer applies a so-called residual self-attention along the channel dimension for allocating weights to different microphones. The global fusion layer integrates all channels in a way that is independent to the number of the input channels. We further replace the softmax operator in the residual self-attention with sparsemax, which forces the channel weights of very noisy channels to zero. Experimental results with ad-hoc microphone arrays of over 30 channels demonstrate the effectiveness of the proposed methods. For example, the multi-channel speaker verification with sparsemax achieves an equal error rate (EER) of over 20% lower than oracle one-best system on semi-real data sets, and over 30% lower on simulation data sets, in test scenarios with both matched and mismatched channel numbers.