 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCohortFinder: an open-source tool for data-driven partitioning of biomedical image cohorts to yield robust machine learning models
Jul 17, 2023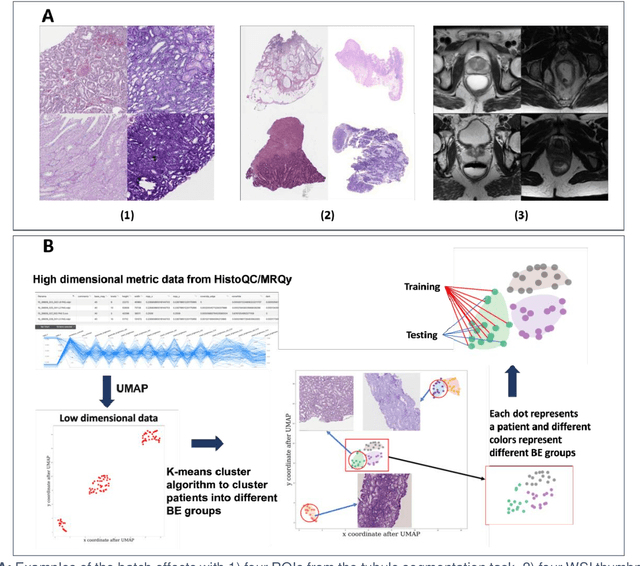

Batch effects (BEs) refer to systematic technical differences in data collection unrelated to biological variations whose noise is shown to negatively impact machine learning (ML) model generalizability. Here we release CohortFinder, an open-source tool aimed at mitigating BEs via data-driven cohort partitioning. We demonstrate CohortFinder improves ML model performance in downstream medical image processing tasks. CohortFinder is freely available for download at cohortfinder.com.
Spatial-temporal Graph Based Multi-channel Speaker Verification With Ad-hoc Microphone Arrays
Jul 03, 2023The performance of speaker verification degrades significantly in adverse acoustic environments with strong reverberation and noise. To address this issue, this paper proposes a spatial-temporal graph convolutional network (GCN) method for the multi-channel speaker verification with ad-hoc microphone arrays. It includes a feature aggregation block and a channel selection block, both of which are built on graphs. The feature aggregation block fuses speaker features among different time and channels by a spatial-temporal GCN. The graph-based channel selection block discards the noisy channels that may contribute negatively to the system. The proposed method is flexible in incorporating various kinds of graphs and prior knowledge. We compared the proposed method with six representative methods in both real-world and simulated environments. Experimental results show that the proposed method achieves a relative equal error rate (EER) reduction of $\mathbf{15.39\%}$ lower than the strongest referenced method in the simulated datasets, and $\mathbf{17.70\%}$ lower than the latter in the real datasets. Moreover, its performance is robust across different signal-to-noise ratios and reverberation time.
Few-shot Single-view 3D Reconstruction with Memory Prior Contrastive Network
Jul 30, 2022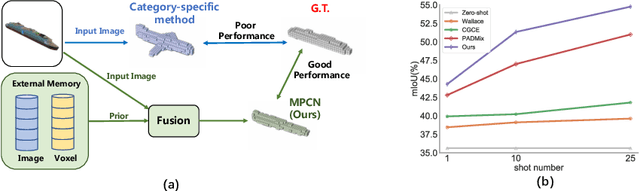
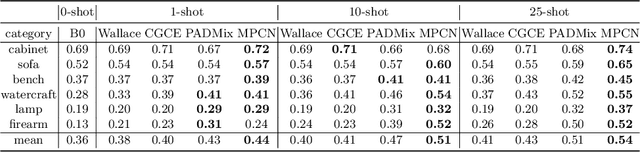
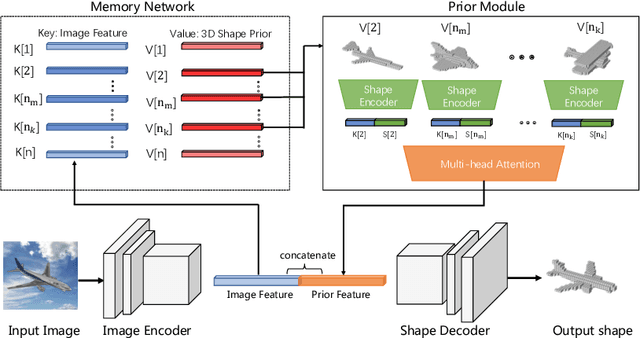
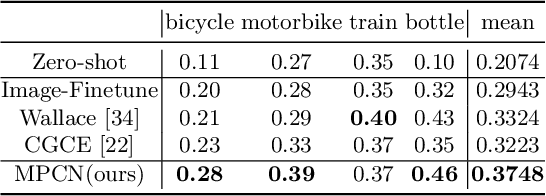
3D reconstruction of novel categories based on few-shot learning is appealing in real-world applications and attracts increasing research interests. Previous approaches mainly focus on how to design shape prior models for different categories. Their performance on unseen categories is not very competitive. In this paper, we present a Memory Prior Contrastive Network (MPCN) that can store shape prior knowledge in a few-shot learning based 3D reconstruction framework. With the shape memory, a multi-head attention module is proposed to capture different parts of a candidate shape prior and fuse these parts together to guide 3D reconstruction of novel categories. Besides, we introduce a 3D-aware contrastive learning method, which can not only complement the retrieval accuracy of memory network, but also better organize image features for downstream tasks. Compared with previous few-shot 3D reconstruction methods, MPCN can handle the inter-class variability without category annotations. Experimental results on a benchmark synthetic dataset and the Pascal3D+ real-world dataset show that our model outperforms the current state-of-the-art methods significantly.
3D-Augmented Contrastive Knowledge Distillation for Image-based Object Pose Estimation
Jun 02, 2022
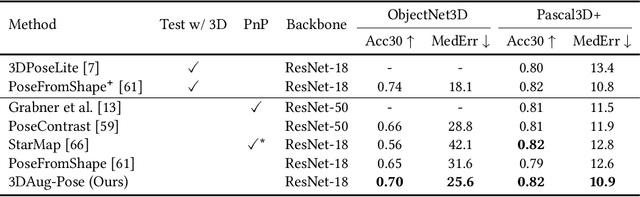
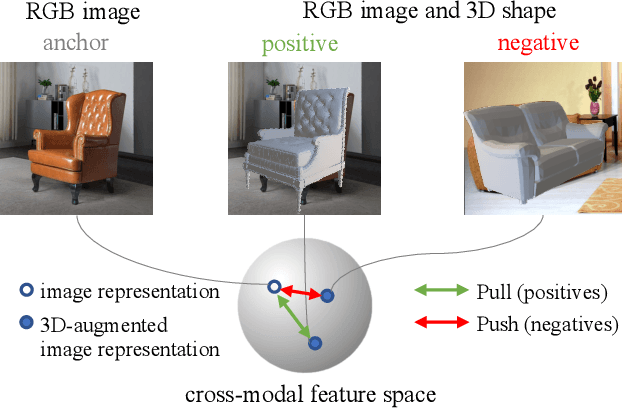
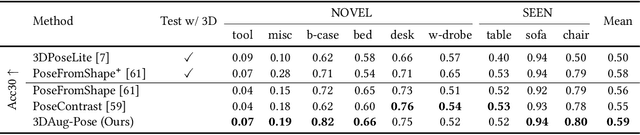
Image-based object pose estimation sounds amazing because in real applications the shape of object is oftentimes not available or not easy to take like photos. Although it is an advantage to some extent, un-explored shape information in 3D vision learning problem looks like "flaws in jade". In this paper, we deal with the problem in a reasonable new setting, namely 3D shape is exploited in the training process, and the testing is still purely image-based. We enhance the performance of image-based methods for category-agnostic object pose estimation by exploiting 3D knowledge learned by a multi-modal method. Specifically, we propose a novel contrastive knowledge distillation framework that effectively transfers 3D-augmented image representation from a multi-modal model to an image-based model. We integrate contrastive learning into the two-stage training procedure of knowledge distillation, which formulates an advanced solution to combine these two approaches for cross-modal tasks. We experimentally report state-of-the-art results compared with existing category-agnostic image-based methods by a large margin (up to +5% improvement on ObjectNet3D dataset), demonstrating the effectiveness of our method.
Probing Simile Knowledge from Pre-trained Language Models
Apr 27, 2022

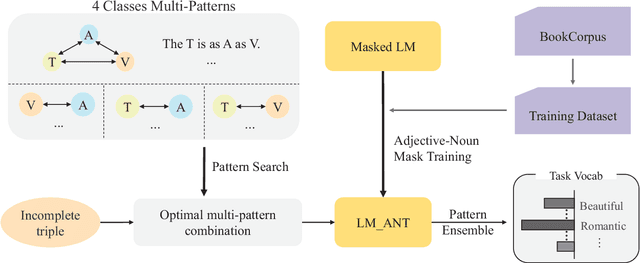
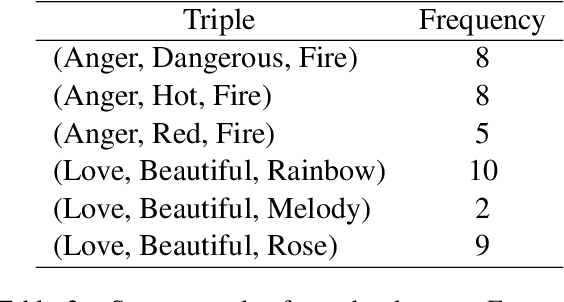
Simile interpretation (SI) and simile generation (SG) are challenging tasks for NLP because models require adequate world knowledge to produce predictions. Previous works have employed many hand-crafted resources to bring knowledge-related into models, which is time-consuming and labor-intensive. In recent years, pre-trained language models (PLMs) based approaches have become the de-facto standard in NLP since they learn generic knowledge from a large corpus. The knowledge embedded in PLMs may be useful for SI and SG tasks. Nevertheless, there are few works to explore it. In this paper, we probe simile knowledge from PLMs to solve the SI and SG tasks in the unified framework of simile triple completion for the first time. The backbone of our framework is to construct masked sentences with manual patterns and then predict the candidate words in the masked position. In this framework, we adopt a secondary training process (Adjective-Noun mask Training) with the masked language model (MLM) loss to enhance the prediction diversity of candidate words in the masked position. Moreover, pattern ensemble (PE) and pattern search (PS) are applied to improve the quality of predicted words. Finally, automatic and human evaluations demonstrate the effectiveness of our framework in both SI and SG tasks.
CaSS: A Channel-aware Self-supervised Representation Learning Framework for Multivariate Time Series Classification
Mar 08, 2022
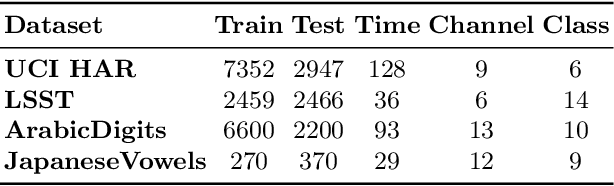
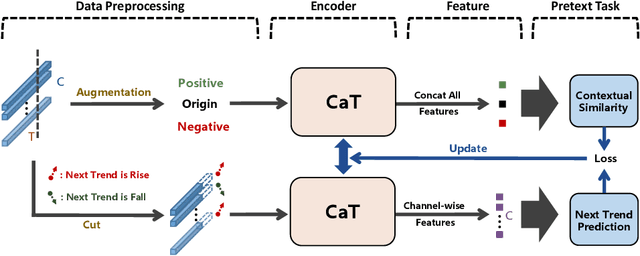
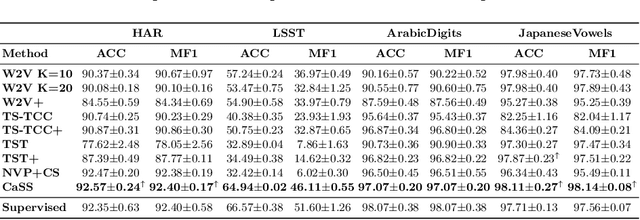
Self-supervised representation learning of Multivariate Time Series (MTS) is a challenging task and attracts increasing research interests in recent years. Many previous works focus on the pretext task of self-supervised learning and usually neglect the complex problem of MTS encoding, leading to unpromising results. In this paper, we tackle this challenge from two aspects: encoder and pretext task, and propose a unified channel-aware self-supervised learning framework CaSS. Specifically, we first design a new Transformer-based encoder Channel-aware Transformer (CaT) to capture the complex relationships between different time channels of MTS. Second, we combine two novel pretext tasks Next Trend Prediction (NTP) and Contextual Similarity (CS) for the self-supervised representation learning with our proposed encoder. Extensive experiments are conducted on several commonly used benchmark datasets. The experimental results show that our framework achieves new state-of-the-art comparing with previous self-supervised MTS representation learning methods (up to +7.70\% improvement on LSST dataset) and can be well applied to the downstream MTS classification.
Libri-adhoc40: A dataset collected from synchronized ad-hoc microphone arrays
Apr 07, 2021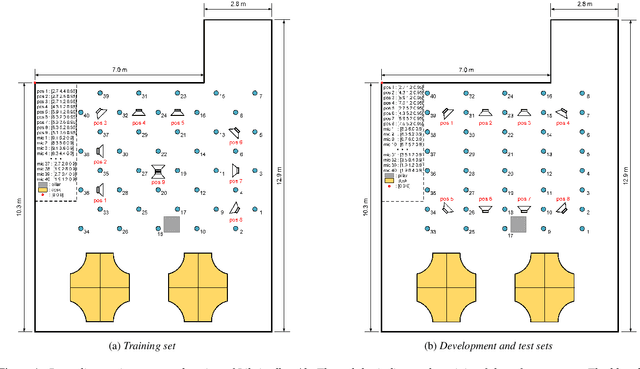
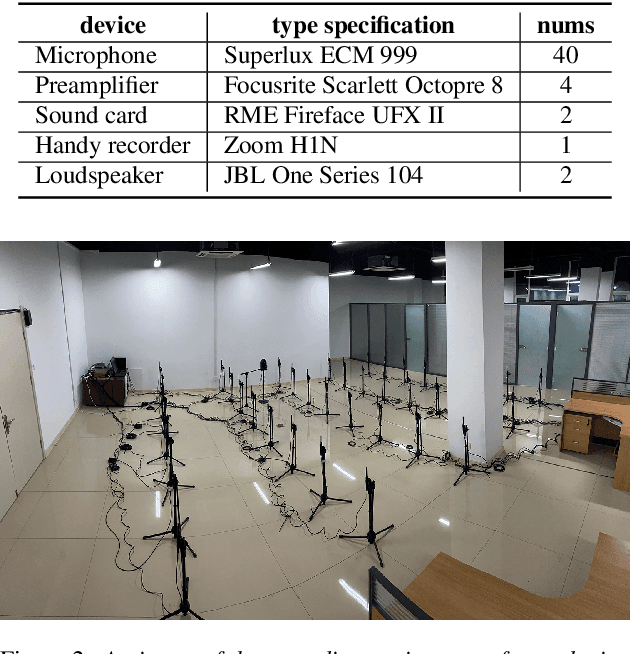
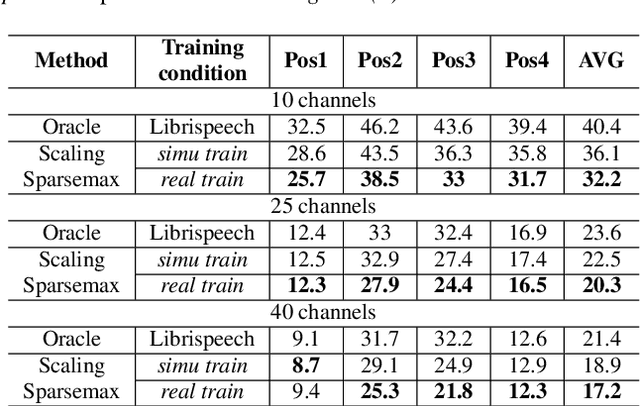

Recently, there is a research trend on ad-hoc microphone arrays. However, most research was conducted on simulated data. Although some data sets were collected with a small number of distributed devices, they were not synchronized which hinders the fundamental theoretical research to ad-hoc microphone arrays. To address this issue, this paper presents a synchronized speech corpus, named Libri-adhoc40, which collects the replayed Librispeech data from loudspeakers by ad-hoc microphone arrays of 40 strongly synchronized distributed nodes in a real office environment. Besides, to provide the evaluation target for speech frontend processing and other applications, we also recorded the replayed speech in an anechoic chamber. We trained several multi-device speech recognition systems on both the Libri-adhoc40 dataset and a simulated dataset. Experimental results demonstrate the validness of the proposed corpus which can be used as a benchmark to reflect the trend and difference of the models with different ad-hoc microphone arrays. The dataset is online available at https://github.com/ISmallFish/Libri-adhoc40.