 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCaSS: A Channel-aware Self-supervised Representation Learning Framework for Multivariate Time Series Classification
Paper and Code
Mar 08, 2022
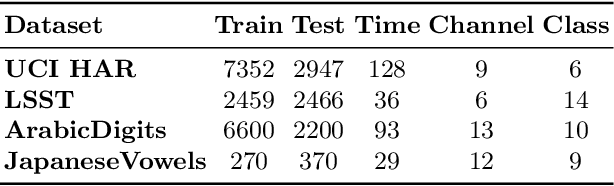
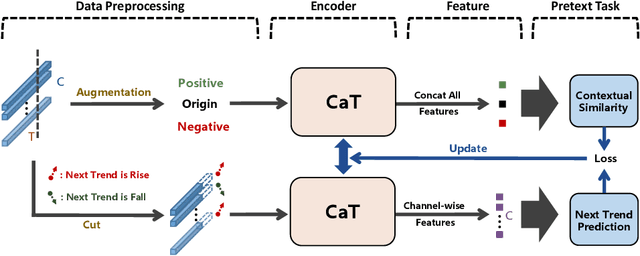
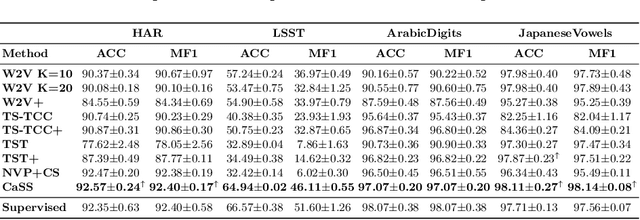
Self-supervised representation learning of Multivariate Time Series (MTS) is a challenging task and attracts increasing research interests in recent years. Many previous works focus on the pretext task of self-supervised learning and usually neglect the complex problem of MTS encoding, leading to unpromising results. In this paper, we tackle this challenge from two aspects: encoder and pretext task, and propose a unified channel-aware self-supervised learning framework CaSS. Specifically, we first design a new Transformer-based encoder Channel-aware Transformer (CaT) to capture the complex relationships between different time channels of MTS. Second, we combine two novel pretext tasks Next Trend Prediction (NTP) and Contextual Similarity (CS) for the self-supervised representation learning with our proposed encoder. Extensive experiments are conducted on several commonly used benchmark datasets. The experimental results show that our framework achieves new state-of-the-art comparing with previous self-supervised MTS representation learning methods (up to +7.70\% improvement on LSST dataset) and can be well applied to the downstream MTS classification.