 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVIPeR: Visual Incremental Place Recognition with Adaptive Mining and Lifelong Learning
Jul 31, 2024Visual place recognition (VPR) is an essential component of many autonomous and augmented/virtual reality systems. It enables the systems to robustly localize themselves in large-scale environments. Existing VPR methods demonstrate attractive performance at the cost of heavy pre-training and limited generalizability. When deployed in unseen environments, these methods exhibit significant performance drops. Targeting this issue, we present VIPeR, a novel approach for visual incremental place recognition with the ability to adapt to new environments while retaining the performance of previous environments. We first introduce an adaptive mining strategy that balances the performance within a single environment and the generalizability across multiple environments. Then, to prevent catastrophic forgetting in lifelong learning, we draw inspiration from human memory systems and design a novel memory bank for our VIPeR. Our memory bank contains a sensory memory, a working memory and a long-term memory, with the first two focusing on the current environment and the last one for all previously visited environments. Additionally, we propose a probabilistic knowledge distillation to explicitly safeguard the previously learned knowledge. We evaluate our proposed VIPeR on three large-scale datasets, namely Oxford Robotcar, Nordland, and TartanAir. For comparison, we first set a baseline performance with naive finetuning. Then, several more recent lifelong learning methods are compared. Our VIPeR achieves better performance in almost all aspects with the biggest improvement of 13.65% in average performance.
CaSS: A Channel-aware Self-supervised Representation Learning Framework for Multivariate Time Series Classification
Mar 08, 2022
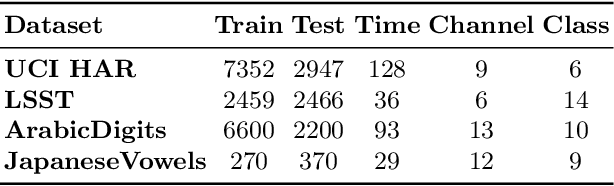
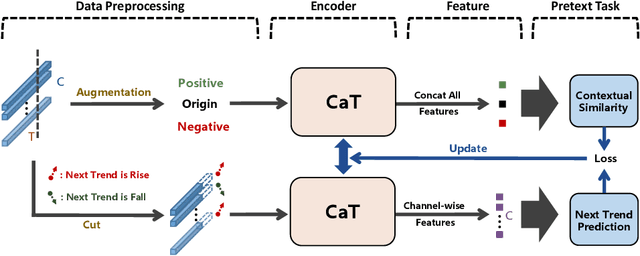
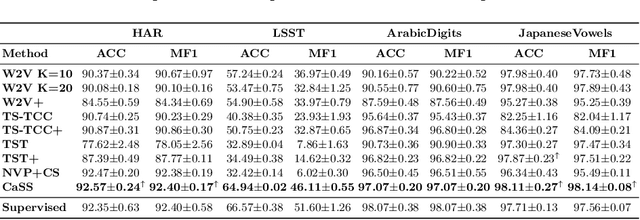
Self-supervised representation learning of Multivariate Time Series (MTS) is a challenging task and attracts increasing research interests in recent years. Many previous works focus on the pretext task of self-supervised learning and usually neglect the complex problem of MTS encoding, leading to unpromising results. In this paper, we tackle this challenge from two aspects: encoder and pretext task, and propose a unified channel-aware self-supervised learning framework CaSS. Specifically, we first design a new Transformer-based encoder Channel-aware Transformer (CaT) to capture the complex relationships between different time channels of MTS. Second, we combine two novel pretext tasks Next Trend Prediction (NTP) and Contextual Similarity (CS) for the self-supervised representation learning with our proposed encoder. Extensive experiments are conducted on several commonly used benchmark datasets. The experimental results show that our framework achieves new state-of-the-art comparing with previous self-supervised MTS representation learning methods (up to +7.70\% improvement on LSST dataset) and can be well applied to the downstream MTS classification.