 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKeyframe-Based Feed-Forward Visual Odometry
Jan 22, 2026The emergence of visual foundation models has revolutionized visual odometry~(VO) and SLAM, enabling pose estimation and dense reconstruction within a single feed-forward network. However, unlike traditional pipelines that leverage keyframe methods to enhance efficiency and accuracy, current foundation model based methods, such as VGGT-Long, typically process raw image sequences indiscriminately. This leads to computational redundancy and degraded performance caused by low inter-frame parallax, which provides limited contextual stereo information. Integrating traditional geometric heuristics into these methods is non-trivial, as their performance depends on high-dimensional latent representations rather than explicit geometric metrics. To bridge this gap, we propose a novel keyframe-based feed-forward VO. Instead of relying on hand-crafted rules, our approach employs reinforcement learning to derive an adaptive keyframe policy in a data-driven manner, aligning selection with the intrinsic characteristics of the underlying foundation model. We train our agent on TartanAir dataset and conduct extensive evaluations across several real-world datasets. Experimental results demonstrate that the proposed method achieves consistent and substantial improvements over state-of-the-art feed-forward VO methods.
Spontaneous Spatial Cognition Emerges during Egocentric Video Viewing through Non-invasive BCI
Jul 16, 2025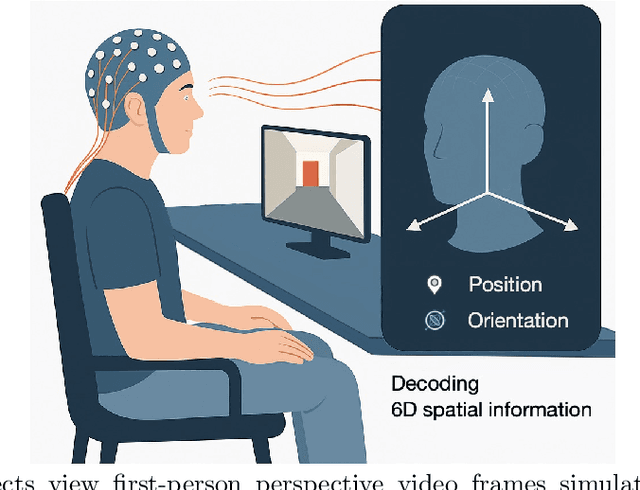


Humans possess a remarkable capacity for spatial cognition, allowing for self-localization even in novel or unfamiliar environments. While hippocampal neurons encoding position and orientation are well documented, the large-scale neural dynamics supporting spatial representation, particularly during naturalistic, passive experience, remain poorly understood. Here, we demonstrate for the first time that non-invasive brain-computer interfaces (BCIs) based on electroencephalography (EEG) can decode spontaneous, fine-grained egocentric 6D pose, comprising three-dimensional position and orientation, during passive viewing of egocentric video. Despite EEG's limited spatial resolution and high signal noise, we find that spatially coherent visual input (i.e., continuous and structured motion) reliably evokes decodable spatial representations, aligning with participants' subjective sense of spatial engagement. Decoding performance further improves when visual input is presented at a frame rate of 100 ms per image, suggesting alignment with intrinsic neural temporal dynamics. Using gradient-based backpropagation through a neural decoding model, we identify distinct EEG channels contributing to position -- and orientation specific -- components, revealing a distributed yet complementary neural encoding scheme. These findings indicate that the brain's spatial systems operate spontaneously and continuously, even under passive conditions, challenging traditional distinctions between active and passive spatial cognition. Our results offer a non-invasive window into the automatic construction of egocentric spatial maps and advance our understanding of how the human mind transforms everyday sensory experience into structured internal representations.
3D Scene-Camera Representation with Joint Camera Photometric Optimization
Jun 26, 2025Representing scenes from multi-view images is a crucial task in computer vision with extensive applications. However, inherent photometric distortions in the camera imaging can significantly degrade image quality. Without accounting for these distortions, the 3D scene representation may inadvertently incorporate erroneous information unrelated to the scene, diminishing the quality of the representation. In this paper, we propose a novel 3D scene-camera representation with joint camera photometric optimization. By introducing internal and external photometric model, we propose a full photometric model and corresponding camera representation. Based on simultaneously optimizing the parameters of the camera representation, the proposed method effectively separates scene-unrelated information from the 3D scene representation. Additionally, during the optimization of the photometric parameters, we introduce a depth regularization to prevent the 3D scene representation from fitting scene-unrelated information. By incorporating the camera model as part of the mapping process, the proposed method constructs a complete map that includes both the scene radiance field and the camera photometric model. Experimental results demonstrate that the proposed method can achieve high-quality 3D scene representations, even under conditions of imaging degradation, such as vignetting and dirt.
SLC$^2$-SLAM: Semantic-guided Loop Closure with Shared Latent Code for NeRF SLAM
Jan 15, 2025



Targeting the notorious cumulative drift errors in NeRF SLAM, we propose a Semantic-guided Loop Closure with Shared Latent Code, dubbed SLC$^2$-SLAM. Especially, we argue that latent codes stored in many NeRF SLAM systems are not fully exploited, as they are only used for better reconstruction. In this paper, we propose a simple yet effective way to detect potential loops using the same latent codes as local features. To further improve the loop detection performance, we use the semantic information, which are also decoded from the same latent codes to guide the aggregation of local features. Finally, with the potential loops detected, we close them with a graph optimization followed by bundle adjustment to refine both the estimated poses and the reconstructed scene. To evaluate the performance of our SLC$^2$-SLAM, we conduct extensive experiments on Replica and ScanNet datasets. Our proposed semantic-guided loop closure significantly outperforms the pre-trained NetVLAD and ORB combined with Bag-of-Words, which are used in all the other NeRF SLAM with loop closure. As a result, our SLC$^2$-SLAM also demonstrated better tracking and reconstruction performance, especially in larger scenes with more loops, like ScanNet.
KALE-LM: Unleash The Power Of AI For Science Via Knowledge And Logic Enhanced Large Model
Sep 27, 2024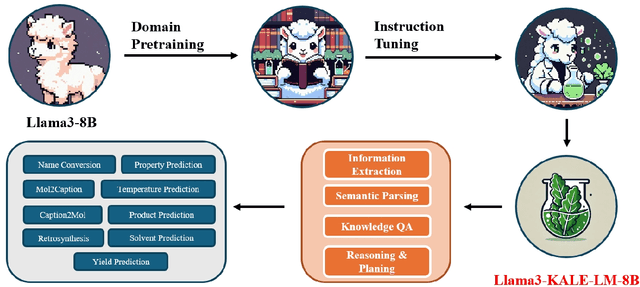
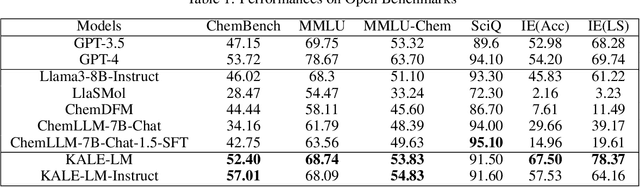
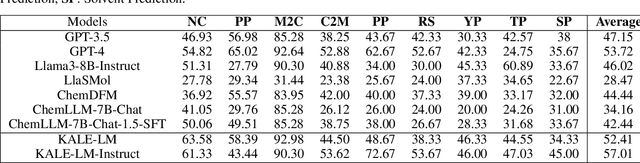
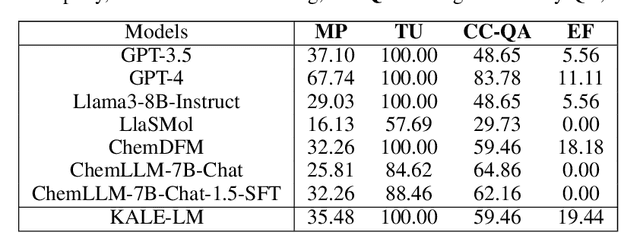
Artificial intelligence is gradually demonstrating its immense potential, and increasing attention is being given to how AI can be harnessed to advance scientific research. In this vision paper, we present our perspectives on how AI can better assist scientific inquiry and explore corresponding technical approach. We have proposed and open-sourced a large model of our KALE-LM model series, Llama3-KALE-LM-Chem-8B, which has achieved outstanding performance in tasks related to the field of chemistry. We hope that our work serves as a strong starting point, helping to realize more intelligent AI and promoting the advancement of human science and technology, as well as societal development.
VIPeR: Visual Incremental Place Recognition with Adaptive Mining and Lifelong Learning
Jul 31, 2024Visual place recognition (VPR) is an essential component of many autonomous and augmented/virtual reality systems. It enables the systems to robustly localize themselves in large-scale environments. Existing VPR methods demonstrate attractive performance at the cost of heavy pre-training and limited generalizability. When deployed in unseen environments, these methods exhibit significant performance drops. Targeting this issue, we present VIPeR, a novel approach for visual incremental place recognition with the ability to adapt to new environments while retaining the performance of previous environments. We first introduce an adaptive mining strategy that balances the performance within a single environment and the generalizability across multiple environments. Then, to prevent catastrophic forgetting in lifelong learning, we draw inspiration from human memory systems and design a novel memory bank for our VIPeR. Our memory bank contains a sensory memory, a working memory and a long-term memory, with the first two focusing on the current environment and the last one for all previously visited environments. Additionally, we propose a probabilistic knowledge distillation to explicitly safeguard the previously learned knowledge. We evaluate our proposed VIPeR on three large-scale datasets, namely Oxford Robotcar, Nordland, and TartanAir. For comparison, we first set a baseline performance with naive finetuning. Then, several more recent lifelong learning methods are compared. Our VIPeR achieves better performance in almost all aspects with the biggest improvement of 13.65% in average performance.
Exploring The Neural Burden In Pruned Models: An Insight Inspired By Neuroscience
Jul 27, 2024Vision Transformer and its variants have been adopted in many visual tasks due to their powerful capabilities, which also bring significant challenges in computation and storage. Consequently, researchers have introduced various compression methods in recent years, among which the pruning techniques are widely used to remove a significant fraction of the network. Therefore, these methods can reduce significant percent of the FLOPs, but often lead to a decrease in model performance. To investigate the underlying causes, we focus on the pruning methods specifically belonging to the pruning-during-training category, then drew inspiration from neuroscience and propose a new concept for artificial neural network models named Neural Burden. We investigate its impact in the model pruning process, and subsequently explore a simple yet effective approach to mitigate the decline in model performance, which can be applied to any pruning-during-training technique. Extensive experiments indicate that the neural burden phenomenon indeed exists, and show the potential of our method. We hope that our findings can provide valuable insights for future research. Code will be made publicly available after this paper is published.
COEFF-KANs: A Paradigm to Address the Electrolyte Field with KANs
Jul 24, 2024To reduce the experimental validation workload for chemical researchers and accelerate the design and optimization of high-energy-density lithium metal batteries, we aim to leverage models to automatically predict Coulombic Efficiency (CE) based on the composition of liquid electrolytes. There are mainly two representative paradigms in existing methods: machine learning and deep learning. However, the former requires intelligent input feature selection and reliable computational methods, leading to error propagation from feature estimation to model prediction, while the latter (e.g. MultiModal-MoLFormer) faces challenges of poor predictive performance and overfitting due to limited diversity in augmented data. To tackle these issues, we propose a novel method COEFF (COlumbic EFficiency prediction via Fine-tuned models), which consists of two stages: pre-training a chemical general model and fine-tuning on downstream domain data. Firstly, we adopt the publicly available MoLFormer model to obtain feature vectors for each solvent and salt in the electrolyte. Then, we perform a weighted average of embeddings for each token across all molecules, with weights determined by the respective electrolyte component ratios. Finally, we input the obtained electrolyte features into a Multi-layer Perceptron or Kolmogorov-Arnold Network to predict CE. Experimental results on a real-world dataset demonstrate that our method achieves SOTA for predicting CE compared to all baselines. Data and code used in this work will be made publicly available after the paper is published.
HG3-NeRF: Hierarchical Geometric, Semantic, and Photometric Guided Neural Radiance Fields for Sparse View Inputs
Jan 22, 2024Neural Radiance Fields (NeRF) have garnered considerable attention as a paradigm for novel view synthesis by learning scene representations from discrete observations. Nevertheless, NeRF exhibit pronounced performance degradation when confronted with sparse view inputs, consequently curtailing its further applicability. In this work, we introduce Hierarchical Geometric, Semantic, and Photometric Guided NeRF (HG3-NeRF), a novel methodology that can address the aforementioned limitation and enhance consistency of geometry, semantic content, and appearance across different views. We propose Hierarchical Geometric Guidance (HGG) to incorporate the attachment of Structure from Motion (SfM), namely sparse depth prior, into the scene representations. Different from direct depth supervision, HGG samples volume points from local-to-global geometric regions, mitigating the misalignment caused by inherent bias in the depth prior. Furthermore, we draw inspiration from notable variations in semantic consistency observed across images of different resolutions and propose Hierarchical Semantic Guidance (HSG) to learn the coarse-to-fine semantic content, which corresponds to the coarse-to-fine scene representations. Experimental results demonstrate that HG3-NeRF can outperform other state-of-the-art methods on different standard benchmarks and achieve high-fidelity synthesis results for sparse view inputs.
AEGIS-Net: Attention-guided Multi-Level Feature Aggregation for Indoor Place Recognition
Dec 15, 2023



We present AEGIS-Net, a novel indoor place recognition model that takes in RGB point clouds and generates global place descriptors by aggregating lower-level color, geometry features and higher-level implicit semantic features. However, rather than simple feature concatenation, self-attention modules are employed to select the most important local features that best describe an indoor place. Our AEGIS-Net is made of a semantic encoder, a semantic decoder and an attention-guided feature embedding. The model is trained in a 2-stage process with the first stage focusing on an auxiliary semantic segmentation task and the second one on the place recognition task. We evaluate our AEGIS-Net on the ScanNetPR dataset and compare its performance with a pre-deep-learning feature-based method and five state-of-the-art deep-learning-based methods. Our AEGIS-Net achieves exceptional performance and outperforms all six methods.