 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D-Augmented Contrastive Knowledge Distillation for Image-based Object Pose Estimation
Paper and Code
Jun 02, 2022
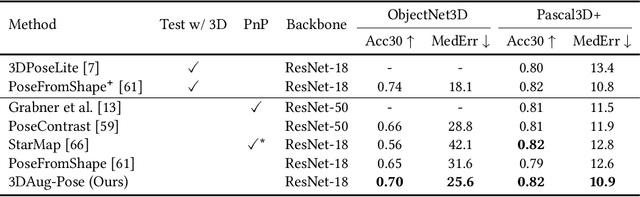
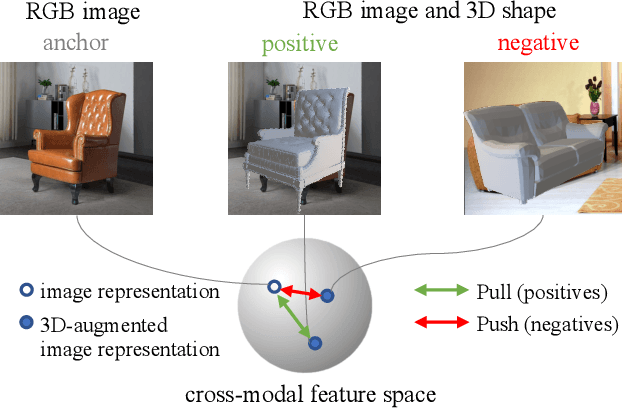
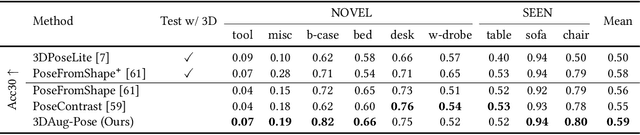
Image-based object pose estimation sounds amazing because in real applications the shape of object is oftentimes not available or not easy to take like photos. Although it is an advantage to some extent, un-explored shape information in 3D vision learning problem looks like "flaws in jade". In this paper, we deal with the problem in a reasonable new setting, namely 3D shape is exploited in the training process, and the testing is still purely image-based. We enhance the performance of image-based methods for category-agnostic object pose estimation by exploiting 3D knowledge learned by a multi-modal method. Specifically, we propose a novel contrastive knowledge distillation framework that effectively transfers 3D-augmented image representation from a multi-modal model to an image-based model. We integrate contrastive learning into the two-stage training procedure of knowledge distillation, which formulates an advanced solution to combine these two approaches for cross-modal tasks. We experimentally report state-of-the-art results compared with existing category-agnostic image-based methods by a large margin (up to +5% improvement on ObjectNet3D dataset), demonstrating the effectiveness of our method.