 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAIL-Embedding Technical Report: Omni-modal Embedding Foundation Model
Oct 14, 2025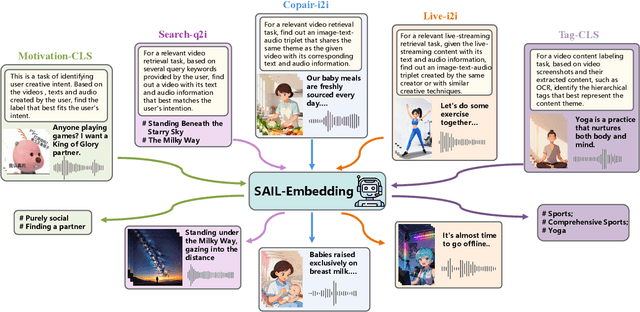

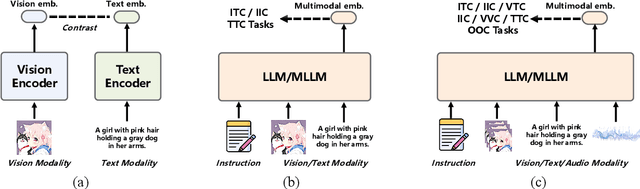
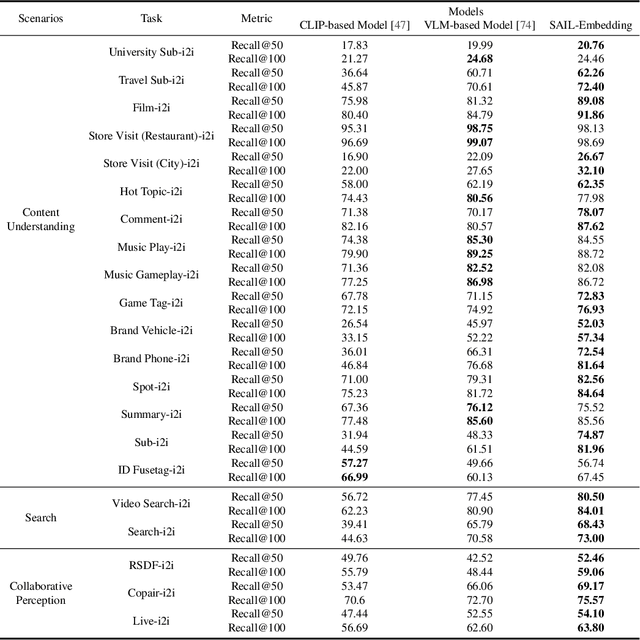
Multimodal embedding models aim to yield informative unified representations that empower diverse cross-modal tasks. Despite promising developments in the evolution from CLIP-based dual-tower architectures to large vision-language models, prior works still face unavoidable challenges in real-world applications and business scenarios, such as the limited modality support, unstable training mechanisms, and industrial domain gaps. In this work, we introduce SAIL-Embedding, an omni-modal embedding foundation model that addresses these issues through tailored training strategies and architectural design. In the optimization procedure, we propose a multi-stage training scheme to boost the multifaceted effectiveness of representation learning. Specifically, the content-aware progressive training aims to enhance the model's adaptability to diverse downstream tasks and master enriched cross-modal proficiency. The collaboration-aware recommendation enhancement training further adapts multimodal representations for recommendation scenarios by distilling knowledge from sequence-to-item and ID-to-item embeddings while mining user historical interests. Concurrently, we develop the stochastic specialization and dataset-driven pattern matching to strengthen model training flexibility and generalizability. Experimental results show that SAIL-Embedding achieves SOTA performance compared to other methods in different retrieval tasks. In online experiments across various real-world scenarios integrated with our model, we observe a significant increase in Lifetime (LT), which is a crucial indicator for the recommendation experience. For instance, the model delivers the 7-day LT gain of +0.158% and the 14-day LT gain of +0.144% in the Douyin-Selected scenario. For the Douyin feed rank model, the match features produced by SAIL-Embedding yield a +0.08% AUC gain.
TouchTTS: An Embarrassingly Simple TTS Framework that Everyone Can Touch
Dec 12, 2024It is well known that LLM-based systems are data-hungry. Recent LLM-based TTS works typically employ complex data processing pipelines to obtain high-quality training data. These sophisticated pipelines require excellent models at each stage (e.g., speech denoising, speech enhancement, speaker diarization, and punctuation models), which themselves demand high-quality training data and are rarely open-sourced. Even with state-of-the-art models, issues persist, such as incomplete background noise removal and misalignment between punctuation and actual speech pauses. Moreover, the stringent filtering strategies often retain only 10-30\% of the original data, significantly impeding data scaling efforts. In this work, we leverage a noise-robust audio tokenizer (S3Tokenizer) to design a simplified yet effective TTS data processing pipeline that maintains data quality while substantially reducing data acquisition costs, achieving a data retention rate of over 50\%. Beyond data scaling challenges, LLM-based TTS systems also incur higher deployment costs compared to conventional approaches. Current systems typically use LLMs solely for text-to-token generation, while requiring separate models (e.g., flow matching models) for token-to-waveform generation, which cannot be directly executed by LLM inference engines, further complicating deployment. To address these challenges, we eliminate redundant modules in both LLM and flow components, replacing the flow model backbone with an LLM architecture. Building upon this simplified flow backbone, we propose a unified architecture for both streaming and non-streaming inference, significantly reducing deployment costs. Finally, we explore the feasibility of unifying TTS and ASR tasks using the same data for training, thanks to the simplified pipeline and the S3Tokenizer that reduces the quality requirements for TTS training data.
The GUA-Speech System Description for CNVSRC Challenge 2023
Dec 12, 2023


This study describes our system for Task 1 Single-speaker Visual Speech Recognition (VSR) fixed track in the Chinese Continuous Visual Speech Recognition Challenge (CNVSRC) 2023. Specifically, we use intermediate connectionist temporal classification (Inter CTC) residual modules to relax the conditional independence assumption of CTC in our model. Then we use a bi-transformer decoder to enable the model to capture both past and future contextual information. In addition, we use Chinese characters as the modeling units to improve the recognition accuracy of our model. Finally, we use a recurrent neural network language model (RNNLM) for shallow fusion in the inference stage. Experiments show that our system achieves a character error rate (CER) of 38.09% on the Eval set which reaches a relative CER reduction of 21.63% over the official baseline, and obtains a second place in the challenge.
Fast-U2++: Fast and Accurate End-to-End Speech Recognition in Joint CTC/Attention Frames
Nov 02, 2022Recently, the unified streaming and non-streaming two-pass (U2/U2++) end-to-end model for speech recognition has shown great performance in terms of streaming capability, accuracy and latency. In this paper, we present fast-U2++, an enhanced version of U2++ to further reduce partial latency. The core idea of fast-U2++ is to output partial results of the bottom layers in its encoder with a small chunk, while using a large chunk in the top layers of its encoder to compensate the performance degradation caused by the small chunk. Moreover, we use knowledge distillation method to reduce the token emission latency. We present extensive experiments on Aishell-1 dataset. Experiments and ablation studies show that compared to U2++, fast-U2++ reduces model latency from 320ms to 80ms, and achieves a character error rate (CER) of 5.06% with a streaming setup.
Conformer-based End-to-end Speech Recognition With Rotary Position Embedding
Jul 13, 2021
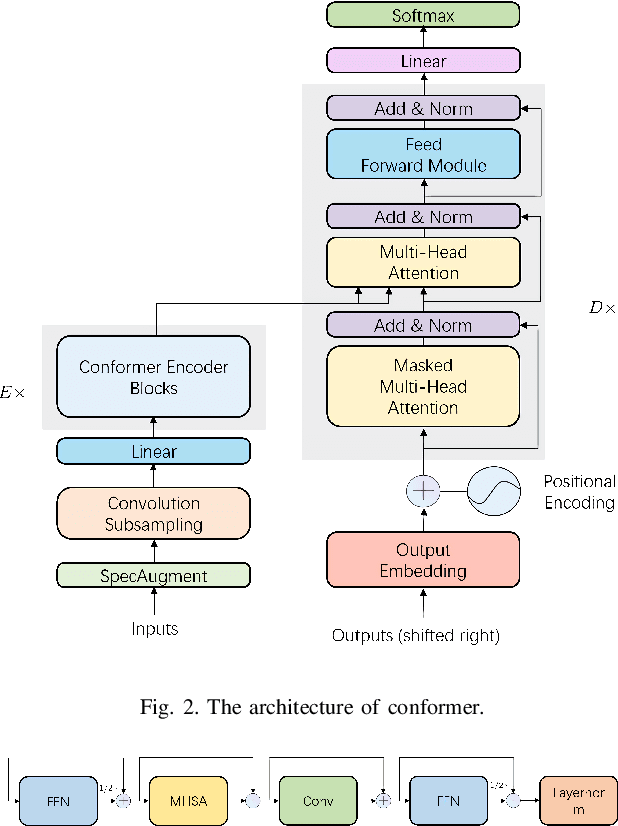


Transformer-based end-to-end speech recognition models have received considerable attention in recent years due to their high training speed and ability to model a long-range global context. Position embedding in the transformer architecture is indispensable because it provides supervision for dependency modeling between elements at different positions in the input sequence. To make use of the time order of the input sequence, many works inject some information about the relative or absolute position of the element into the input sequence. In this work, we investigate various position embedding methods in the convolution-augmented transformer (conformer) and adopt a novel implementation named rotary position embedding (RoPE). RoPE encodes absolute positional information into the input sequence by a rotation matrix, and then naturally incorporates explicit relative position information into a self-attention module. To evaluate the effectiveness of the RoPE method, we conducted experiments on AISHELL-1 and LibriSpeech corpora. Results show that the conformer enhanced with RoPE achieves superior performance in the speech recognition task. Specifically, our model achieves a relative word error rate reduction of 8.70% and 7.27% over the conformer on test-clean and test-other sets of the LibriSpeech corpus respectively.
AUC Optimization for Robust Small-footprint Keyword Spotting with Limited Training Data
Jul 13, 2021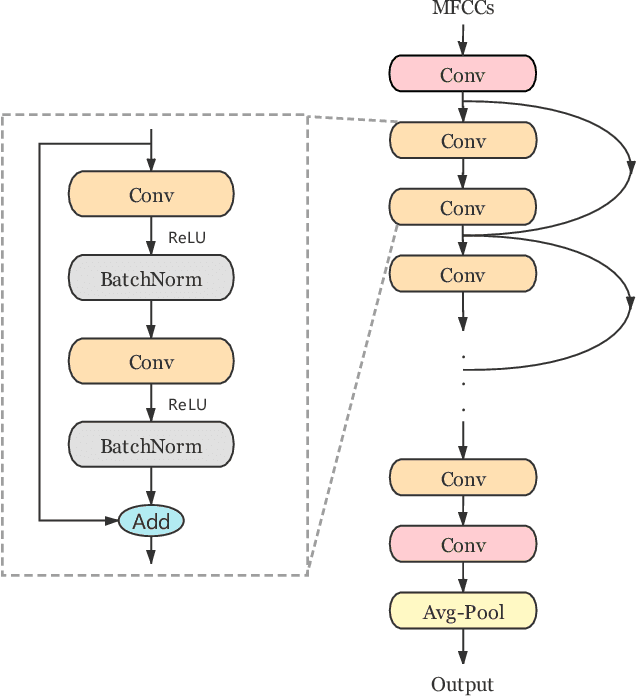

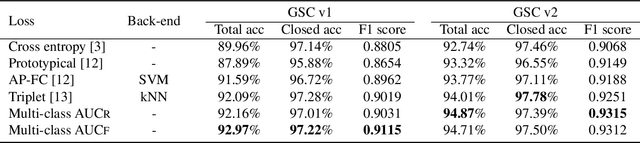

Deep neural networks provide effective solutions to small-footprint keyword spotting (KWS). However, if training data is limited, it remains challenging to achieve robust and highly accurate KWS in real-world scenarios where unseen sounds that are out of the training data are frequently encountered. Most conventional methods aim to maximize the classification accuracy on the training set, without taking the unseen sounds into account. To enhance the robustness of the deep neural networks based KWS, in this paper, we introduce a new loss function, named the maximization of the area under the receiver-operating-characteristic curve (AUC). The proposed method not only maximizes the classification accuracy of keywords on the closed training set, but also maximizes the AUC score for optimizing the performance of non-keyword segments detection. Experimental results on the Google Speech Commands dataset v1 and v2 show that our method achieves new state-of-the-art performance in terms of most evaluation metrics.
Efficient conformer-based speech recognition with linear attention
Apr 14, 2021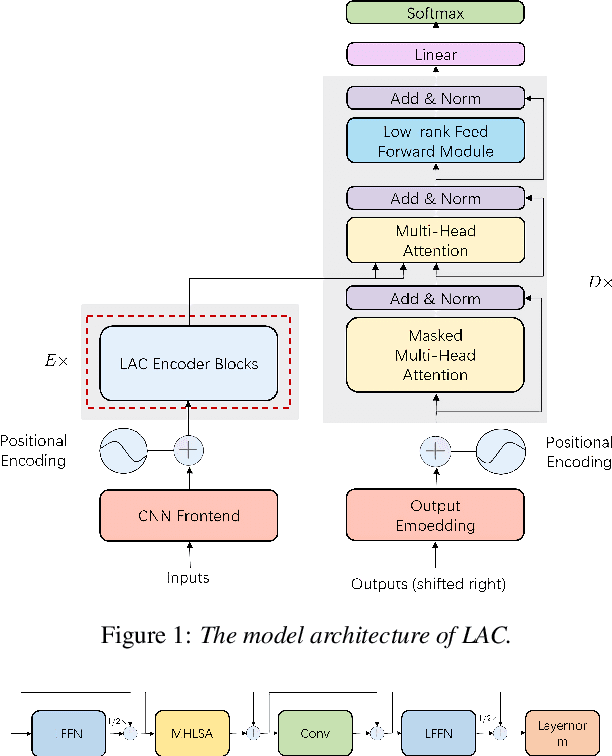


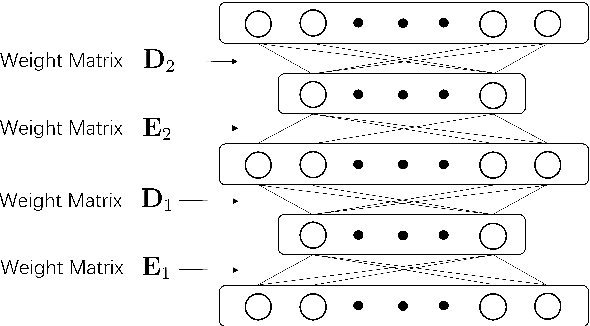
Recently, conformer-based end-to-end automatic speech recognition, which outperforms recurrent neural network based ones, has received much attention. Although the parallel computing of conformer is more efficient than recurrent neural networks, the computational complexity of its dot-product self-attention is quadratic with respect to the length of the input feature. To reduce the computational complexity of the self-attention layer, we propose multi-head linear self-attention for the self-attention layer, which reduces its computational complexity to linear order. In addition, we propose to factorize the feed forward module of the conformer by low-rank matrix factorization, which successfully reduces the number of the parameters by approximate 50% with little performance loss. The proposed model, named linear attention based conformer (LAC), can be trained and inferenced jointly with the connectionist temporal classification objective, which further improves the performance of LAC. To evaluate the effectiveness of LAC, we conduct experiments on the AISHELL-1 and LibriSpeech corpora. Results show that the proposed LAC achieves better performance than 7 recently proposed speech recognition models, and is competitive with the state-of-the-art conformer. Meanwhile, the proposed LAC has a number of parameters of only 50% over the conformer with faster training speed than the latter.
Libri-adhoc40: A dataset collected from synchronized ad-hoc microphone arrays
Apr 07, 2021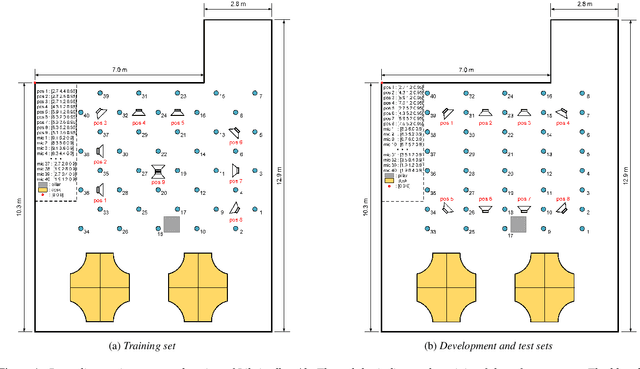
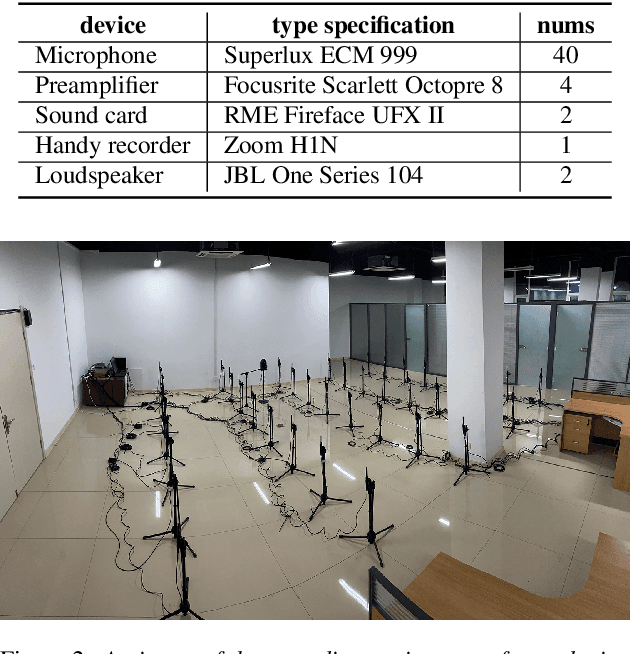
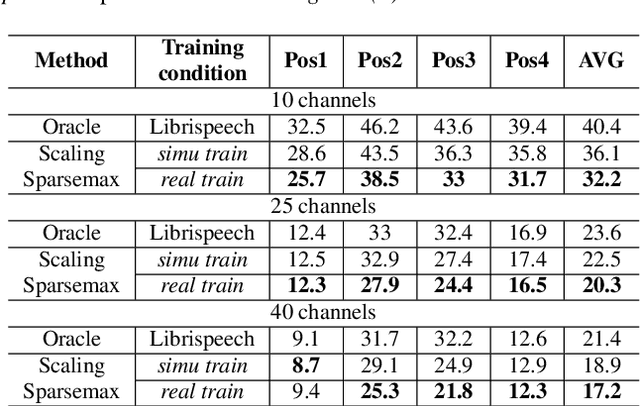

Recently, there is a research trend on ad-hoc microphone arrays. However, most research was conducted on simulated data. Although some data sets were collected with a small number of distributed devices, they were not synchronized which hinders the fundamental theoretical research to ad-hoc microphone arrays. To address this issue, this paper presents a synchronized speech corpus, named Libri-adhoc40, which collects the replayed Librispeech data from loudspeakers by ad-hoc microphone arrays of 40 strongly synchronized distributed nodes in a real office environment. Besides, to provide the evaluation target for speech frontend processing and other applications, we also recorded the replayed speech in an anechoic chamber. We trained several multi-device speech recognition systems on both the Libri-adhoc40 dataset and a simulated dataset. Experimental results demonstrate the validness of the proposed corpus which can be used as a benchmark to reflect the trend and difference of the models with different ad-hoc microphone arrays. The dataset is online available at https://github.com/ISmallFish/Libri-adhoc40.
Transformer-based End-to-End Speech Recognition with Local Dense Synthesizer Attention
Oct 23, 2020


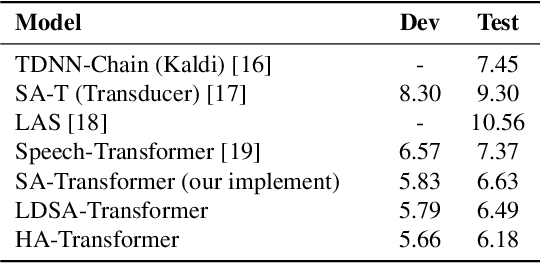
Recently, several studies reported that dot-product selfattention (SA) may not be indispensable to the state-of-theart Transformer models. Motivated by the fact that dense synthesizer attention (DSA), which dispenses with dot products and pairwise interactions, achieved competitive results in many language processing tasks, in this paper, we first propose a DSA-based speech recognition, as an alternative to SA. To reduce the computational complexity and improve the performance, we further propose local DSA (LDSA) to restrict the attention scope of DSA to a local range around the current central frame for speech recognition. Finally, we combine LDSA with SA to extract the local and global information simultaneously. Experimental results on the Ai-shell1 Mandarine speech recognition corpus show that the proposed LDSA-Transformer achieves a character error rate (CER) of 6.49%, which is slightly better than that of the SA-Transformer. Meanwhile, the LDSA-Transformer requires less computation than the SATransformer. The proposed combination method not only achieves a CER of 6.18%, which significantly outperforms the SA-Transformer, but also has roughly the same number of parameters and computational complexity as the latter. The implementation of the multi-head LDSA is available at https://github.com/mlxu995/multihead-LDSA.