 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformer-based End-to-End Speech Recognition with Local Dense Synthesizer Attention
Paper and Code



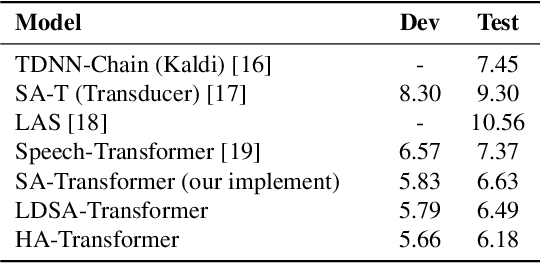
Recently, several studies reported that dot-product selfattention (SA) may not be indispensable to the state-of-theart Transformer models. Motivated by the fact that dense synthesizer attention (DSA), which dispenses with dot products and pairwise interactions, achieved competitive results in many language processing tasks, in this paper, we first propose a DSA-based speech recognition, as an alternative to SA. To reduce the computational complexity and improve the performance, we further propose local DSA (LDSA) to restrict the attention scope of DSA to a local range around the current central frame for speech recognition. Finally, we combine LDSA with SA to extract the local and global information simultaneously. Experimental results on the Ai-shell1 Mandarine speech recognition corpus show that the proposed LDSA-Transformer achieves a character error rate (CER) of 6.49%, which is slightly better than that of the SA-Transformer. Meanwhile, the LDSA-Transformer requires less computation than the SATransformer. The proposed combination method not only achieves a CER of 6.18%, which significantly outperforms the SA-Transformer, but also has roughly the same number of parameters and computational complexity as the latter. The implementation of the multi-head LDSA is available at https://github.com/mlxu995/multihead-LDSA.