 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTouchASP: Elastic Automatic Speech Perception that Everyone Can Touch
Dec 20, 2024



Large Automatic Speech Recognition (ASR) models demand a vast number of parameters, copious amounts of data, and significant computational resources during the training process. However, such models can merely be deployed on high-compute cloud platforms and are only capable of performing speech recognition tasks. This leads to high costs and restricted capabilities. In this report, we initially propose the elastic mixture of the expert (eMoE) model. This model can be trained just once and then be elastically scaled in accordance with deployment requirements. Secondly, we devise an unsupervised data creation and validation procedure and gather millions of hours of audio data from diverse domains for training. Using these two techniques, our system achieves elastic deployment capabilities while reducing the Character Error Rate (CER) on the SpeechIO testsets from 4.98\% to 2.45\%. Thirdly, our model is not only competent in Mandarin speech recognition but also proficient in multilingual, multi-dialect, emotion, gender, and sound event perception. We refer to this as Automatic Speech Perception (ASP), and the perception results are presented in the experimental section.
TouchTTS: An Embarrassingly Simple TTS Framework that Everyone Can Touch
Dec 12, 2024It is well known that LLM-based systems are data-hungry. Recent LLM-based TTS works typically employ complex data processing pipelines to obtain high-quality training data. These sophisticated pipelines require excellent models at each stage (e.g., speech denoising, speech enhancement, speaker diarization, and punctuation models), which themselves demand high-quality training data and are rarely open-sourced. Even with state-of-the-art models, issues persist, such as incomplete background noise removal and misalignment between punctuation and actual speech pauses. Moreover, the stringent filtering strategies often retain only 10-30\% of the original data, significantly impeding data scaling efforts. In this work, we leverage a noise-robust audio tokenizer (S3Tokenizer) to design a simplified yet effective TTS data processing pipeline that maintains data quality while substantially reducing data acquisition costs, achieving a data retention rate of over 50\%. Beyond data scaling challenges, LLM-based TTS systems also incur higher deployment costs compared to conventional approaches. Current systems typically use LLMs solely for text-to-token generation, while requiring separate models (e.g., flow matching models) for token-to-waveform generation, which cannot be directly executed by LLM inference engines, further complicating deployment. To address these challenges, we eliminate redundant modules in both LLM and flow components, replacing the flow model backbone with an LLM architecture. Building upon this simplified flow backbone, we propose a unified architecture for both streaming and non-streaming inference, significantly reducing deployment costs. Finally, we explore the feasibility of unifying TTS and ASR tasks using the same data for training, thanks to the simplified pipeline and the S3Tokenizer that reduces the quality requirements for TTS training data.
U2++ MoE: Scaling 4.7x parameters with minimal impact on RTF
Apr 25, 2024



Scale has opened new frontiers in natural language processing, but at a high cost. In response, by learning to only activate a subset of parameters in training and inference, Mixture-of-Experts (MoE) have been proposed as an energy efficient path to even larger and more capable language models and this shift towards a new generation of foundation models is gaining momentum, particularly within the field of Automatic Speech Recognition (ASR). Recent works that incorporating MoE into ASR models have complex designs such as routing frames via supplementary embedding network, improving multilingual ability for the experts, and utilizing dedicated auxiliary losses for either expert load balancing or specific language handling. We found that delicate designs are not necessary, while an embarrassingly simple substitution of MoE layers for all Feed-Forward Network (FFN) layers is competent for the ASR task. To be more specific, we benchmark our proposed model on a large scale inner-source dataset (160k hours), the results show that we can scale our baseline Conformer (Dense-225M) to its MoE counterparts (MoE-1B) and achieve Dense-1B level Word Error Rate (WER) while maintaining a Dense-225M level Real Time Factor (RTF). Furthermore, by applying Unified 2-pass framework with bidirectional attention decoders (U2++), we achieve the streaming and non-streaming decoding modes in a single MoE based model, which we call U2++ MoE. We hope that our study can facilitate the research on scaling speech foundation models without sacrificing deployment efficiency.
The GUA-Speech System Description for CNVSRC Challenge 2023
Dec 12, 2023


This study describes our system for Task 1 Single-speaker Visual Speech Recognition (VSR) fixed track in the Chinese Continuous Visual Speech Recognition Challenge (CNVSRC) 2023. Specifically, we use intermediate connectionist temporal classification (Inter CTC) residual modules to relax the conditional independence assumption of CTC in our model. Then we use a bi-transformer decoder to enable the model to capture both past and future contextual information. In addition, we use Chinese characters as the modeling units to improve the recognition accuracy of our model. Finally, we use a recurrent neural network language model (RNNLM) for shallow fusion in the inference stage. Experiments show that our system achieves a character error rate (CER) of 38.09% on the Eval set which reaches a relative CER reduction of 21.63% over the official baseline, and obtains a second place in the challenge.
LightGrad: Lightweight Diffusion Probabilistic Model for Text-to-Speech
Aug 31, 2023


Recent advances in neural text-to-speech (TTS) models bring thousands of TTS applications into daily life, where models are deployed in cloud to provide services for customs. Among these models are diffusion probabilistic models (DPMs), which can be stably trained and are more parameter-efficient compared with other generative models. As transmitting data between customs and the cloud introduces high latency and the risk of exposing private data, deploying TTS models on edge devices is preferred. When implementing DPMs onto edge devices, there are two practical problems. First, current DPMs are not lightweight enough for resource-constrained devices. Second, DPMs require many denoising steps in inference, which increases latency. In this work, we present LightGrad, a lightweight DPM for TTS. LightGrad is equipped with a lightweight U-Net diffusion decoder and a training-free fast sampling technique, reducing both model parameters and inference latency. Streaming inference is also implemented in LightGrad to reduce latency further. Compared with Grad-TTS, LightGrad achieves 62.2% reduction in paramters, 65.7% reduction in latency, while preserving comparable speech quality on both Chinese Mandarin and English in 4 denoising steps.
ZeroPrompt: Streaming Acoustic Encoders are Zero-Shot Masked LMs
May 18, 2023In this paper, we present ZeroPrompt (Figure 1-(a)) and the corresponding Prompt-and-Refine strategy (Figure 3), two simple but effective \textbf{training-free} methods to decrease the Token Display Time (TDT) of streaming ASR models \textbf{without any accuracy loss}. The core idea of ZeroPrompt is to append zeroed content to each chunk during inference, which acts like a prompt to encourage the model to predict future tokens even before they were spoken. We argue that streaming acoustic encoders naturally have the modeling ability of Masked Language Models and our experiments demonstrate that ZeroPrompt is engineering cheap and can be applied to streaming acoustic encoders on any dataset without any accuracy loss. Specifically, compared with our baseline models, we achieve 350 $\sim$ 700ms reduction on First Token Display Time (TDT-F) and 100 $\sim$ 400ms reduction on Last Token Display Time (TDT-L), with theoretically and experimentally equal WER on both Aishell-1 and Librispeech datasets.
Fast-U2++: Fast and Accurate End-to-End Speech Recognition in Joint CTC/Attention Frames
Nov 02, 2022Recently, the unified streaming and non-streaming two-pass (U2/U2++) end-to-end model for speech recognition has shown great performance in terms of streaming capability, accuracy and latency. In this paper, we present fast-U2++, an enhanced version of U2++ to further reduce partial latency. The core idea of fast-U2++ is to output partial results of the bottom layers in its encoder with a small chunk, while using a large chunk in the top layers of its encoder to compensate the performance degradation caused by the small chunk. Moreover, we use knowledge distillation method to reduce the token emission latency. We present extensive experiments on Aishell-1 dataset. Experiments and ablation studies show that compared to U2++, fast-U2++ reduces model latency from 320ms to 80ms, and achieves a character error rate (CER) of 5.06% with a streaming setup.
TrimTail: Low-Latency Streaming ASR with Simple but Effective Spectrogram-Level Length Penalty
Nov 01, 2022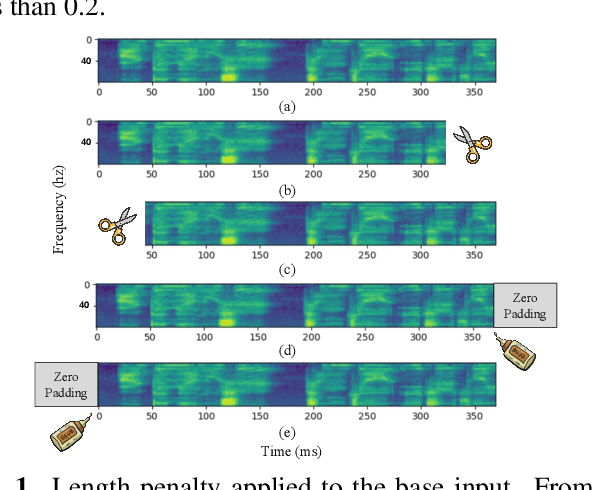



In this paper, we present TrimTail, a simple but effective emission regularization method to improve the latency of streaming ASR models. The core idea of TrimTail is to apply length penalty (i.e., by trimming trailing frames, see Fig. 1-(b)) directly on the spectrogram of input utterances, which does not require any alignment. We demonstrate that TrimTail is computationally cheap and can be applied online and optimized with any training loss or any model architecture on any dataset without any extra effort by applying it on various end-to-end streaming ASR networks either trained with CTC loss [1] or Transducer loss [2]. We achieve 100 $\sim$ 200ms latency reduction with equal or even better accuracy on both Aishell-1 and Librispeech. Moreover, by using TrimTail, we can achieve a 400ms algorithmic improvement of User Sensitive Delay (USD) with an accuracy loss of less than 0.2.
FusionFormer: Fusing Operations in Transformer for Efficient Streaming Speech Recognition
Oct 31, 2022



The recently proposed Conformer architecture which combines convolution with attention to capture both local and global dependencies has become the \textit{de facto} backbone model for Automatic Speech Recognition~(ASR). Inherited from the Natural Language Processing (NLP) tasks, the architecture takes Layer Normalization~(LN) as a default normalization technique. However, through a series of systematic studies, we find that LN might take 10\% of the inference time despite that it only contributes to 0.1\% of the FLOPs. This motivates us to replace LN with other normalization techniques, e.g., Batch Normalization~(BN), to speed up inference with the help of operator fusion methods and the avoidance of calculating the mean and variance statistics during inference. After examining several plain attempts which directly remove all LN layers or replace them with BN in the same place, we find that the divergence issue is mainly caused by the unstable layer output. We therefore propose to append a BN layer to each linear or convolution layer where stabilized training results are observed. We also propose to simplify the activations in Conformer, such as Swish and GLU, by replacing them with ReLU. All these exchanged modules can be fused into the weights of the adjacent linear/convolution layers and hence have zero inference cost. Therefore, we name it FusionFormer. Our experiments indicate that FusionFormer is as effective as the LN-based Conformer and is about 10\% faster.
WeKws: A production first small-footprint end-to-end Keyword Spotting Toolkit
Oct 30, 2022



Keyword spotting (KWS) enables speech-based user interaction and gradually becomes an indispensable component of smart devices. Recently, end-to-end (E2E) methods have become the most popular approach for on-device KWS tasks. However, there is still a gap between the research and deployment of E2E KWS methods. In this paper, we introduce WeKws, a production-quality, easy-to-build, and convenient-to-be-applied E2E KWS toolkit. WeKws contains the implementations of several state-of-the-art backbone networks, making it achieve highly competitive results on three publicly available datasets. To make WeKws a pure E2E toolkit, we utilize a refined max-pooling loss to make the model learn the ending position of the keyword by itself, which significantly simplifies the training pipeline and makes WeKws very efficient to be applied in real-world scenarios. The toolkit is publicly available at https://github.com/wenet-e2e/wekws.