 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Parameter-efficient Language Extension Framework for Multilingual ASR
Jun 10, 2024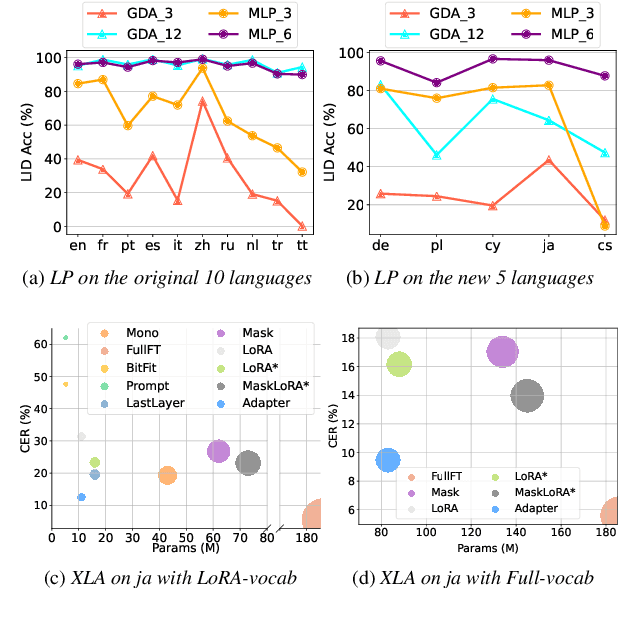
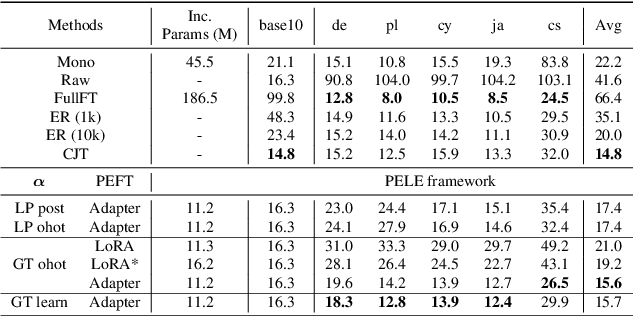
Covering all languages with a multilingual speech recognition model (MASR) is very difficult. Performing language extension on top of an existing MASR is a desirable choice. In this study, the MASR continual learning problem is probabilistically decomposed into language identity prediction (LP) and cross-lingual adaptation (XLA) sub-problems. Based on this, we propose an architecture-based framework for language extension that can fundamentally solve catastrophic forgetting, debudded as PELE. PELE is designed to be parameter-efficient, incrementally incorporating an add-on module to adapt to a new language. Specifically, different parameter-efficient fine-tuning (PEFT) modules and their variants are explored as potential candidates to perform XLA. Experiments are carried out on 5 new languages with a wide range of low-resourced data sizes. The best-performing PEFT candidate can achieve satisfactory performance across all languages and demonstrates superiority in three of five languages over the continual joint learning setting. Notably, PEFT methods focusing on weight parameters or input features are revealed to be limited in performance, showing significantly inferior extension capabilities compared to inserting a lightweight module in between layers such as an Adapter.
LUPET: Incorporating Hierarchical Information Path into Multilingual ASR
Jan 08, 2024



Many factors have separately shown their effectiveness on improving multilingual ASR. They include language identity (LID) and phoneme information, language-specific processing modules and cross-lingual self-supervised speech representation, etc. However, few studies work on synergistically combining them to contribute a unified solution, which still remains an open question. To this end, a novel view to incorporate hierarchical information path LUPET into multilingual ASR is proposed. The LUPET is a path encoding multiple information in different granularity from shallow to deep encoder layers. Early information in this path is beneficial for deriving later occurred information. Specifically, the input goes from LID prediction to acoustic unit discovery followed by phoneme sharing, and then dynamically routed by mixture-of-expert for final token recognition. Experiments on 10 languages of Common Voice examined the superior performance of LUPET. Importantly, LUPET significantly boosts the recognition on high-resource languages, thus mitigating the compromised phenomenon towards low-resource languages in a multilingual setting.
WeKws: A production first small-footprint end-to-end Keyword Spotting Toolkit
Oct 30, 2022



Keyword spotting (KWS) enables speech-based user interaction and gradually becomes an indispensable component of smart devices. Recently, end-to-end (E2E) methods have become the most popular approach for on-device KWS tasks. However, there is still a gap between the research and deployment of E2E KWS methods. In this paper, we introduce WeKws, a production-quality, easy-to-build, and convenient-to-be-applied E2E KWS toolkit. WeKws contains the implementations of several state-of-the-art backbone networks, making it achieve highly competitive results on three publicly available datasets. To make WeKws a pure E2E toolkit, we utilize a refined max-pooling loss to make the model learn the ending position of the keyword by itself, which significantly simplifies the training pipeline and makes WeKws very efficient to be applied in real-world scenarios. The toolkit is publicly available at https://github.com/wenet-e2e/wekws.
The NPU System for the 2020 Personalized Voice Trigger Challenge
Feb 26, 2021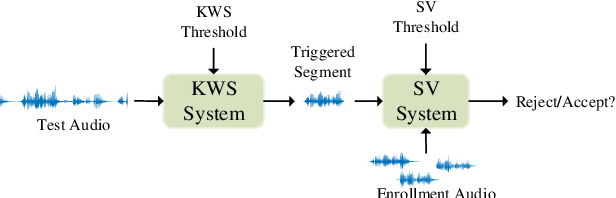
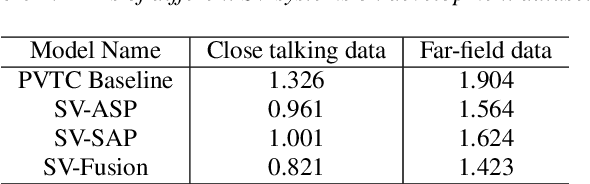
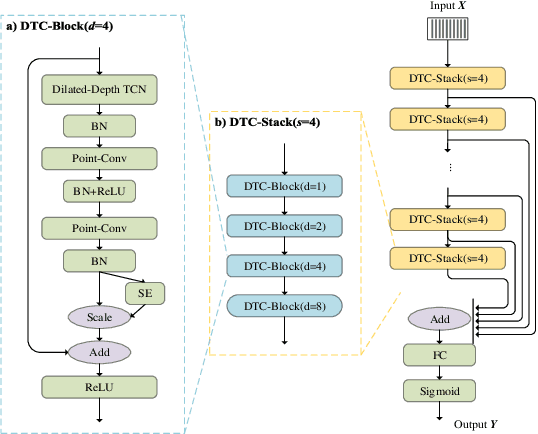

This paper describes the system developed by the NPU team for the 2020 personalized voice trigger challenge. Our submitted system consists of two independently trained subsystems: a small footprint keyword spotting (KWS) system and a speaker verification (SV) system. For the KWS system, a multi-scale dilated temporal convolutional (MDTC) network is proposed to detect wake-up word (WuW). For SV system, Write something here. The KWS predicts posterior probabilities of whether an audio utterance contains WuW and estimates the location of WuW at the same time. When the posterior probability ofWuW reaches a predefined threshold, the identity information of triggered segment is determined by the SV system. On evaluation dataset, our submitted system obtains detection costs of 0.081and 0.091 in close talking and far-field tasks, respectively.