 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Parameter-efficient Language Extension Framework for Multilingual ASR
Jun 10, 2024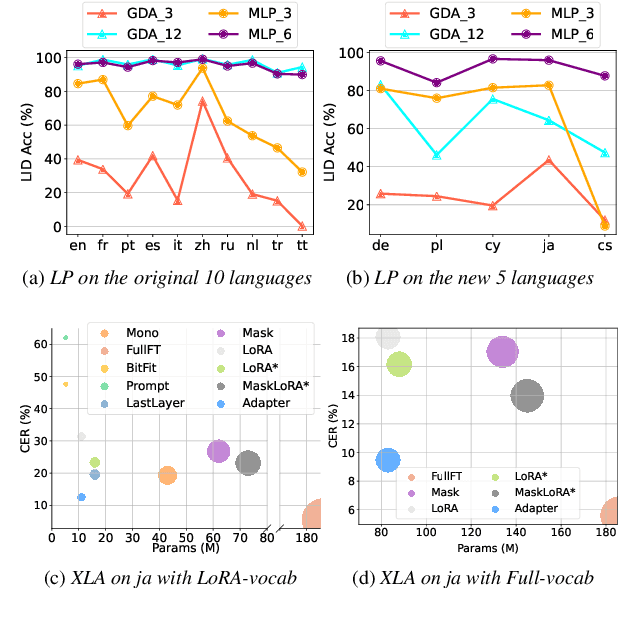
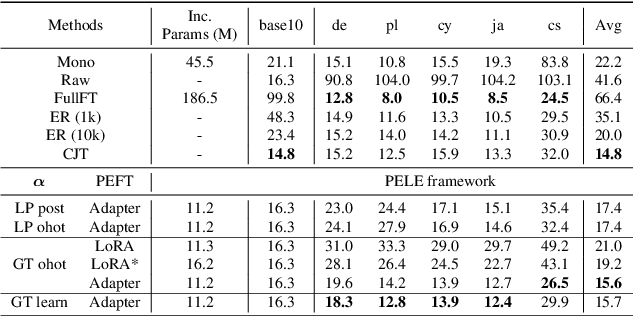
Covering all languages with a multilingual speech recognition model (MASR) is very difficult. Performing language extension on top of an existing MASR is a desirable choice. In this study, the MASR continual learning problem is probabilistically decomposed into language identity prediction (LP) and cross-lingual adaptation (XLA) sub-problems. Based on this, we propose an architecture-based framework for language extension that can fundamentally solve catastrophic forgetting, debudded as PELE. PELE is designed to be parameter-efficient, incrementally incorporating an add-on module to adapt to a new language. Specifically, different parameter-efficient fine-tuning (PEFT) modules and their variants are explored as potential candidates to perform XLA. Experiments are carried out on 5 new languages with a wide range of low-resourced data sizes. The best-performing PEFT candidate can achieve satisfactory performance across all languages and demonstrates superiority in three of five languages over the continual joint learning setting. Notably, PEFT methods focusing on weight parameters or input features are revealed to be limited in performance, showing significantly inferior extension capabilities compared to inserting a lightweight module in between layers such as an Adapter.
LUPET: Incorporating Hierarchical Information Path into Multilingual ASR
Jan 08, 2024



Many factors have separately shown their effectiveness on improving multilingual ASR. They include language identity (LID) and phoneme information, language-specific processing modules and cross-lingual self-supervised speech representation, etc. However, few studies work on synergistically combining them to contribute a unified solution, which still remains an open question. To this end, a novel view to incorporate hierarchical information path LUPET into multilingual ASR is proposed. The LUPET is a path encoding multiple information in different granularity from shallow to deep encoder layers. Early information in this path is beneficial for deriving later occurred information. Specifically, the input goes from LID prediction to acoustic unit discovery followed by phoneme sharing, and then dynamically routed by mixture-of-expert for final token recognition. Experiments on 10 languages of Common Voice examined the superior performance of LUPET. Importantly, LUPET significantly boosts the recognition on high-resource languages, thus mitigating the compromised phenomenon towards low-resource languages in a multilingual setting.
Fast Blind Audio Copy-Move Detection and Localization Using Local Feature Tensors in Noise
Feb 15, 2023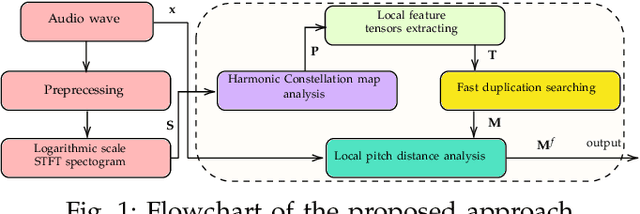
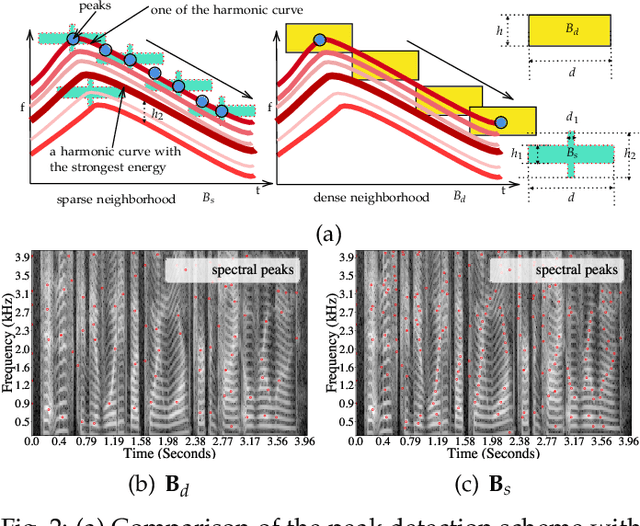
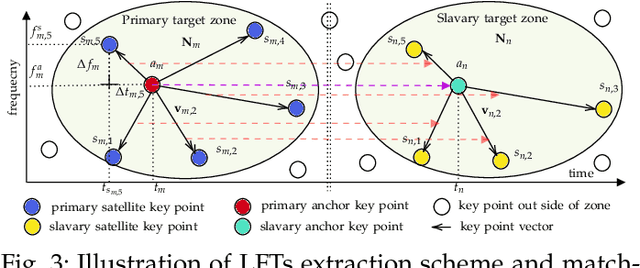
The increasing availability of audio editing software altering digital audios and their ease of use allows create forgeries at low cost. A copy-move forgery (CMF) is one of easiest and popular audio forgeries, which created by copying and pasting audio segments within the same audio, and potentially post-processing it. Three main approaches to audio copy-move detection exist nowadays: samples/frames comparison, acoustic features coherence searching and dynamic time warping. But these approaches will suffer from computational complexity and/or sensitive to noise and post-processing. In this paper, we propose a new local feature tensors-based copy-move detection algorithm that can be applied to transformed duplicates detection and localization problem to a special locality sensitive hash like procedure. The experimental results with massive online real-time audios datasets reveal that the proposed technique effectively determines and locating copy-move forgeries even on a forged speech segment are as short as fractional second. This method is also computational efficient and robust against the audios processed with severe nonlinear transformation, such as resampling, filtering, jsittering, compression and cropping, even contaminated with background noise and music. Hence, the proposed technique provides an efficient and reliable way of copy-move forgery detection that increases the credibility of audio in practical forensics applications
Low-Complexity Acoustic Echo Cancellation with Neural Kalman Filtering
Jul 23, 2022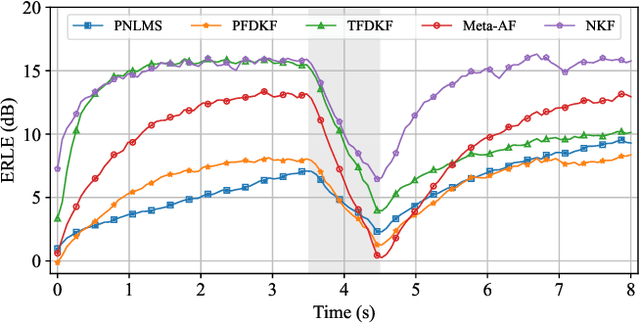

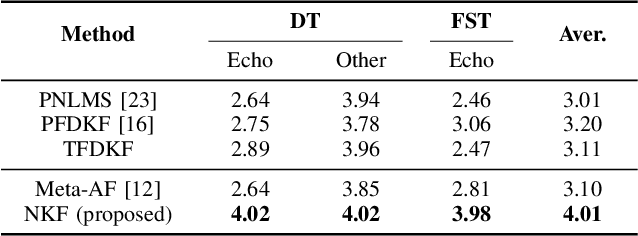
The Kalman filter has been adopted in acoustic echo cancellation due to its robustness to double-talk, fast convergence, and good steady-state performance. The performance of Kalman filter is closely related to the estimation accuracy of the state noise covariance and the observation noise covariance. The estimation error may lead to unacceptable results, especially when the echo path suffers abrupt changes, the tracking performance of the Kalman filter could be degraded significantly. In this paper, we propose the neural Kalman filtering (NKF), which uses neural networks to implicitly model the covariance of the state noise and observation noise and to output the Kalman gain in real-time. Experimental results on both synthetic test sets and real-recorded test sets show that, the proposed NKF has superior convergence and re-convergence performance while ensuring low near-end speech degradation comparing with the state-of-the-art model-based methods. Moreover, the model size of the proposed NKF is merely 5.3 K and the RTF is as low as 0.09, which indicates that it can be deployed in low-resource platforms.