 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAcoustic Scene Clustering Using Joint Optimization of Deep Embedding Learning and Clustering Iteration
Jun 09, 2023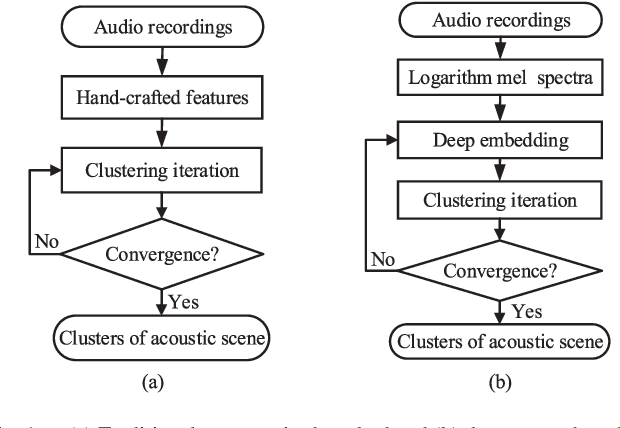
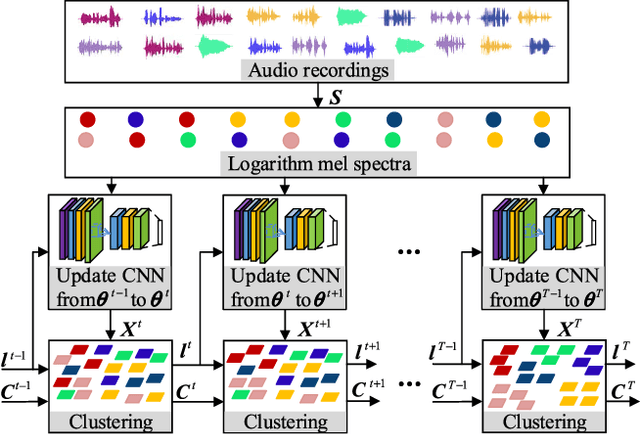
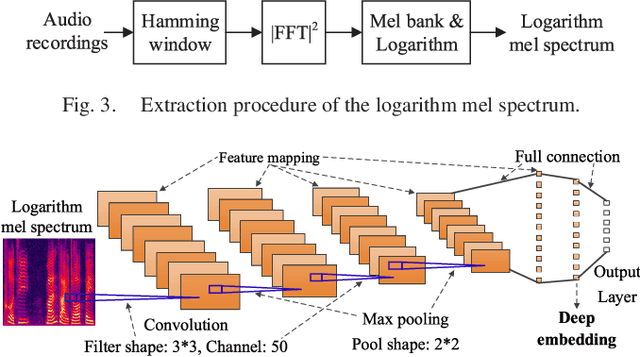
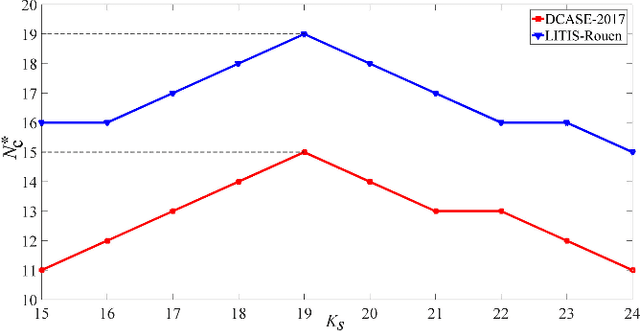
Recent efforts have been made on acoustic scene classification in the audio signal processing community. In contrast, few studies have been conducted on acoustic scene clustering, which is a newly emerging problem. Acoustic scene clustering aims at merging the audio recordings of the same class of acoustic scene into a single cluster without using prior information and training classifiers. In this study, we propose a method for acoustic scene clustering that jointly optimizes the procedures of feature learning and clustering iteration. In the proposed method, the learned feature is a deep embedding that is extracted from a deep convolutional neural network (CNN), while the clustering algorithm is the agglomerative hierarchical clustering (AHC). We formulate a unified loss function for integrating and optimizing these two procedures. Various features and methods are compared. The experimental results demonstrate that the proposed method outperforms other unsupervised methods in terms of the normalized mutual information and the clustering accuracy. In addition, the deep embedding outperforms many state-of-the-art features.
Fast Blind Audio Copy-Move Detection and Localization Using Local Feature Tensors in Noise
Feb 15, 2023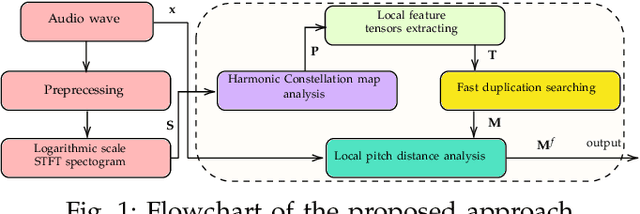
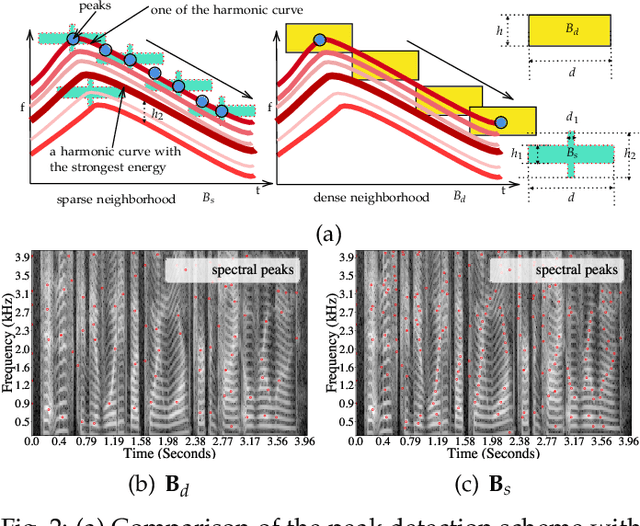
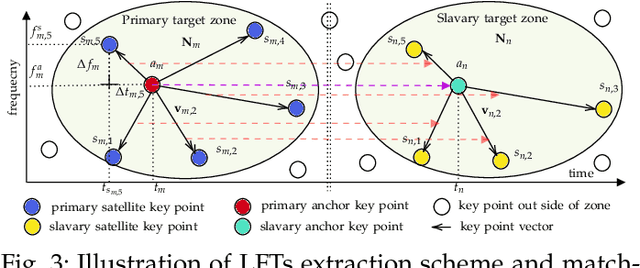
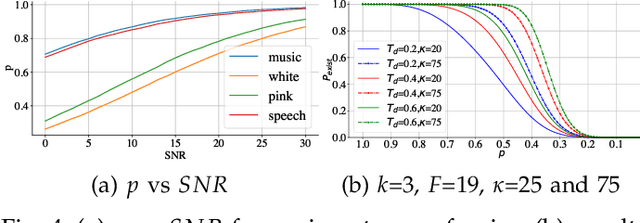
The increasing availability of audio editing software altering digital audios and their ease of use allows create forgeries at low cost. A copy-move forgery (CMF) is one of easiest and popular audio forgeries, which created by copying and pasting audio segments within the same audio, and potentially post-processing it. Three main approaches to audio copy-move detection exist nowadays: samples/frames comparison, acoustic features coherence searching and dynamic time warping. But these approaches will suffer from computational complexity and/or sensitive to noise and post-processing. In this paper, we propose a new local feature tensors-based copy-move detection algorithm that can be applied to transformed duplicates detection and localization problem to a special locality sensitive hash like procedure. The experimental results with massive online real-time audios datasets reveal that the proposed technique effectively determines and locating copy-move forgeries even on a forged speech segment are as short as fractional second. This method is also computational efficient and robust against the audios processed with severe nonlinear transformation, such as resampling, filtering, jsittering, compression and cropping, even contaminated with background noise and music. Hence, the proposed technique provides an efficient and reliable way of copy-move forgery detection that increases the credibility of audio in practical forensics applications