 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast-U2++: Fast and Accurate End-to-End Speech Recognition in Joint CTC/Attention Frames
Nov 02, 2022Recently, the unified streaming and non-streaming two-pass (U2/U2++) end-to-end model for speech recognition has shown great performance in terms of streaming capability, accuracy and latency. In this paper, we present fast-U2++, an enhanced version of U2++ to further reduce partial latency. The core idea of fast-U2++ is to output partial results of the bottom layers in its encoder with a small chunk, while using a large chunk in the top layers of its encoder to compensate the performance degradation caused by the small chunk. Moreover, we use knowledge distillation method to reduce the token emission latency. We present extensive experiments on Aishell-1 dataset. Experiments and ablation studies show that compared to U2++, fast-U2++ reduces model latency from 320ms to 80ms, and achieves a character error rate (CER) of 5.06% with a streaming setup.
Empirical Evaluation of Parallel Training Algorithms on Acoustic Modeling
Jul 26, 2017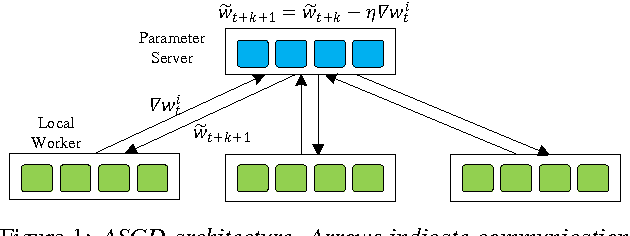

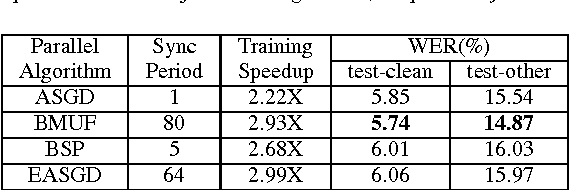
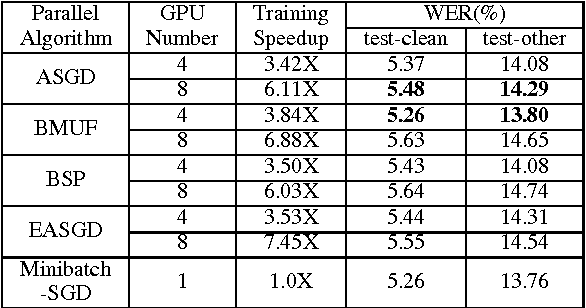
Deep learning models (DLMs) are state-of-the-art techniques in speech recognition. However, training good DLMs can be time consuming especially for production-size models and corpora. Although several parallel training algorithms have been proposed to improve training efficiency, there is no clear guidance on which one to choose for the task in hand due to lack of systematic and fair comparison among them. In this paper we aim at filling this gap by comparing four popular parallel training algorithms in speech recognition, namely asynchronous stochastic gradient descent (ASGD), blockwise model-update filtering (BMUF), bulk synchronous parallel (BSP) and elastic averaging stochastic gradient descent (EASGD), on 1000-hour LibriSpeech corpora using feed-forward deep neural networks (DNNs) and convolutional, long short-term memory, DNNs (CLDNNs). Based on our experiments, we recommend using BMUF as the top choice to train acoustic models since it is most stable, scales well with number of GPUs, can achieve reproducible results, and in many cases even outperforms single-GPU SGD. ASGD can be used as a substitute in some cases.