 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFireRedASR2S: A State-of-the-Art Industrial-Grade All-in-One Automatic Speech Recognition System
Mar 11, 2026We present FireRedASR2S, a state-of-the-art industrial-grade all-in-one automatic speech recognition (ASR) system. It integrates four modules in a unified pipeline: ASR, Voice Activity Detection (VAD), Spoken Language Identification (LID), and Punctuation Prediction (Punc). All modules achieve SOTA performance on the evaluated benchmarks: FireRedASR2: An ASR module with two variants, FireRedASR2-LLM (8B+ parameters) and FireRedASR2-AED (1B+ parameters), supporting speech and singing transcription for Mandarin, Chinese dialects and accents, English, and code-switching. Compared to FireRedASR, FireRedASR2 delivers improved recognition accuracy and broader dialect and accent coverage. FireRedASR2-LLM achieves 2.89% average CER on 4 public Mandarin benchmarks and 11.55% on 19 public Chinese dialects and accents benchmarks, outperforming competitive baselines including Doubao-ASR, Qwen3-ASR, and Fun-ASR. FireRedVAD: An ultra-lightweight module (0.6M parameters) based on the Deep Feedforward Sequential Memory Network (DFSMN), supporting streaming VAD, non-streaming VAD, and multi-label VAD (mVAD). On the FLEURS-VAD-102 benchmark, it achieves 97.57% frame-level F1 and 99.60% AUC-ROC, outperforming Silero-VAD, TEN-VAD, FunASR-VAD, and WebRTC-VAD. FireRedLID: An Encoder-Decoder LID module supporting 100+ languages and 20+ Chinese dialects and accents. On FLEURS (82 languages), it achieves 97.18% utterance-level accuracy, outperforming Whisper and SpeechBrain. FireRedPunc: A BERT-style punctuation prediction module for Chinese and English. On multi-domain benchmarks, it achieves 78.90% average F1, outperforming FunASR-Punc (62.77%). To advance research in speech processing, we release model weights and code at https://github.com/FireRedTeam/FireRedASR2S.
Federated Learning via Variational Bayesian Inference: Personalization, Sparsity and Clustering
Mar 08, 2023Federated learning (FL) is a promising framework that models distributed machine learning while protecting the privacy of clients. However, FL suffers performance degradation from heterogeneous and limited data. To alleviate the degradation, we present a novel personalized Bayesian FL approach named pFedBayes. By using the trained global distribution from the server as the prior distribution of each client, each client adjusts its own distribution by minimizing the sum of the reconstruction error over its personalized data and the KL divergence with the downloaded global distribution. Then, we propose a sparse personalized Bayesian FL approach named sFedBayes. To overcome the extreme heterogeneity in non-i.i.d. data, we propose a clustered Bayesian FL model named cFedbayes by learning different prior distributions for different clients. Theoretical analysis gives the generalization error bound of three approaches and shows that the generalization error convergence rates of the proposed approaches achieve minimax optimality up to a logarithmic factor. Moreover, the analysis presents that cFedbayes has a tighter generalization error rate than pFedBayes. Numerous experiments are provided to demonstrate that the proposed approaches have better performance than other advanced personalized methods on private models in the presence of heterogeneous and limited data.
TrimTail: Low-Latency Streaming ASR with Simple but Effective Spectrogram-Level Length Penalty
Nov 01, 2022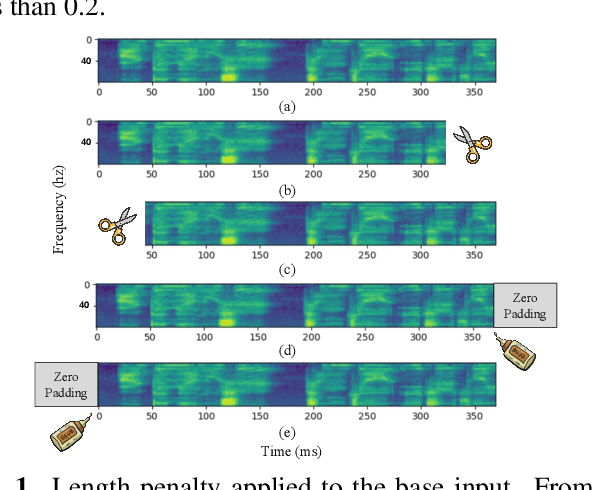



In this paper, we present TrimTail, a simple but effective emission regularization method to improve the latency of streaming ASR models. The core idea of TrimTail is to apply length penalty (i.e., by trimming trailing frames, see Fig. 1-(b)) directly on the spectrogram of input utterances, which does not require any alignment. We demonstrate that TrimTail is computationally cheap and can be applied online and optimized with any training loss or any model architecture on any dataset without any extra effort by applying it on various end-to-end streaming ASR networks either trained with CTC loss [1] or Transducer loss [2]. We achieve 100 $\sim$ 200ms latency reduction with equal or even better accuracy on both Aishell-1 and Librispeech. Moreover, by using TrimTail, we can achieve a 400ms algorithmic improvement of User Sensitive Delay (USD) with an accuracy loss of less than 0.2.
FusionFormer: Fusing Operations in Transformer for Efficient Streaming Speech Recognition
Oct 31, 2022



The recently proposed Conformer architecture which combines convolution with attention to capture both local and global dependencies has become the \textit{de facto} backbone model for Automatic Speech Recognition~(ASR). Inherited from the Natural Language Processing (NLP) tasks, the architecture takes Layer Normalization~(LN) as a default normalization technique. However, through a series of systematic studies, we find that LN might take 10\% of the inference time despite that it only contributes to 0.1\% of the FLOPs. This motivates us to replace LN with other normalization techniques, e.g., Batch Normalization~(BN), to speed up inference with the help of operator fusion methods and the avoidance of calculating the mean and variance statistics during inference. After examining several plain attempts which directly remove all LN layers or replace them with BN in the same place, we find that the divergence issue is mainly caused by the unstable layer output. We therefore propose to append a BN layer to each linear or convolution layer where stabilized training results are observed. We also propose to simplify the activations in Conformer, such as Swish and GLU, by replacing them with ReLU. All these exchanged modules can be fused into the weights of the adjacent linear/convolution layers and hence have zero inference cost. Therefore, we name it FusionFormer. Our experiments indicate that FusionFormer is as effective as the LN-based Conformer and is about 10\% faster.
Personalized Federated Learning via Variational Bayesian Inference
Jun 16, 2022
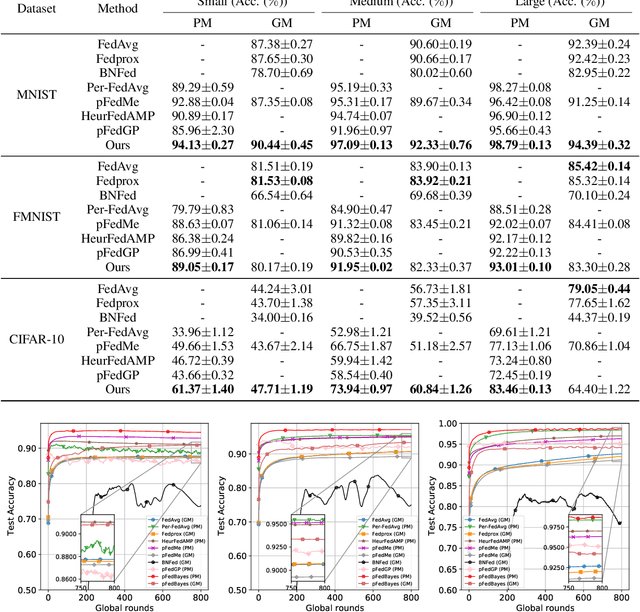


Federated learning faces huge challenges from model overfitting due to the lack of data and statistical diversity among clients. To address these challenges, this paper proposes a novel personalized federated learning method via Bayesian variational inference named pFedBayes. To alleviate the overfitting, weight uncertainty is introduced to neural networks for clients and the server. To achieve personalization, each client updates its local distribution parameters by balancing its construction error over private data and its KL divergence with global distribution from the server. Theoretical analysis gives an upper bound of averaged generalization error and illustrates that the convergence rate of the generalization error is minimax optimal up to a logarithmic factor. Experiments show that the proposed method outperforms other advanced personalized methods on personalized models, e.g., pFedBayes respectively outperforms other SOTA algorithms by 1.25%, 0.42% and 11.71% on MNIST, FMNIST and CIFAR-10 under non-i.i.d. limited data.
Collaborative Attention Network for Person Re-identification
Nov 29, 2019

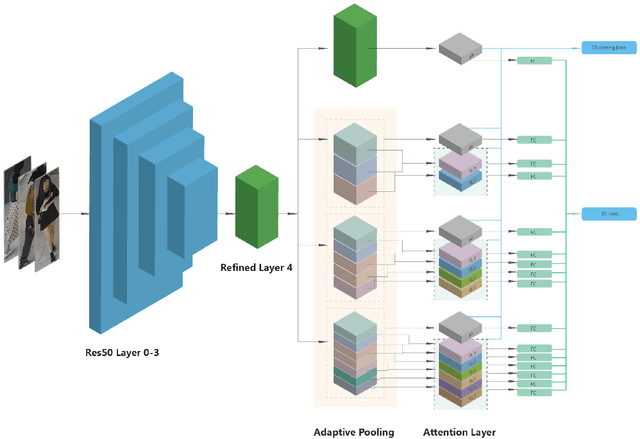
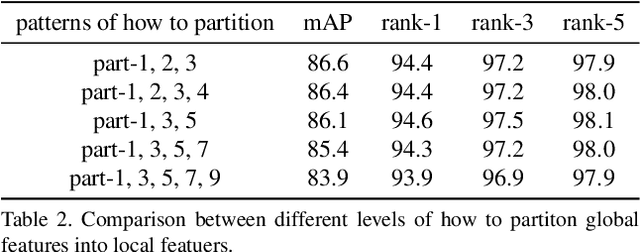
Jointly utilizing global and local features to improve model accuracy is becoming a popular approach for the person re-identification (ReID) problem, because previous works using global features alone have very limited capacity at extracting discriminative local patterns in the obtained feature representation. Existing works that attempt to collect local patterns either explicitly slice the global feature into several local pieces in a handcrafted way, or apply the attention mechanism to implicitly infer the importance of different local regions. In this paper, we show that by explicitly learning the importance of small local parts and part combinations, we can further improve the final feature representation for Re-ID. Specifically, we first separate the global feature into multiple local slices at different scale with a proposed multi-branch structure. Then we introduce the Collaborative Attention Network (CAN) to automatically learn the combination of features from adjacent slices. In this way, the combination keeps the intrinsic relation between adjacent features across local regions and scales, without losing information by partitioning the global features. Experiment results on several widely-used public datasets including Market-1501, DukeMTMC-ReID and CUHK03 prove that the proposed method outperforms many existing state-of-the-art methods.
Empirical Evaluation of Parallel Training Algorithms on Acoustic Modeling
Jul 26, 2017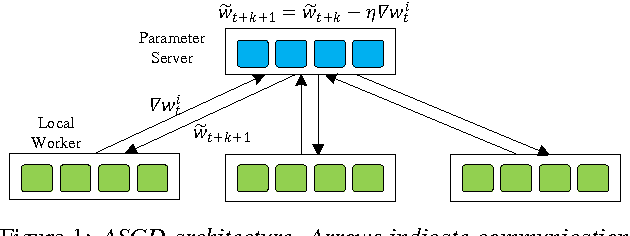

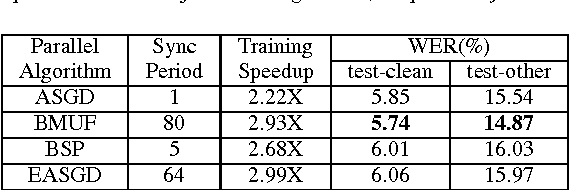
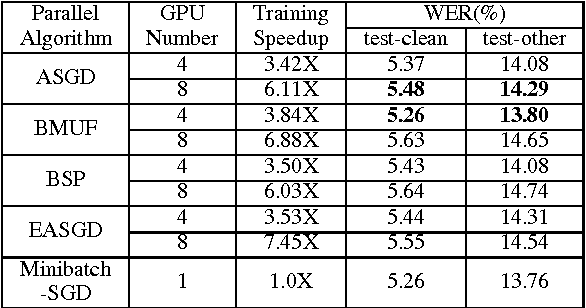
Deep learning models (DLMs) are state-of-the-art techniques in speech recognition. However, training good DLMs can be time consuming especially for production-size models and corpora. Although several parallel training algorithms have been proposed to improve training efficiency, there is no clear guidance on which one to choose for the task in hand due to lack of systematic and fair comparison among them. In this paper we aim at filling this gap by comparing four popular parallel training algorithms in speech recognition, namely asynchronous stochastic gradient descent (ASGD), blockwise model-update filtering (BMUF), bulk synchronous parallel (BSP) and elastic averaging stochastic gradient descent (EASGD), on 1000-hour LibriSpeech corpora using feed-forward deep neural networks (DNNs) and convolutional, long short-term memory, DNNs (CLDNNs). Based on our experiments, we recommend using BMUF as the top choice to train acoustic models since it is most stable, scales well with number of GPUs, can achieve reproducible results, and in many cases even outperforms single-GPU SGD. ASGD can be used as a substitute in some cases.