 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Convolution for CNN-based Speech Enhancement Models
Feb 20, 2025Deep learning-based speech enhancement methods have significantly improved speech quality and intelligibility. Convolutional neural networks (CNNs) have been proven to be essential components of many high-performance models. In this paper, we introduce adaptive convolution, an efficient and versatile convolutional module that enhances the model's capability to adaptively represent speech signals. Adaptive convolution performs frame-wise causal dynamic convolution, generating time-varying kernels for each frame by assembling multiple parallel candidate kernels. A Lightweight attention mechanism leverages both current and historical information to assign adaptive weights to each candidate kernel, guiding their aggregation. This enables the convolution operation to adapt to frame-level speech spectral features, leading to more efficient extraction and reconstruction. Experimental results on various CNN-based models demonstrate that adaptive convolution significantly improves the performance with negligible increases in computational complexity, especially for lightweight models. Furthermore, we propose the adaptive convolutional recurrent network (AdaptCRN), an ultra-lightweight model that incorporates adaptive convolution and an efficient encoder-decoder design, achieving superior performance compared to models with similar or even higher computational costs.
TrimTail: Low-Latency Streaming ASR with Simple but Effective Spectrogram-Level Length Penalty
Nov 01, 2022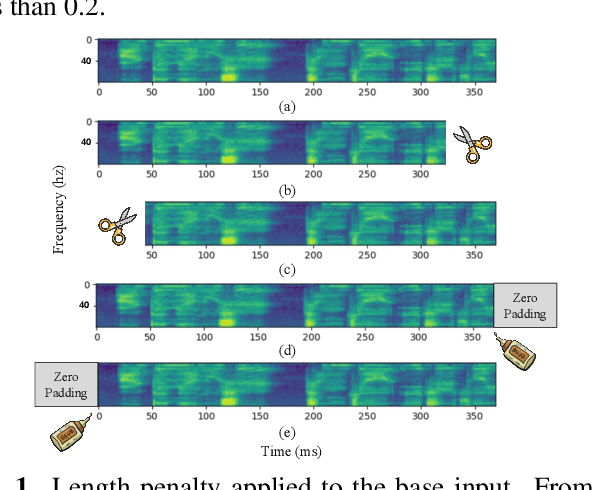



In this paper, we present TrimTail, a simple but effective emission regularization method to improve the latency of streaming ASR models. The core idea of TrimTail is to apply length penalty (i.e., by trimming trailing frames, see Fig. 1-(b)) directly on the spectrogram of input utterances, which does not require any alignment. We demonstrate that TrimTail is computationally cheap and can be applied online and optimized with any training loss or any model architecture on any dataset without any extra effort by applying it on various end-to-end streaming ASR networks either trained with CTC loss [1] or Transducer loss [2]. We achieve 100 $\sim$ 200ms latency reduction with equal or even better accuracy on both Aishell-1 and Librispeech. Moreover, by using TrimTail, we can achieve a 400ms algorithmic improvement of User Sensitive Delay (USD) with an accuracy loss of less than 0.2.
FusionFormer: Fusing Operations in Transformer for Efficient Streaming Speech Recognition
Oct 31, 2022



The recently proposed Conformer architecture which combines convolution with attention to capture both local and global dependencies has become the \textit{de facto} backbone model for Automatic Speech Recognition~(ASR). Inherited from the Natural Language Processing (NLP) tasks, the architecture takes Layer Normalization~(LN) as a default normalization technique. However, through a series of systematic studies, we find that LN might take 10\% of the inference time despite that it only contributes to 0.1\% of the FLOPs. This motivates us to replace LN with other normalization techniques, e.g., Batch Normalization~(BN), to speed up inference with the help of operator fusion methods and the avoidance of calculating the mean and variance statistics during inference. After examining several plain attempts which directly remove all LN layers or replace them with BN in the same place, we find that the divergence issue is mainly caused by the unstable layer output. We therefore propose to append a BN layer to each linear or convolution layer where stabilized training results are observed. We also propose to simplify the activations in Conformer, such as Swish and GLU, by replacing them with ReLU. All these exchanged modules can be fused into the weights of the adjacent linear/convolution layers and hence have zero inference cost. Therefore, we name it FusionFormer. Our experiments indicate that FusionFormer is as effective as the LN-based Conformer and is about 10\% faster.
Semi-blind source separation using convolutive transfer function for nonlinear acoustic echo cancellation
Jul 04, 2022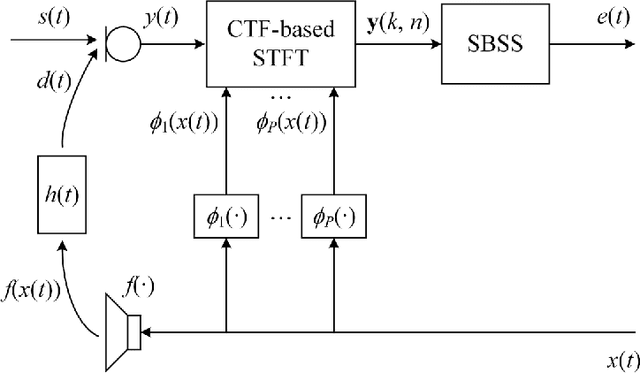
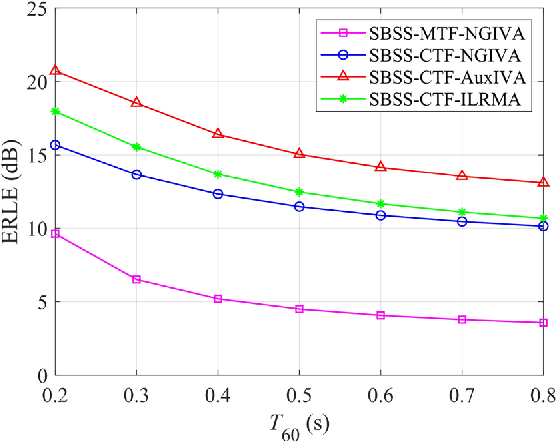
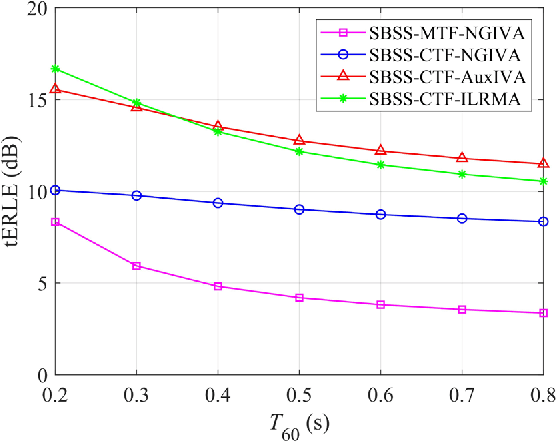
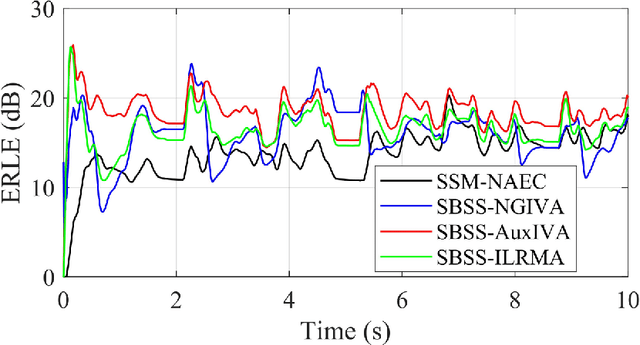
The recently proposed semi-blind source separation (SBSS) method for nonlinear acoustic echo cancellation (NAEC) outperforms adaptive NAEC in attenuating the nonlinear acoustic echo. However, the multiplicative transfer function (MTF) approximation makes it unsuitable for real-time applications especially in highly reverberant environments, and the natural gradient makes it hard to balance well between fast convergence speed and stability. In this paper, we propose two more effective SBSS methods based on auxiliary-function-based independent vector analysis (AuxIVA) and independent low-rank matrix analysis (ILRMA). The convolutive transfer function (CTF) approximation is used instead of MTF so that a long impulse response can be modeled with a short latency. The optimization schemes used in AuxIVA and ILRMA are carefully regularized according to the constrained demixing matrix of NAEC. Experimental results validate significantly better echo cancellation performance of the proposed methods.