 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Agent Continuous Control with Generative Flow Networks
Aug 13, 2024Generative Flow Networks (GFlowNets) aim to generate diverse trajectories from a distribution in which the final states of the trajectories are proportional to the reward, serving as a powerful alternative to reinforcement learning for exploratory control tasks. However, the individual-flow matching constraint in GFlowNets limits their applications for multi-agent systems, especially continuous joint-control problems. In this paper, we propose a novel Multi-Agent generative Continuous Flow Networks (MACFN) method to enable multiple agents to perform cooperative exploration for various compositional continuous objects. Technically, MACFN trains decentralized individual-flow-based policies in a centralized global-flow-based matching fashion. During centralized training, MACFN introduces a continuous flow decomposition network to deduce the flow contributions of each agent in the presence of only global rewards. Then agents can deliver actions solely based on their assigned local flow in a decentralized way, forming a joint policy distribution proportional to the rewards. To guarantee the expressiveness of continuous flow decomposition, we theoretically derive a consistency condition on the decomposition network. Experimental results demonstrate that the proposed method yields results superior to the state-of-the-art counterparts and better exploration capability. Our code is available at https://github.com/isluoshuang/MACFN.
Ents: An Efficient Three-party Training Framework for Decision Trees by Communication Optimization
Jun 12, 2024
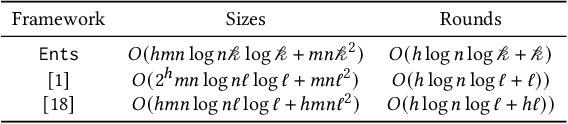
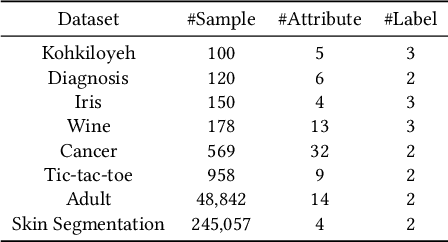
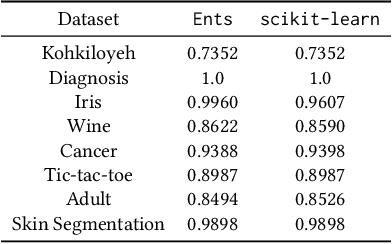
Multi-party training frameworks for decision trees based on secure multi-party computation enable multiple parties to train high-performance models on distributed private data with privacy preservation. The training process essentially involves frequent dataset splitting according to the splitting criterion (e.g. Gini impurity). However, existing multi-party training frameworks for decision trees demonstrate communication inefficiency due to the following issues: (1) They suffer from huge communication overhead in securely splitting a dataset with continuous attributes. (2) They suffer from huge communication overhead due to performing almost all the computations on a large ring to accommodate the secure computations for the splitting criterion. In this paper, we are motivated to present an efficient three-party training framework, namely Ents, for decision trees by communication optimization. For the first issue, we present a series of training protocols based on the secure radix sort protocols to efficiently and securely split a dataset with continuous attributes. For the second issue, we propose an efficient share conversion protocol to convert shares between a small ring and a large ring to reduce the communication overhead incurred by performing almost all the computations on a large ring. Experimental results from eight widely used datasets show that Ents outperforms state-of-the-art frameworks by $5.5\times \sim 9.3\times$ in communication sizes and $3.9\times \sim 5.3\times$ in communication rounds. In terms of training time, Ents yields an improvement of $3.5\times \sim 6.7\times$. To demonstrate its practicality, Ents requires less than three hours to securely train a decision tree on a widely used real-world dataset (Skin Segmentation) with more than 245,000 samples in the WAN setting.
MAP: Model Aggregation and Personalization in Federated Learning with Incomplete Classes
Apr 14, 2024
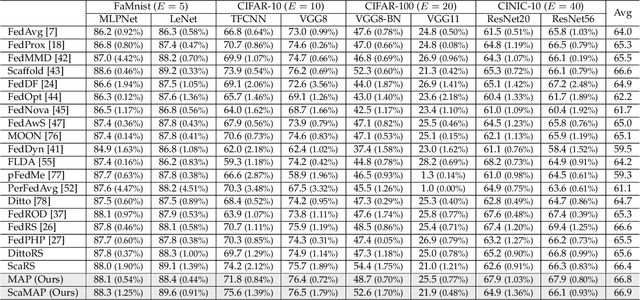
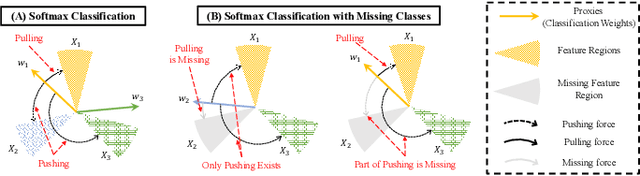
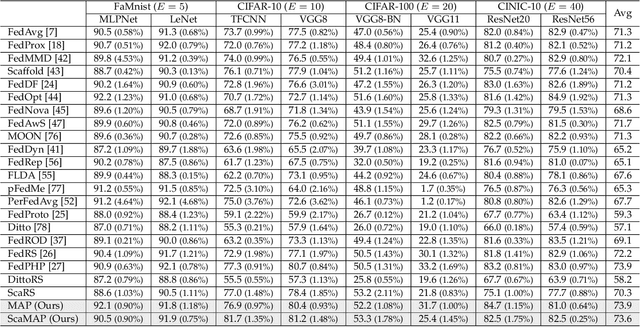
In some real-world applications, data samples are usually distributed on local devices, where federated learning (FL) techniques are proposed to coordinate decentralized clients without directly sharing users' private data. FL commonly follows the parameter server architecture and contains multiple personalization and aggregation procedures. The natural data heterogeneity across clients, i.e., Non-I.I.D. data, challenges both the aggregation and personalization goals in FL. In this paper, we focus on a special kind of Non-I.I.D. scene where clients own incomplete classes, i.e., each client can only access a partial set of the whole class set. The server aims to aggregate a complete classification model that could generalize to all classes, while the clients are inclined to improve the performance of distinguishing their observed classes. For better model aggregation, we point out that the standard softmax will encounter several problems caused by missing classes and propose "restricted softmax" as an alternative. For better model personalization, we point out that the hard-won personalized models are not well exploited and propose "inherited private model" to store the personalization experience. Our proposed algorithm named MAP could simultaneously achieve the aggregation and personalization goals in FL. Abundant experimental studies verify the superiorities of our algorithm.
ECLM: Efficient Edge-Cloud Collaborative Learning with Continuous Environment Adaptation
Nov 18, 2023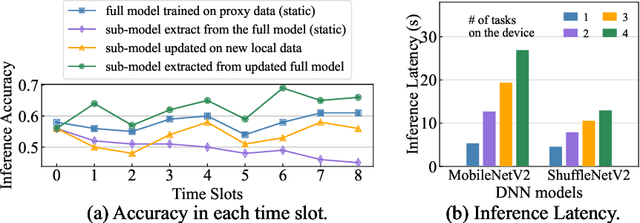
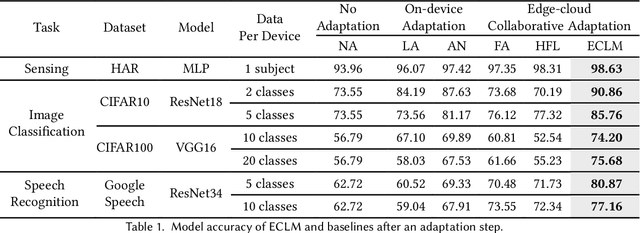
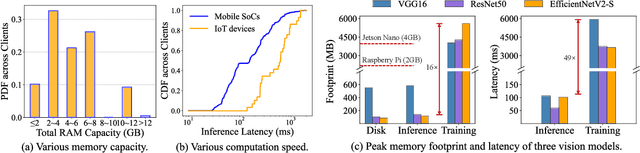
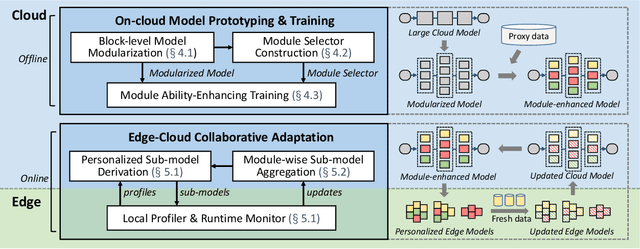
Pervasive mobile AI applications primarily employ one of the two learning paradigms: cloud-based learning (with powerful large models) or on-device learning (with lightweight small models). Despite their own advantages, neither paradigm can effectively handle dynamic edge environments with frequent data distribution shifts and on-device resource fluctuations, inevitably suffering from performance degradation. In this paper, we propose ECLM, an edge-cloud collaborative learning framework for rapid model adaptation for dynamic edge environments. We first propose a novel block-level model decomposition design to decompose the original large cloud model into multiple combinable modules. By flexibly combining a subset of the modules, this design enables the derivation of compact, task-specific sub-models for heterogeneous edge devices from the large cloud model, and the seamless integration of new knowledge learned on these devices into the cloud model periodically. As such, ECLM ensures that the cloud model always provides up-to-date sub-models for edge devices. We further propose an end-to-end learning framework that incorporates the modular model design into an efficient model adaptation pipeline including an offline on-cloud model prototyping and training stage, and an online edge-cloud collaborative adaptation stage. Extensive experiments over various datasets demonstrate that ECLM significantly improves model performance (e.g., 18.89% accuracy increase) and resource efficiency (e.g., 7.12x communication cost reduction) in adapting models to dynamic edge environments by efficiently collaborating the edge and the cloud models.
GFlowNets with Human Feedback
May 11, 2023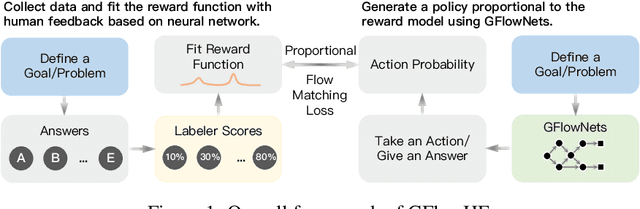
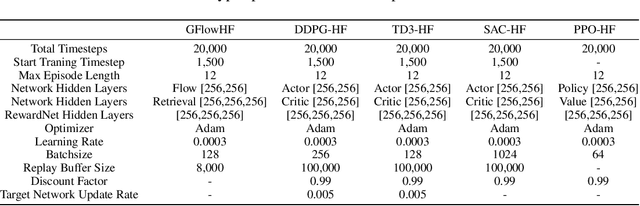
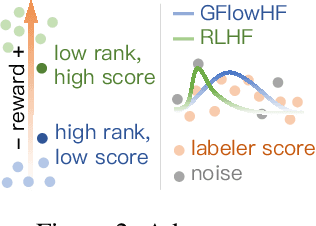
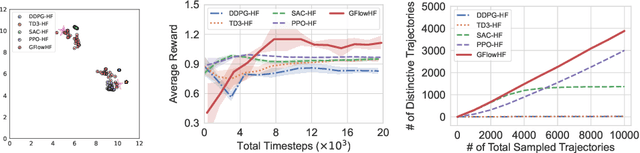
We propose the GFlowNets with Human Feedback (GFlowHF) framework to improve the exploration ability when training AI models. For tasks where the reward is unknown, we fit the reward function through human evaluations on different trajectories. The goal of GFlowHF is to learn a policy that is strictly proportional to human ratings, instead of only focusing on human favorite ratings like RLHF. Experiments show that GFlowHF can achieve better exploration ability than RLHF.
Generalized Universal Domain Adaptation with Generative Flow Networks
May 08, 2023We introduce a new problem in unsupervised domain adaptation, termed as Generalized Universal Domain Adaptation (GUDA), which aims to achieve precise prediction of all target labels including unknown categories. GUDA bridges the gap between label distribution shift-based and label space mismatch-based variants, essentially categorizing them as a unified problem, guiding to a comprehensive framework for thoroughly solving all the variants. The key challenge of GUDA is developing and identifying novel target categories while estimating the target label distribution. To address this problem, we take advantage of the powerful exploration capability of generative flow networks and propose an active domain adaptation algorithm named GFlowDA, which selects diverse samples with probabilities proportional to a reward function. To enhance the exploration capability and effectively perceive the target label distribution, we tailor the states and rewards, and introduce an efficient solution for parent exploration and state transition. We also propose a training paradigm for GUDA called Generalized Universal Adversarial Network (GUAN), which involves collaborative optimization between GUAN and GFlowNet. Theoretical analysis highlights the importance of exploration, and extensive experiments on benchmark datasets demonstrate the superiority of GFlowDA.
Generative Flow Networks for Precise Reward-Oriented Active Learning on Graphs
Apr 24, 2023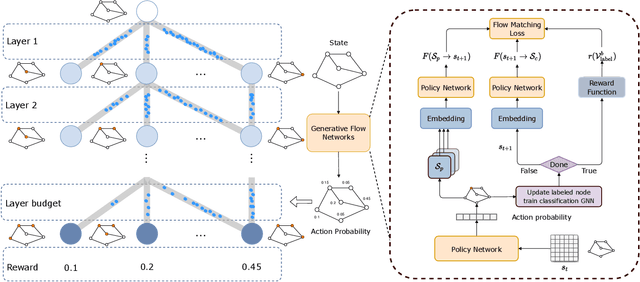
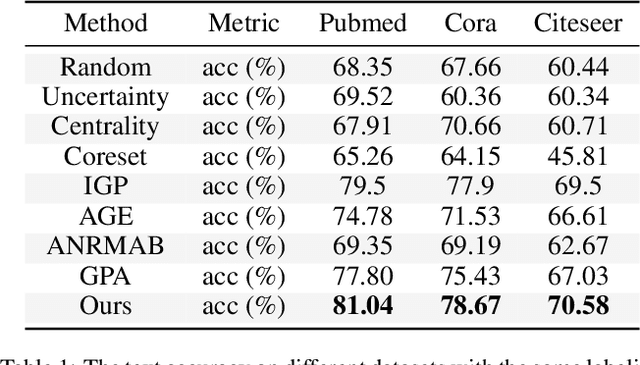
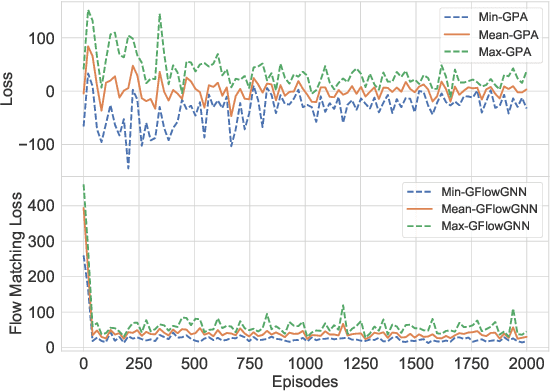
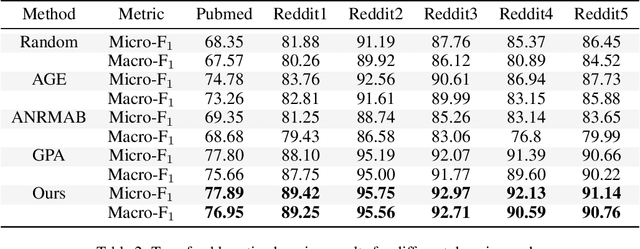
Many score-based active learning methods have been successfully applied to graph-structured data, aiming to reduce the number of labels and achieve better performance of graph neural networks based on predefined score functions. However, these algorithms struggle to learn policy distributions that are proportional to rewards and have limited exploration capabilities. In this paper, we innovatively formulate the graph active learning problem as a generative process, named GFlowGNN, which generates various samples through sequential actions with probabilities precisely proportional to a predefined reward function. Furthermore, we propose the concept of flow nodes and flow features to efficiently model graphs as flows based on generative flow networks, where the policy network is trained with specially designed rewards. Extensive experiments on real datasets show that the proposed approach has good exploration capability and transferability, outperforming various state-of-the-art methods.
Universal Domain Adaptation via Compressive Attention Matching
Apr 24, 2023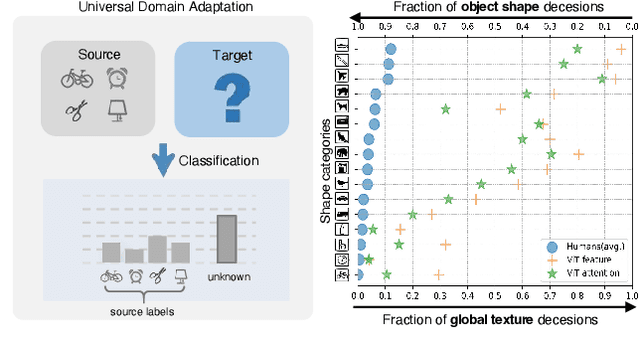
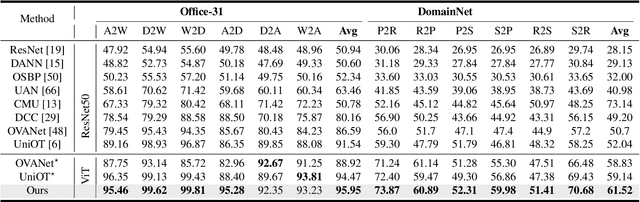

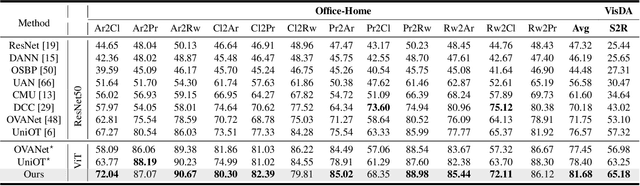
Universal domain adaptation (UniDA) aims to transfer knowledge from the source domain to the target domain without any prior knowledge about the label set. The challenge lies in how to determine whether the target samples belong to common categories. The mainstream methods make judgments based on the sample features, which overemphasizes global information while ignoring the most crucial local objects in the image, resulting in limited accuracy. To address this issue, we propose a Universal Attention Matching (UniAM) framework by exploiting the self-attention mechanism in vision transformer to capture the crucial object information. The proposed framework introduces a novel Compressive Attention Matching (CAM) approach to explore the core information by compressively representing attentions. Furthermore, CAM incorporates a residual-based measurement to determine the sample commonness. By utilizing the measurement, UniAM achieves domain-wise and category-wise Common Feature Alignment (CFA) and Target Class Separation (TCS). Notably, UniAM is the first method utilizing the attention in vision transformer directly to perform classification tasks. Extensive experiments show that UniAM outperforms the current state-of-the-art methods on various benchmark datasets.
Multi-agent Policy Reciprocity with Theoretical Guarantee
Apr 12, 2023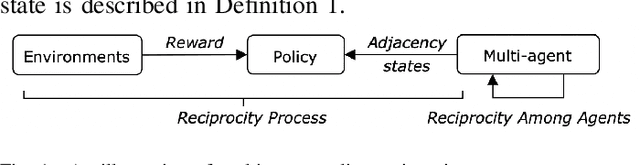
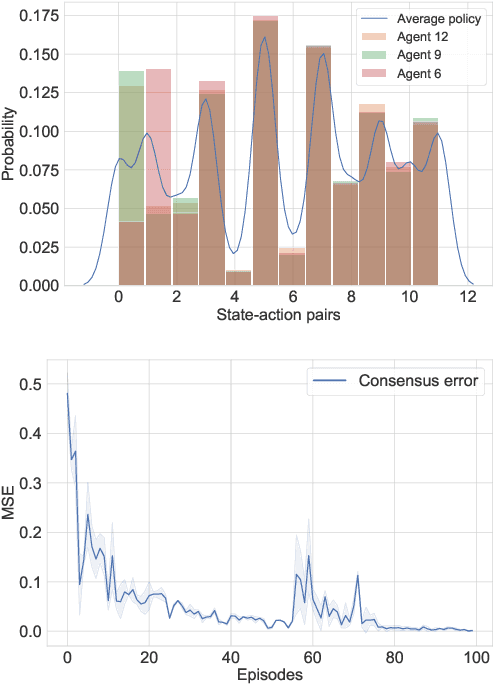
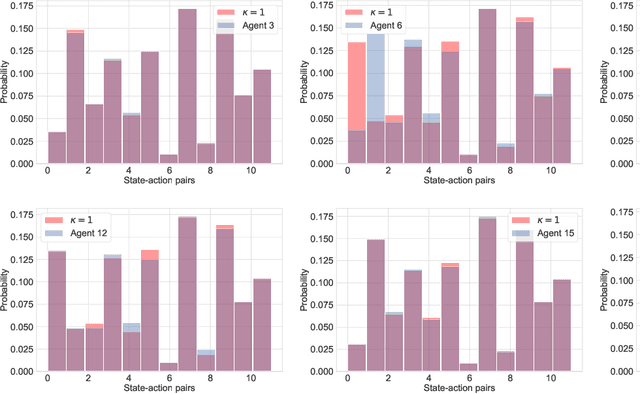
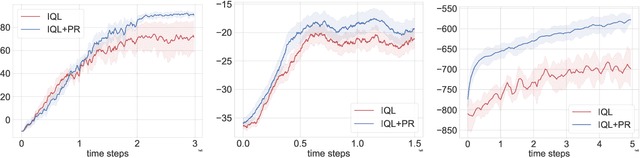
Modern multi-agent reinforcement learning (RL) algorithms hold great potential for solving a variety of real-world problems. However, they do not fully exploit cross-agent knowledge to reduce sample complexity and improve performance. Although transfer RL supports knowledge sharing, it is hyperparameter sensitive and complex. To solve this problem, we propose a novel multi-agent policy reciprocity (PR) framework, where each agent can fully exploit cross-agent policies even in mismatched states. We then define an adjacency space for mismatched states and design a plug-and-play module for value iteration, which enables agents to infer more precise returns. To improve the scalability of PR, deep PR is proposed for continuous control tasks. Moreover, theoretical analysis shows that agents can asymptotically reach consensus through individual perceived rewards and converge to an optimal value function, which implies the stability and effectiveness of PR, respectively. Experimental results on discrete and continuous environments demonstrate that PR outperforms various existing RL and transfer RL methods.
Federated Learning via Variational Bayesian Inference: Personalization, Sparsity and Clustering
Mar 08, 2023Federated learning (FL) is a promising framework that models distributed machine learning while protecting the privacy of clients. However, FL suffers performance degradation from heterogeneous and limited data. To alleviate the degradation, we present a novel personalized Bayesian FL approach named pFedBayes. By using the trained global distribution from the server as the prior distribution of each client, each client adjusts its own distribution by minimizing the sum of the reconstruction error over its personalized data and the KL divergence with the downloaded global distribution. Then, we propose a sparse personalized Bayesian FL approach named sFedBayes. To overcome the extreme heterogeneity in non-i.i.d. data, we propose a clustered Bayesian FL model named cFedbayes by learning different prior distributions for different clients. Theoretical analysis gives the generalization error bound of three approaches and shows that the generalization error convergence rates of the proposed approaches achieve minimax optimality up to a logarithmic factor. Moreover, the analysis presents that cFedbayes has a tighter generalization error rate than pFedBayes. Numerous experiments are provided to demonstrate that the proposed approaches have better performance than other advanced personalized methods on private models in the presence of heterogeneous and limited data.