Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGFlowNets with Human Feedback
Paper and Code
May 11, 2023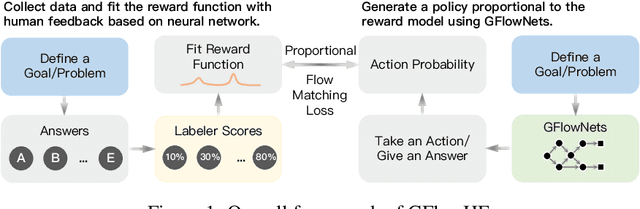
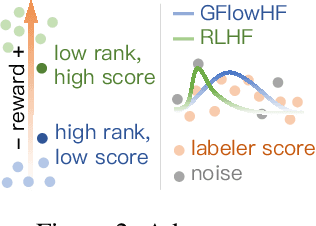
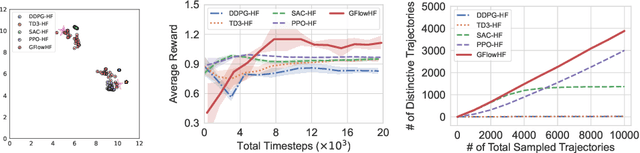
We propose the GFlowNets with Human Feedback (GFlowHF) framework to improve the exploration ability when training AI models. For tasks where the reward is unknown, we fit the reward function through human evaluations on different trajectories. The goal of GFlowHF is to learn a policy that is strictly proportional to human ratings, instead of only focusing on human favorite ratings like RLHF. Experiments show that GFlowHF can achieve better exploration ability than RLHF.
View paper on
 OpenReview
OpenReview