 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeACE-Brain-0: Spatial Intelligence as a Shared Scaffold for Universal Embodiments
Mar 03, 2026Universal embodied intelligence demands robust generalization across heterogeneous embodiments, such as autonomous driving, robotics, and unmanned aerial vehicles (UAVs). However, existing embodied brain in training a unified model over diverse embodiments frequently triggers long-tail data, gradient interference, and catastrophic forgetting, making it notoriously difficult to balance universal generalization with domain-specific proficiency. In this report, we introduce ACE-Brain-0, a generalist foundation brain that unifies spatial reasoning, autonomous driving, and embodied manipulation within a single multimodal large language model~(MLLM). Our key insight is that spatial intelligence serves as a universal scaffold across diverse physical embodiments: although vehicles, robots, and UAVs differ drastically in morphology, they share a common need for modeling 3D mental space, making spatial cognition a natural, domain-agnostic foundation for cross-embodiment transfer. Building on this insight, we propose the Scaffold-Specialize-Reconcile~(SSR) paradigm, which first establishes a shared spatial foundation, then cultivates domain-specialized experts, and finally harmonizes them through data-free model merging. Furthermore, we adopt Group Relative Policy Optimization~(GRPO) to strengthen the model's comprehensive capability. Extensive experiments demonstrate that ACE-Brain-0 achieves competitive and even state-of-the-art performance across 24 spatial and embodiment-related benchmarks.
Step-GUI Technical Report
Dec 19, 2025



Recent advances in multimodal large language models unlock unprecedented opportunities for GUI automation. However, a fundamental challenge remains: how to efficiently acquire high-quality training data while maintaining annotation reliability? We introduce a self-evolving training pipeline powered by the Calibrated Step Reward System, which converts model-generated trajectories into reliable training signals through trajectory-level calibration, achieving >90% annotation accuracy with 10-100x lower cost. Leveraging this pipeline, we introduce Step-GUI, a family of models (4B/8B) that achieves state-of-the-art GUI performance (8B: 80.2% AndroidWorld, 48.5% OSWorld, 62.6% ScreenShot-Pro) while maintaining robust general capabilities. As GUI agent capabilities improve, practical deployment demands standardized interfaces across heterogeneous devices while protecting user privacy. To this end, we propose GUI-MCP, the first Model Context Protocol for GUI automation with hierarchical architecture that combines low-level atomic operations and high-level task delegation to local specialist models, enabling high-privacy execution where sensitive data stays on-device. Finally, to assess whether agents can handle authentic everyday usage, we introduce AndroidDaily, a benchmark grounded in real-world mobile usage patterns with 3146 static actions and 235 end-to-end tasks across high-frequency daily scenarios (8B: static 89.91%, end-to-end 52.50%). Our work advances the development of practical GUI agents and demonstrates strong potential for real-world deployment in everyday digital interactions.
Qwen3 Technical Report
May 14, 2025



In this work, we present Qwen3, the latest version of the Qwen model family. Qwen3 comprises a series of large language models (LLMs) designed to advance performance, efficiency, and multilingual capabilities. The Qwen3 series includes models of both dense and Mixture-of-Expert (MoE) architectures, with parameter scales ranging from 0.6 to 235 billion. A key innovation in Qwen3 is the integration of thinking mode (for complex, multi-step reasoning) and non-thinking mode (for rapid, context-driven responses) into a unified framework. This eliminates the need to switch between different models--such as chat-optimized models (e.g., GPT-4o) and dedicated reasoning models (e.g., QwQ-32B)--and enables dynamic mode switching based on user queries or chat templates. Meanwhile, Qwen3 introduces a thinking budget mechanism, allowing users to allocate computational resources adaptively during inference, thereby balancing latency and performance based on task complexity. Moreover, by leveraging the knowledge from the flagship models, we significantly reduce the computational resources required to build smaller-scale models, while ensuring their highly competitive performance. Empirical evaluations demonstrate that Qwen3 achieves state-of-the-art results across diverse benchmarks, including tasks in code generation, mathematical reasoning, agent tasks, etc., competitive against larger MoE models and proprietary models. Compared to its predecessor Qwen2.5, Qwen3 expands multilingual support from 29 to 119 languages and dialects, enhancing global accessibility through improved cross-lingual understanding and generation capabilities. To facilitate reproducibility and community-driven research and development, all Qwen3 models are publicly accessible under Apache 2.0.
Multi-Agent Continuous Control with Generative Flow Networks
Aug 13, 2024Generative Flow Networks (GFlowNets) aim to generate diverse trajectories from a distribution in which the final states of the trajectories are proportional to the reward, serving as a powerful alternative to reinforcement learning for exploratory control tasks. However, the individual-flow matching constraint in GFlowNets limits their applications for multi-agent systems, especially continuous joint-control problems. In this paper, we propose a novel Multi-Agent generative Continuous Flow Networks (MACFN) method to enable multiple agents to perform cooperative exploration for various compositional continuous objects. Technically, MACFN trains decentralized individual-flow-based policies in a centralized global-flow-based matching fashion. During centralized training, MACFN introduces a continuous flow decomposition network to deduce the flow contributions of each agent in the presence of only global rewards. Then agents can deliver actions solely based on their assigned local flow in a decentralized way, forming a joint policy distribution proportional to the rewards. To guarantee the expressiveness of continuous flow decomposition, we theoretically derive a consistency condition on the decomposition network. Experimental results demonstrate that the proposed method yields results superior to the state-of-the-art counterparts and better exploration capability. Our code is available at https://github.com/isluoshuang/MACFN.
CodeApex: A Bilingual Programming Evaluation Benchmark for Large Language Models
Sep 10, 2023



With the emergence of Large Language Models (LLMs), there has been a significant improvement in the programming capabilities of models, attracting growing attention from researchers. We propose CodeApex, a bilingual benchmark dataset focusing on the programming comprehension and code generation abilities of LLMs. CodeApex comprises three types of multiple-choice questions: conceptual understanding, commonsense reasoning, and multi-hop reasoning, designed to evaluate LLMs on programming comprehension tasks. Additionally, CodeApex utilizes algorithmic questions and corresponding test cases to assess the code quality generated by LLMs. We evaluate 14 state-of-the-art LLMs, including both general-purpose and specialized models. GPT exhibits the best programming capabilities, achieving approximate accuracies of 50% and 56% on the two tasks, respectively. There is still significant room for improvement in programming tasks. We hope that CodeApex can serve as a reference for evaluating the coding capabilities of LLMs, further promoting their development and growth. Datasets are released at https://github.com/APEXLAB/CodeApex.git. CodeApex submission website is https://apex.sjtu.edu.cn/codeapex/.
GFlowNets with Human Feedback
May 11, 2023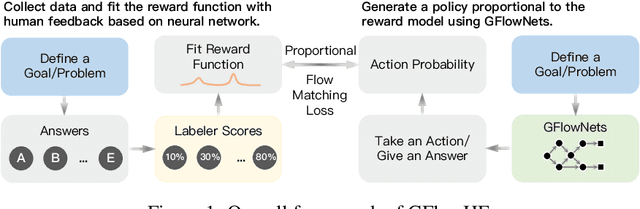
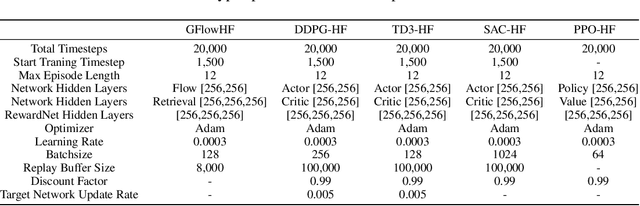
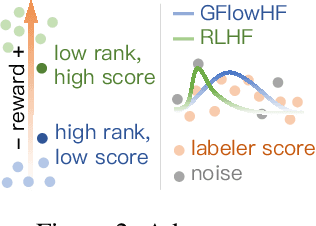
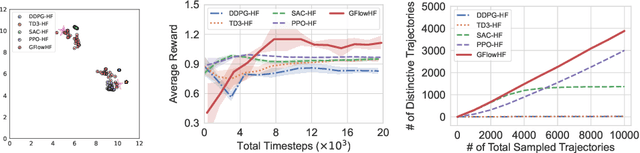
We propose the GFlowNets with Human Feedback (GFlowHF) framework to improve the exploration ability when training AI models. For tasks where the reward is unknown, we fit the reward function through human evaluations on different trajectories. The goal of GFlowHF is to learn a policy that is strictly proportional to human ratings, instead of only focusing on human favorite ratings like RLHF. Experiments show that GFlowHF can achieve better exploration ability than RLHF.
CFlowNets: Continuous Control with Generative Flow Networks
Mar 04, 2023Generative flow networks (GFlowNets), as an emerging technique, can be used as an alternative to reinforcement learning for exploratory control tasks. GFlowNet aims to generate distribution proportional to the rewards over terminating states, and to sample different candidates in an active learning fashion. GFlowNets need to form a DAG and compute the flow matching loss by traversing the inflows and outflows of each node in the trajectory. No experiments have yet concluded that GFlowNets can be used to handle continuous tasks. In this paper, we propose generative continuous flow networks (CFlowNets) that can be applied to continuous control tasks. First, we present the theoretical formulation of CFlowNets. Then, a training framework for CFlowNets is proposed, including the action selection process, the flow approximation algorithm, and the continuous flow matching loss function. Afterward, we theoretically prove the error bound of the flow approximation. The error decreases rapidly as the number of flow samples increases. Finally, experimental results on continuous control tasks demonstrate the performance advantages of CFlowNets compared to many reinforcement learning methods, especially regarding exploration ability.
S2RL: Do We Really Need to Perceive All States in Deep Multi-Agent Reinforcement Learning?
Jun 20, 2022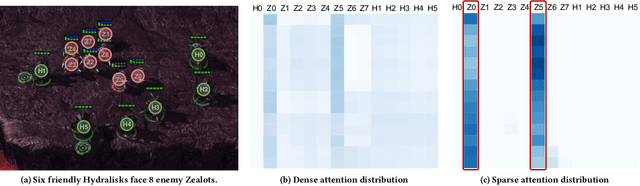
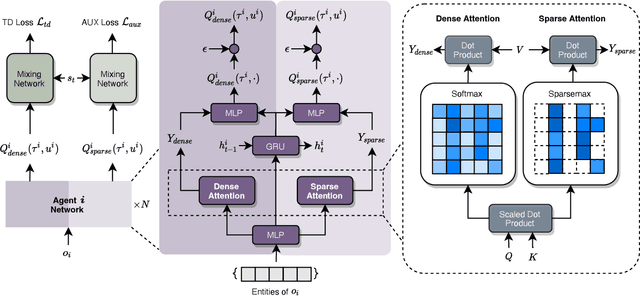
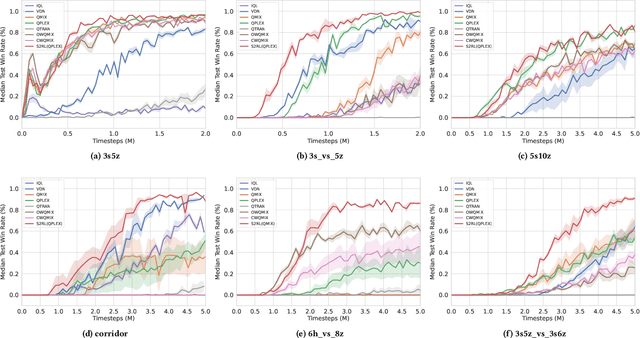
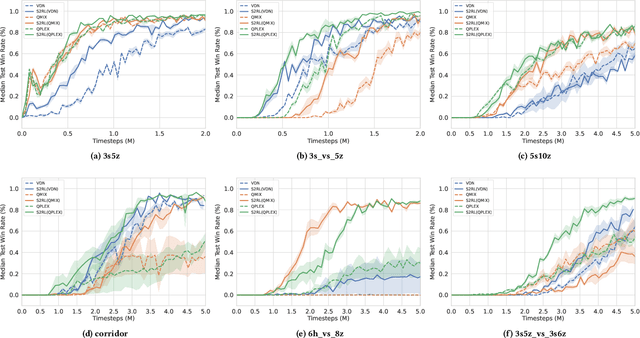
Collaborative multi-agent reinforcement learning (MARL) has been widely used in many practical applications, where each agent makes a decision based on its own observation. Most mainstream methods treat each local observation as an entirety when modeling the decentralized local utility functions. However, they ignore the fact that local observation information can be further divided into several entities, and only part of the entities is helpful to model inference. Moreover, the importance of different entities may change over time. To improve the performance of decentralized policies, the attention mechanism is used to capture features of local information. Nevertheless, existing attention models rely on dense fully connected graphs and cannot better perceive important states. To this end, we propose a sparse state based MARL (S2RL) framework, which utilizes a sparse attention mechanism to discard irrelevant information in local observations. The local utility functions are estimated through the self-attention and sparse attention mechanisms separately, then are combined into a standard joint value function and auxiliary joint value function in the central critic. We design the S2RL framework as a plug-and-play module, making it general enough to be applied to various methods. Extensive experiments on StarCraft II show that S2RL can significantly improve the performance of many state-of-the-art methods.
Mining Latent Relationships among Clients: Peer-to-peer Federated Learning with Adaptive Neighbor Matching
Mar 23, 2022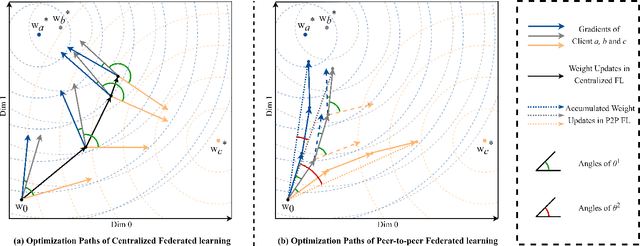

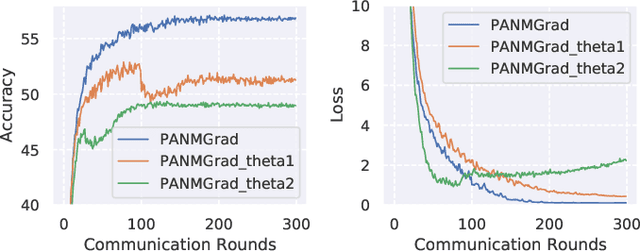
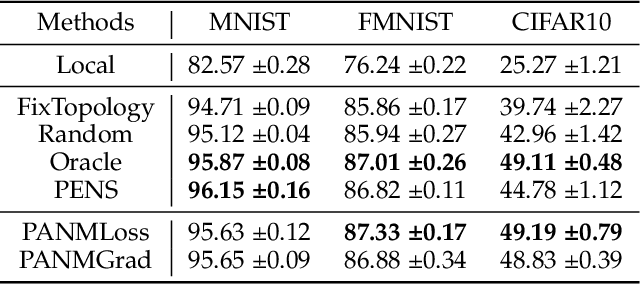
In federated learning (FL), clients may have diverse objectives, merging all clients' knowledge into one global model will cause negative transfers to local performance. Thus, clustered FL is proposed to group similar clients into clusters and maintain several global models. Nevertheless, current clustered FL algorithms require the assumption of the number of clusters, they are not effective enough to explore the latent relationships among clients. However, we take advantage of peer-to-peer (P2P) FL, where clients communicate with neighbors without a central server and propose an algorithm that enables clients to form an effective communication topology in a decentralized manner without assuming the number of clusters. Additionally, the P2P setting will release the concerns caused by the central server in centralized FL, such as reliability and communication bandwidth problems. In our method, 1) we present two novel metrics for measuring client similarity, applicable under P2P protocols; 2) we devise a two-stage algorithm, in the first stage, an efficient method to enable clients to match same-cluster neighbors with high confidence is proposed; 3) then in the second stage, a heuristic method based on Expectation Maximization under the Gaussian Mixture Model assumption of similarities is used for clients to discover more neighbors with similar objectives. We make a theoretical analysis of how our work is superior to the P2P FL counterpart and extensive experiments show that our method outperforms all P2P FL baselines and has comparable or even superior performance to centralized cluster FL. Moreover, results show that our method is much effective in mining latent cluster relationships under various heterogeneity without assuming the number of clusters and it is effective even under low communication budgets.
CATNet: Context AggregaTion Network for Instance Segmentation in Remote Sensing Images
Nov 22, 2021


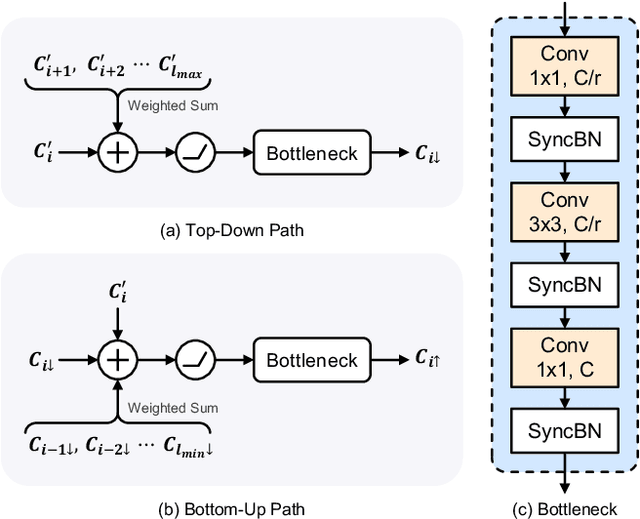
The task of instance segmentation in remote sensing images, aiming at performing per-pixel labeling of objects at instance level, is of great importance for various civil applications. Despite previous successes, most existing instance segmentation methods designed for natural images encounter sharp performance degradations when directly applied to top-view remote sensing images. Through careful analysis, we observe that the challenges mainly come from lack of discriminative object features due to severe scale variations, low contrasts, and clustered distributions. In order to address these problems, a novel context aggregation network (CATNet) is proposed to improve the feature extraction process. The proposed model exploits three lightweight plug-and-play modules, namely dense feature pyramid network (DenseFPN), spatial context pyramid (SCP), and hierarchical region of interest extractor (HRoIE), to aggregate global visual context at feature, spatial, and instance domains, respectively. DenseFPN is a multi-scale feature propagation module that establishes more flexible information flows by adopting inter-level residual connections, cross-level dense connections, and feature re-weighting strategy. Leveraging the attention mechanism, SCP further augments the features by aggregating global spatial context into local regions. For each instance, HRoIE adaptively generates RoI features for different downstream tasks. We carry out extensive evaluation of the proposed scheme on the challenging iSAID, DIOR, NWPU VHR-10, and HRSID datasets. The evaluation results demonstrate that the proposed approach outperforms state-of-the-arts with similar computational costs. Code is available at https://github.com/yeliudev/CATNet.