 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransfer Heterogeneous Knowledge Among Peer-to-Peer Teammates: A Model Distillation Approach
Paper and Code
Feb 06, 2020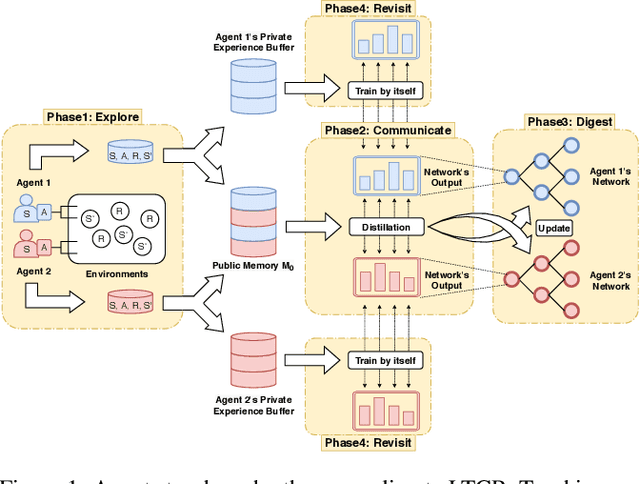
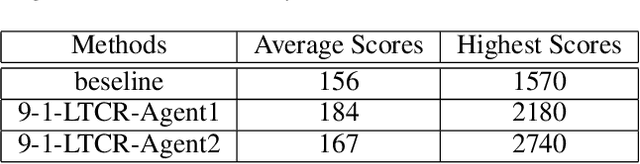
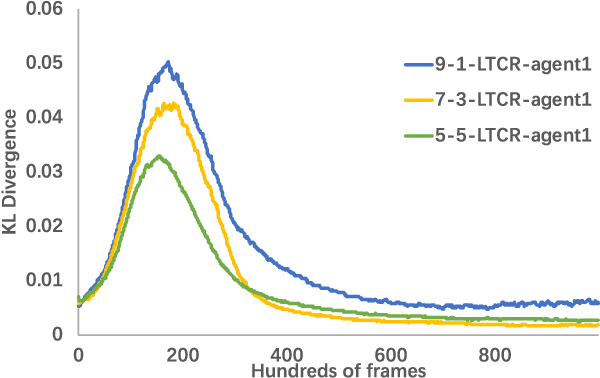

Peer-to-peer knowledge transfer in distributed environments has emerged as a promising method since it could accelerate learning and improve team-wide performance without relying on pre-trained teachers in deep reinforcement learning. However, for traditional peer-to-peer methods such as action advising, they have encountered difficulties in how to efficiently expressed knowledge and advice. As a result, we propose a brand new solution to reuse experiences and transfer value functions among multiple students via model distillation. But it is still challenging to transfer Q-function directly since it is unstable and not bounded. To address this issue confronted with existing works, we adopt Categorical Deep Q-Network. We also describe how to design an efficient communication protocol to exploit heterogeneous knowledge among multiple distributed agents. Our proposed framework, namely Learning and Teaching Categorical Reinforcement (LTCR), shows promising performance on stabilizing and accelerating learning progress with improved team-wide reward in four typical experimental environments.