 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCATArena: Evaluation of LLM Agents through Iterative Tournament Competitions
Oct 30, 2025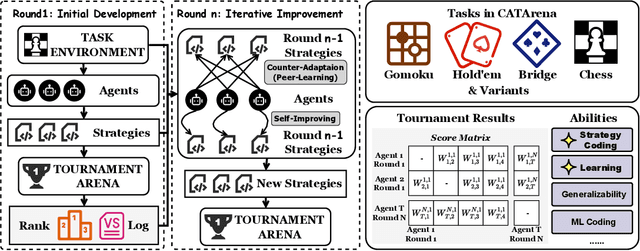

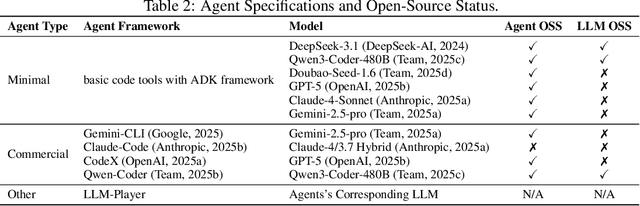
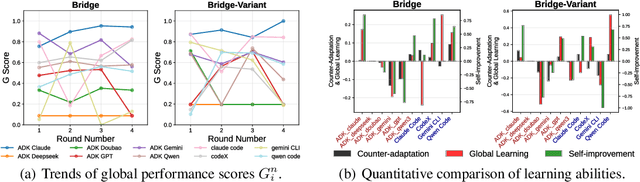
Large Language Model (LLM) agents have evolved from basic text generation to autonomously completing complex tasks through interaction with external tools. However, current benchmarks mainly assess end-to-end performance in fixed scenarios, restricting evaluation to specific skills and suffering from score saturation and growing dependence on expert annotation as agent capabilities improve. In this work, we emphasize the importance of learning ability, including both self-improvement and peer-learning, as a core driver for agent evolution toward human-level intelligence. We propose an iterative, competitive peer-learning framework, which allows agents to refine and optimize their strategies through repeated interactions and feedback, thereby systematically evaluating their learning capabilities. To address the score saturation issue in current benchmarks, we introduce CATArena, a tournament-style evaluation platform featuring four diverse board and card games with open-ended scoring. By providing tasks without explicit upper score limits, CATArena enables continuous and dynamic evaluation of rapidly advancing agent capabilities. Experimental results and analyses involving both minimal and commercial code agents demonstrate that CATArena provides reliable, stable, and scalable benchmarking for core agent abilities, particularly learning ability and strategy coding.
AdvKT: An Adversarial Multi-Step Training Framework for Knowledge Tracing
Apr 07, 2025Knowledge Tracing (KT) monitors students' knowledge states and simulates their responses to question sequences. Existing KT models typically follow a single-step training paradigm, which leads to discrepancies with the multi-step inference process required in real-world simulations, resulting in significant error accumulation. This accumulation of error, coupled with the issue of data sparsity, can substantially degrade the performance of recommendation models in the intelligent tutoring systems. To address these challenges, we propose a novel Adversarial Multi-Step Training Framework for Knowledge Tracing (AdvKT), which, for the first time, focuses on the multi-step KT task. More specifically, AdvKT leverages adversarial learning paradigm involving a generator and a discriminator. The generator mimics high-reward responses, effectively reducing error accumulation across multiple steps, while the discriminator provides feedback to generate synthetic data. Additionally, we design specialized data augmentation techniques to enrich the training data with realistic variations, ensuring that the model generalizes well even in scenarios with sparse data. Experiments conducted on four real-world datasets demonstrate the superiority of AdvKT over existing KT models, showcasing its ability to address both error accumulation and data sparsity issues effectively.
Train Once for All: A Transitional Approach for Efficient Aspect Sentiment Triplet Extraction
Nov 29, 2024Aspect-Opinion Pair Extraction (AOPE) and Aspect Sentiment Triplet Extraction (ASTE) have gained significant attention in natural language processing. However, most existing methods are a pipelined framework, which extracts aspects/opinions and identifies their relations separately, leading to a drawback of error propagation and high time complexity. Towards this problem, we propose a transition-based pipeline to mitigate token-level bias and capture position-aware aspect-opinion relations. With the use of a fused dataset and contrastive learning optimization, our model learns robust action patterns and can optimize separate subtasks jointly, often with linear-time complexity. The results show that our model achieves the best performance on both the ASTE and AOPE tasks, outperforming the state-of-the-art methods by at least 6.98\% in the F1 measure. The code is available at https://github.com/Paparare/trans_aste.
SINKT: A Structure-Aware Inductive Knowledge Tracing Model with Large Language Model
Jul 01, 2024



Knowledge Tracing (KT) aims to determine whether students will respond correctly to the next question, which is a crucial task in intelligent tutoring systems (ITS). In educational KT scenarios, transductive ID-based methods often face severe data sparsity and cold start problems, where interactions between individual students and questions are sparse, and new questions and concepts consistently arrive in the database. In addition, existing KT models only implicitly consider the correlation between concepts and questions, lacking direct modeling of the more complex relationships in the heterogeneous graph of concepts and questions. In this paper, we propose a Structure-aware Inductive Knowledge Tracing model with large language model (dubbed SINKT), which, for the first time, introduces large language models (LLMs) and realizes inductive knowledge tracing. Firstly, SINKT utilizes LLMs to introduce structural relationships between concepts and constructs a heterogeneous graph for concepts and questions. Secondly, by encoding concepts and questions with LLMs, SINKT incorporates semantic information to aid prediction. Finally, SINKT predicts the student's response to the target question by interacting with the student's knowledge state and the question representation. Experiments on four real-world datasets demonstrate that SINKT achieves state-of-the-art performance among 12 existing transductive KT models. Additionally, we explore the performance of SINKT on the inductive KT task and provide insights into various modules.
CodeGRAG: Extracting Composed Syntax Graphs for Retrieval Augmented Cross-Lingual Code Generation
May 03, 2024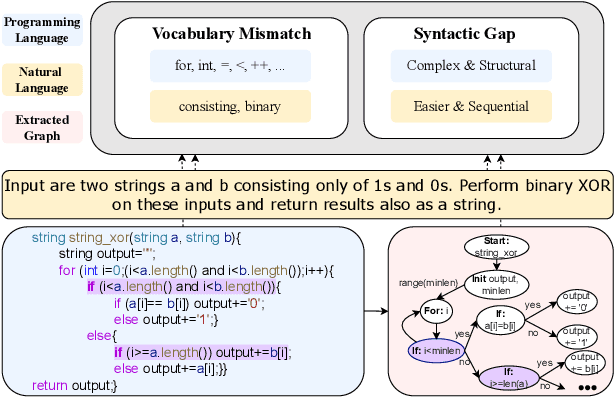
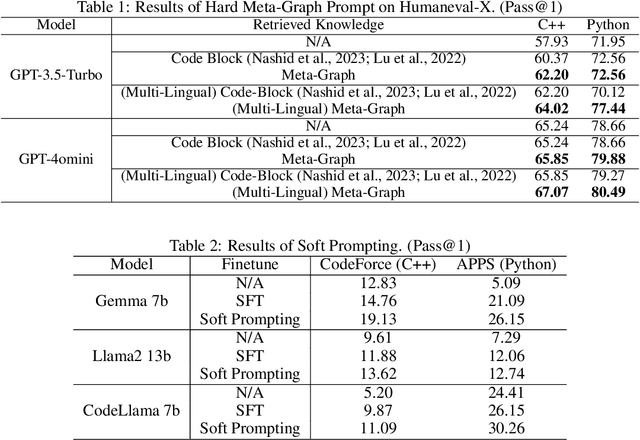
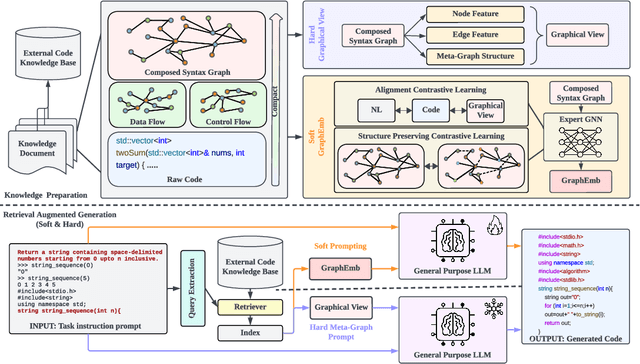
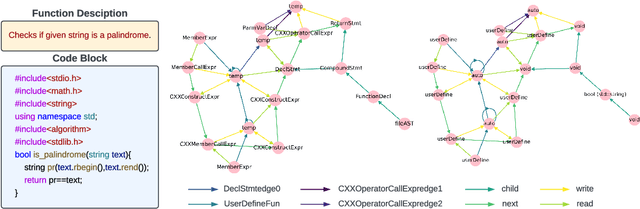
Utilizing large language models to generate codes has shown promising meaning in software development revolution. Despite the intelligence shown by the general large language models, their specificity in code generation can still be improved due to the syntactic gap and mismatched vocabulary existing among natural language and different programming languages. In addition, programming languages are inherently logical and complex, making them hard to be correctly generated. Existing methods rely on multiple prompts to the large language model to explore better solutions, which is expensive. In this paper, we propose Syntax Graph Retrieval Augmented Code Generation (CodeGRAG) to enhance the performance of LLMs in single-round code generation tasks. CodeGRAG extracts and summarizes the control flow and data flow of code blocks to fill the gap between programming languages and natural language. The extracted external structural knowledge models the inherent flows of code blocks, which can facilitate LLMs for better understanding of code syntax and serve as a bridge among different programming languages. CodeGRAG significantly improves the code generation ability of LLMs and can even offer performance gain for cross-lingual code generation, e.g., C++ for Python.
CodeApex: A Bilingual Programming Evaluation Benchmark for Large Language Models
Sep 10, 2023



With the emergence of Large Language Models (LLMs), there has been a significant improvement in the programming capabilities of models, attracting growing attention from researchers. We propose CodeApex, a bilingual benchmark dataset focusing on the programming comprehension and code generation abilities of LLMs. CodeApex comprises three types of multiple-choice questions: conceptual understanding, commonsense reasoning, and multi-hop reasoning, designed to evaluate LLMs on programming comprehension tasks. Additionally, CodeApex utilizes algorithmic questions and corresponding test cases to assess the code quality generated by LLMs. We evaluate 14 state-of-the-art LLMs, including both general-purpose and specialized models. GPT exhibits the best programming capabilities, achieving approximate accuracies of 50% and 56% on the two tasks, respectively. There is still significant room for improvement in programming tasks. We hope that CodeApex can serve as a reference for evaluating the coding capabilities of LLMs, further promoting their development and growth. Datasets are released at https://github.com/APEXLAB/CodeApex.git. CodeApex submission website is https://apex.sjtu.edu.cn/codeapex/.
An F-shape Click Model for Information Retrieval on Multi-block Mobile Pages
Jun 17, 2022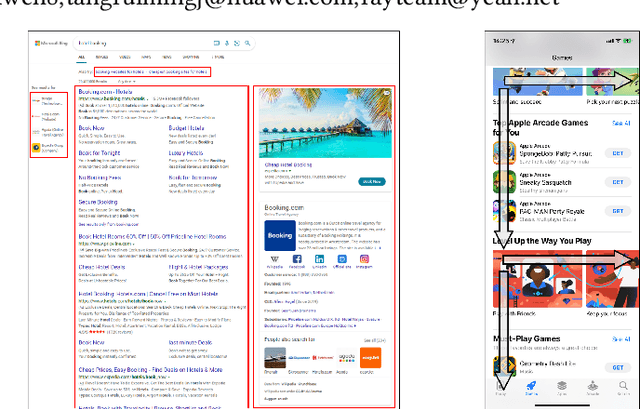


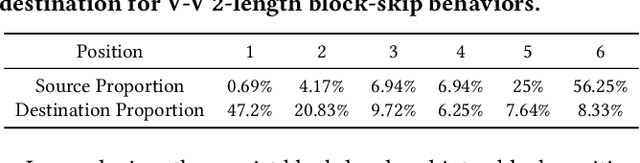
To provide click simulation or relevance estimation based on users' implicit interaction feedback, click models have been much studied during recent years. Most click models focus on user behaviors towards a single list. However, with the development of user interface (UI) design, the layout of displayed items on a result page tends to be multi-block (i.e., multi-list) style instead of a single list, which requires different assumptions to model user behaviors more accurately. There exist click models for multi-block pages in desktop contexts, but they cannot be directly applied to mobile scenarios due to different interaction manners, result types and especially multi-block presentation styles. In particular, multi-block mobile pages can normally be decomposed into interleavings of basic vertical blocks and horizontal blocks, thus resulting in typically F-shape forms. To mitigate gaps between desktop and mobile contexts for multi-block pages, we conduct a user eye-tracking study, and identify users' sequential browsing, block skip and comparison patterns on F-shape pages. These findings lead to the design of a novel F-shape Click Model (FSCM), which serves as a general solution to multi-block mobile pages. Firstly, we construct a directed acyclic graph (DAG) for each page, where each item is regarded as a vertex and each edge indicates the user's possible examination flow. Secondly, we propose DAG-structured GRUs and a comparison module to model users' sequential (sequential browsing, block skip) and non-sequential (comparison) behaviors respectively. Finally, we combine GRU states and comparison patterns to perform user click predictions. Experiments on a large-scale real-world dataset validate the effectiveness of FSCM on user behavior predictions compared with baseline models.