 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearn Like Humans: Use Meta-cognitive Reflection for Efficient Self-Improvement
Jan 17, 2026While Large Language Models (LLMs) enable complex autonomous behavior, current agents remain constrained by static, human-designed prompts that limit adaptability. Existing self-improving frameworks attempt to bridge this gap but typically rely on inefficient, multi-turn recursive loops that incur high computational costs. To address this, we propose Metacognitive Agent Reflective Self-improvement (MARS), a framework that achieves efficient self-evolution within a single recurrence cycle. Inspired by educational psychology, MARS mimics human learning by integrating principle-based reflection (abstracting normative rules to avoid errors) and procedural reflection (deriving step-by-step strategies for success). By synthesizing these insights into optimized instructions, MARS allows agents to systematically refine their reasoning logic without continuous online feedback. Extensive experiments on six benchmarks demonstrate that MARS outperforms state-of-the-art self-evolving systems while significantly reducing computational overhead.
DriveAgent: Multi-Agent Structured Reasoning with LLM and Multimodal Sensor Fusion for Autonomous Driving
May 04, 2025
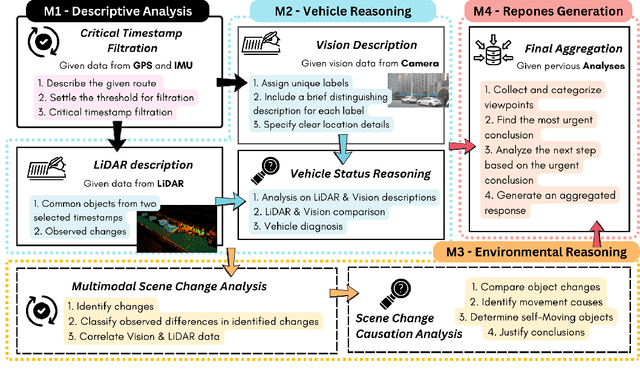
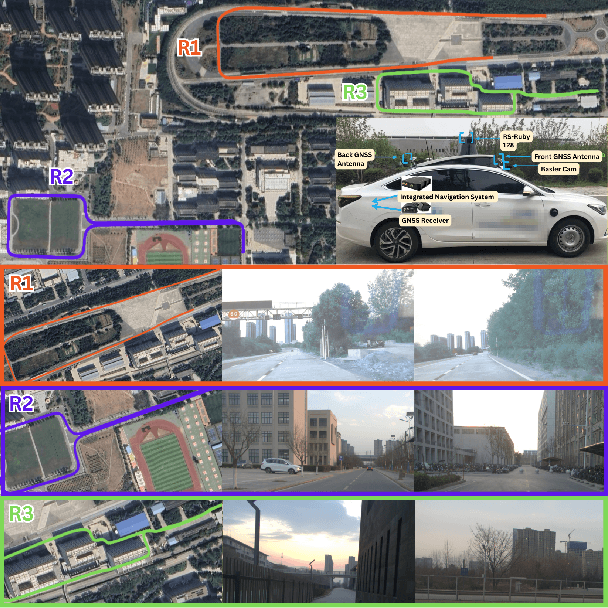
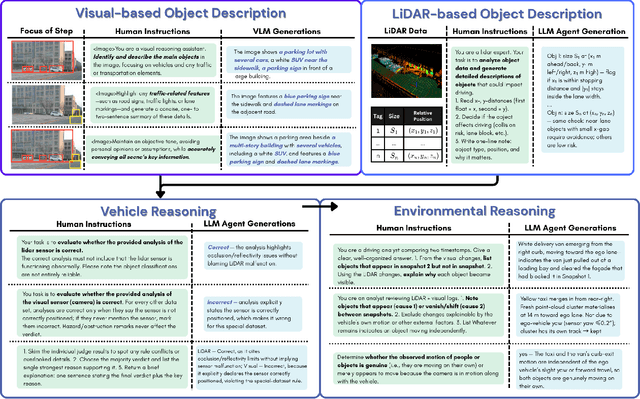
We introduce DriveAgent, a novel multi-agent autonomous driving framework that leverages large language model (LLM) reasoning combined with multimodal sensor fusion to enhance situational understanding and decision-making. DriveAgent uniquely integrates diverse sensor modalities-including camera, LiDAR, GPS, and IMU-with LLM-driven analytical processes structured across specialized agents. The framework operates through a modular agent-based pipeline comprising four principal modules: (i) a descriptive analysis agent identifying critical sensor data events based on filtered timestamps, (ii) dedicated vehicle-level analysis conducted by LiDAR and vision agents that collaboratively assess vehicle conditions and movements, (iii) environmental reasoning and causal analysis agents explaining contextual changes and their underlying mechanisms, and (iv) an urgency-aware decision-generation agent prioritizing insights and proposing timely maneuvers. This modular design empowers the LLM to effectively coordinate specialized perception and reasoning agents, delivering cohesive, interpretable insights into complex autonomous driving scenarios. Extensive experiments on challenging autonomous driving datasets demonstrate that DriveAgent is achieving superior performance on multiple metrics against baseline methods. These results validate the efficacy of the proposed LLM-driven multi-agent sensor fusion framework, underscoring its potential to substantially enhance the robustness and reliability of autonomous driving systems.
Train Once for All: A Transitional Approach for Efficient Aspect Sentiment Triplet Extraction
Nov 29, 2024Aspect-Opinion Pair Extraction (AOPE) and Aspect Sentiment Triplet Extraction (ASTE) have gained significant attention in natural language processing. However, most existing methods are a pipelined framework, which extracts aspects/opinions and identifies their relations separately, leading to a drawback of error propagation and high time complexity. Towards this problem, we propose a transition-based pipeline to mitigate token-level bias and capture position-aware aspect-opinion relations. With the use of a fused dataset and contrastive learning optimization, our model learns robust action patterns and can optimize separate subtasks jointly, often with linear-time complexity. The results show that our model achieves the best performance on both the ASTE and AOPE tasks, outperforming the state-of-the-art methods by at least 6.98\% in the F1 measure. The code is available at https://github.com/Paparare/trans_aste.
Mitigating Biases to Embrace Diversity: A Comprehensive Annotation Benchmark for Toxic Language
Oct 17, 2024This study introduces a prescriptive annotation benchmark grounded in humanities research to ensure consistent, unbiased labeling of offensive language, particularly for casual and non-mainstream language uses. We contribute two newly annotated datasets that achieve higher inter-annotator agreement between human and language model (LLM) annotations compared to original datasets based on descriptive instructions. Our experiments show that LLMs can serve as effective alternatives when professional annotators are unavailable. Moreover, smaller models fine-tuned on multi-source LLM-annotated data outperform models trained on larger, single-source human-annotated datasets. These findings highlight the value of structured guidelines in reducing subjective variability, maintaining performance with limited data, and embracing language diversity. Content Warning: This article only analyzes offensive language for academic purposes. Discretion is advised.