 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMining Latent Relationships among Clients: Peer-to-peer Federated Learning with Adaptive Neighbor Matching
Mar 23, 2022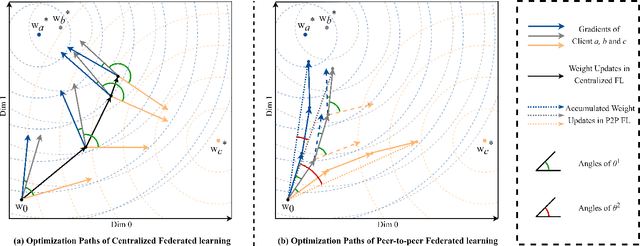

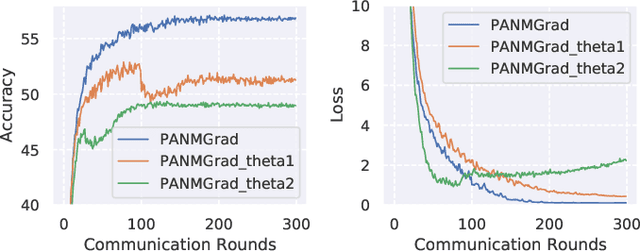
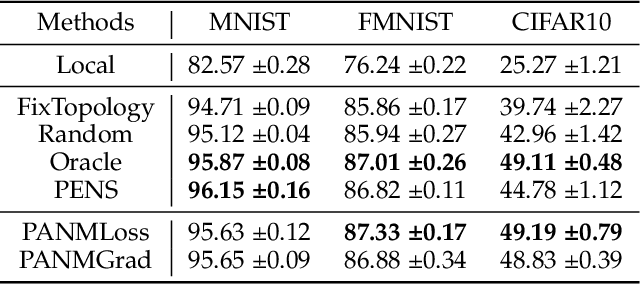
In federated learning (FL), clients may have diverse objectives, merging all clients' knowledge into one global model will cause negative transfers to local performance. Thus, clustered FL is proposed to group similar clients into clusters and maintain several global models. Nevertheless, current clustered FL algorithms require the assumption of the number of clusters, they are not effective enough to explore the latent relationships among clients. However, we take advantage of peer-to-peer (P2P) FL, where clients communicate with neighbors without a central server and propose an algorithm that enables clients to form an effective communication topology in a decentralized manner without assuming the number of clusters. Additionally, the P2P setting will release the concerns caused by the central server in centralized FL, such as reliability and communication bandwidth problems. In our method, 1) we present two novel metrics for measuring client similarity, applicable under P2P protocols; 2) we devise a two-stage algorithm, in the first stage, an efficient method to enable clients to match same-cluster neighbors with high confidence is proposed; 3) then in the second stage, a heuristic method based on Expectation Maximization under the Gaussian Mixture Model assumption of similarities is used for clients to discover more neighbors with similar objectives. We make a theoretical analysis of how our work is superior to the P2P FL counterpart and extensive experiments show that our method outperforms all P2P FL baselines and has comparable or even superior performance to centralized cluster FL. Moreover, results show that our method is much effective in mining latent cluster relationships under various heterogeneity without assuming the number of clusters and it is effective even under low communication budgets.
How global observation works in Federated Learning: Integrating vertical training into Horizontal Federated Learning
Dec 10, 2021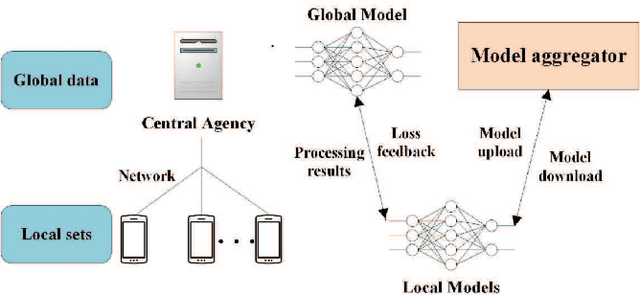
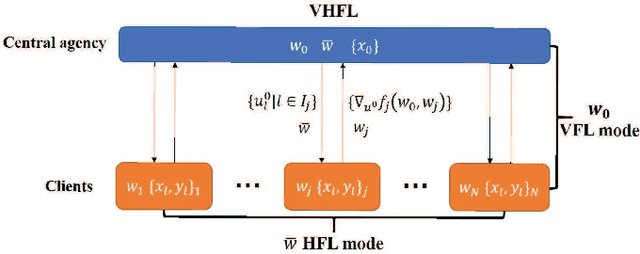
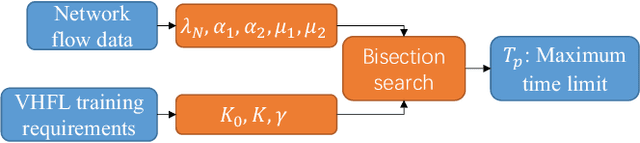
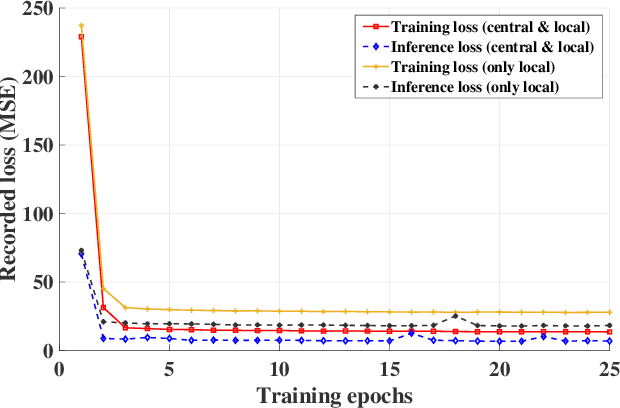
Federated learning (FL) has recently emerged as a transformative paradigm that jointly train a model with distributed data sets in IoT while avoiding the need for central data collection. Due to the limited observation range, such data sets can only reflect local information, which limits the quality of trained models. In practice, the global information and local observations would require a joint consideration for learning to make a reasonable policy. However, in horizontal FL, the central agency only acts as a model aggregator without utilizing its global observation to further improve the model. This could significantly degrade the performance in some missions such as traffic flow prediction in network systems, where the global information may enhance the accuracy. Meanwhile, the global feature may not be directly transmitted to agents for data security. How to utilize the global observation residing in the central agency while protecting its safety thus rises up as an important problem in FL. In this paper, we develop a vertical-horizontal federated learning (VHFL) process, where the global feature is shared with the agents in a procedure similar to that of vertical FL without any extra communication rounds. By considering the delay and packet loss, we will analyze VHFL convergence and validate its performance by experiments. It is shown that the proposed VHFL could enhance the accuracy compared with horizontal FL while still protecting the security of global data.
Unified Group Fairness on Federated Learning
Nov 09, 2021
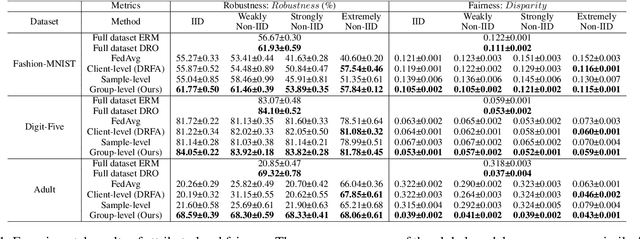
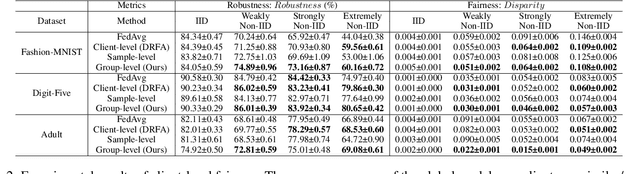
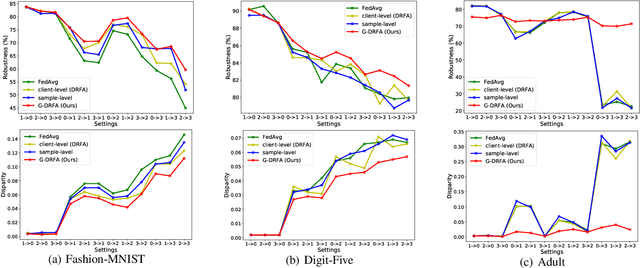
Federated learning (FL) has emerged as an important machine learning paradigm where a global model is trained based on the private data from distributed clients. However, most of existing FL algorithms cannot guarantee the performance fairness towards different clients or different groups of samples because of the distribution shift. Recent researches focus on achieving fairness among clients, but they ignore the fairness towards different groups formed by sensitive attribute(s) (e.g., gender and/or race), which is important and practical in real applications. To bridge this gap, we formulate the goal of unified group fairness on FL which is to learn a fair global model with similar performance on different groups. To achieve the unified group fairness for arbitrary sensitive attribute(s), we propose a novel FL algorithm, named Group Distributionally Robust Federated Averaging (G-DRFA), which mitigates the distribution shift across groups with theoretical analysis of convergence rate. Specifically, we treat the performance of the federated global model at each group as an objective and employ the distributionally robust techniques to maximize the performance of the worst-performing group over an uncertainty set by group reweighting. We validate the advantages of the G-DRFA algorithm with various kinds of distribution shift settings in experiments, and the results show that G-DRFA algorithm outperforms the existing fair federated learning algorithms on unified group fairness.
Convergence Analysis and System Design for Federated Learning over Wireless Networks
Apr 30, 2021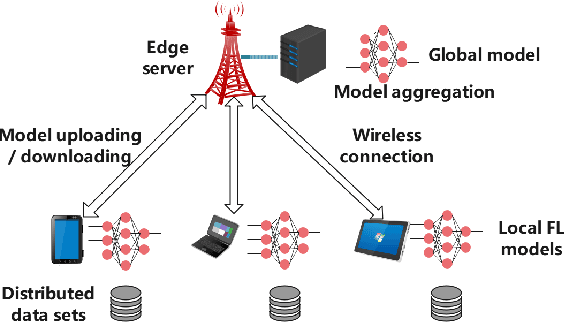
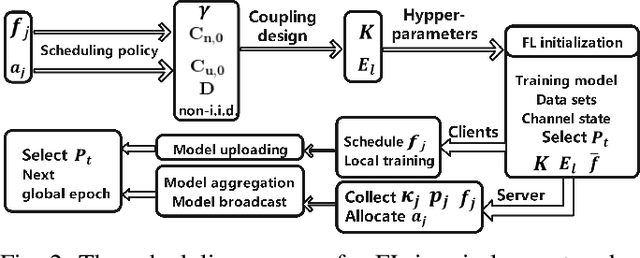
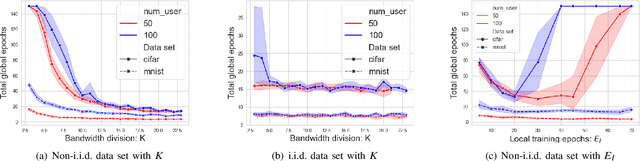
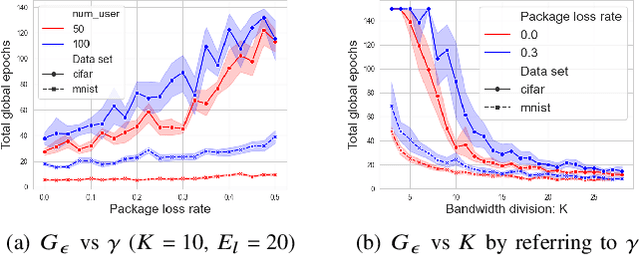
Federated learning (FL) has recently emerged as an important and promising learning scheme in IoT, enabling devices to jointly learn a model without sharing their raw data sets. However, as the training data in FL is not collected and stored centrally, FL training requires frequent model exchange, which is largely affected by the wireless communication network. Therein, limited bandwidth and random package loss restrict interactions in training. Meanwhile, the insufficient message synchronization among distributed clients could also affect FL convergence. In this paper, we analyze the convergence rate of FL training considering the joint impact of communication network and training settings. Further by considering the training costs in terms of time and power, the optimal scheduling problems for communication networks are formulated. The developed theoretical results can be used to assist the system parameter selections and explain the principle of how the wireless communication system could influence the distributed training process and network scheduling.
Towards Big data processing in IoT: network management for online edge data processing
May 05, 2019
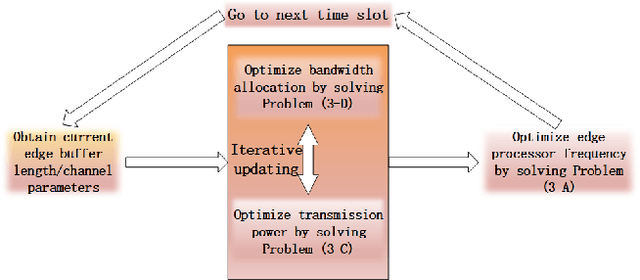
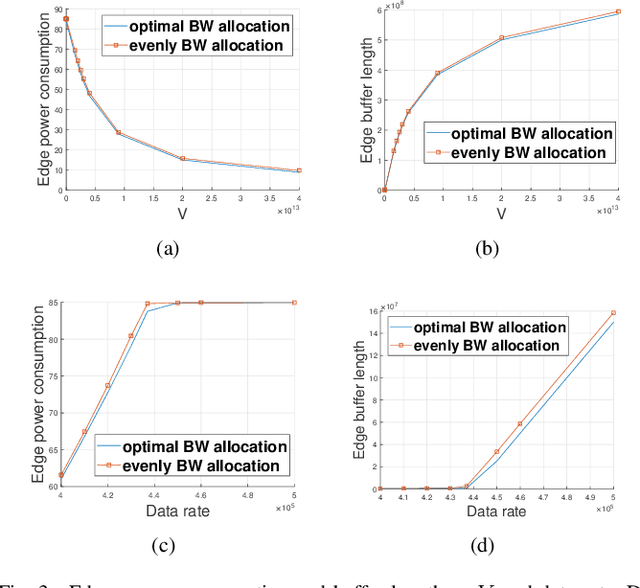
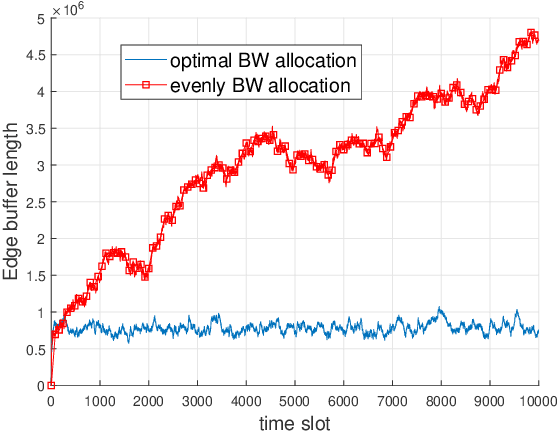
Heavy data load and wide cover range have always been crucial problems for internet of things (IoT). However, in mobile-edge computing (MEC) network, the huge data can be partly processed at the edge. In this paper, a MEC-based big data analysis network is discussed. The raw data generated by distributed network terminals are collected and processed by edge servers. The edge servers split out a large sum of redundant data and transmit extracted information to the center cloud for further analysis. However, for consideration of limited edge computation ability, part of the raw data in huge data sources may be directly transmitted to the cloud. To manage limited resources online, we propose an algorithm based on Lyapunov optimization to jointly optimize the policy of edge processor frequency, transmission power and bandwidth allocation. The algorithm aims at stabilizing data processing delay and saving energy without knowing probability distributions of data sources. The proposed network management algorithm may contribute to big data processing in future IoT.
Model change detection with application to machine learning
Nov 19, 2018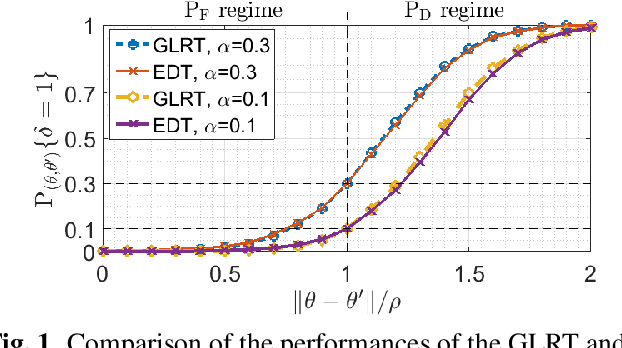
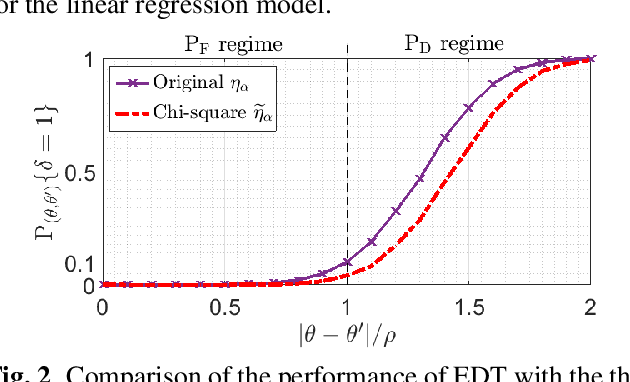
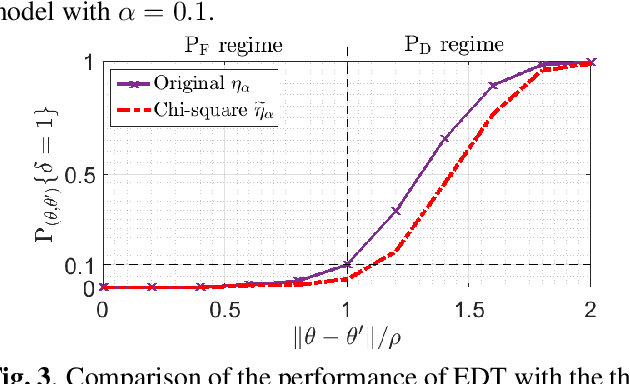
Model change detection is studied, in which there are two sets of samples that are independently and identically distributed (i.i.d.) according to a pre-change probabilistic model with parameter $\theta$, and a post-change model with parameter $\theta'$, respectively. The goal is to detect whether the change in the model is significant, i.e., whether the difference between the pre-change parameter and the post-change parameter $\|\theta-\theta'\|_2$ is larger than a pre-determined threshold $\rho$. The problem is considered in a Neyman-Pearson setting, where the goal is to maximize the probability of detection under a false alarm constraint. Since the generalized likelihood ratio test (GLRT) is difficult to compute in this problem, we construct an empirical difference test (EDT), which approximates the GLRT and has low computational complexity. Moreover, we provide an approximation method to set the threshold of the EDT to meet the false alarm constraint. Experiments with linear regression and logistic regression are conducted to validate the proposed algorithms.
Active and Adaptive Sequential learning
May 29, 2018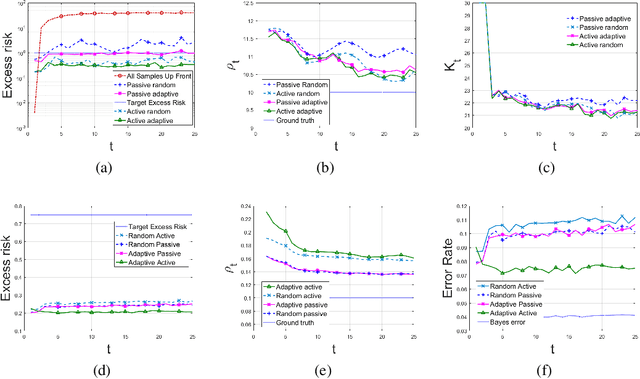
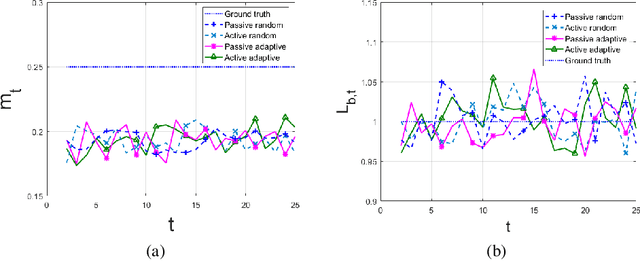
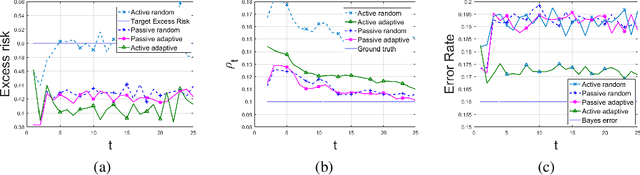
A framework is introduced for actively and adaptively solving a sequence of machine learning problems, which are changing in bounded manner from one time step to the next. An algorithm is developed that actively queries the labels of the most informative samples from an unlabeled data pool, and that adapts to the change by utilizing the information acquired in the previous steps. Our analysis shows that the proposed active learning algorithm based on stochastic gradient descent achieves a near-optimal excess risk performance for maximum likelihood estimation. Furthermore, an estimator of the change in the learning problems using the active learning samples is constructed, which provides an adaptive sample size selection rule that guarantees the excess risk is bounded for sufficiently large number of time steps. Experiments with synthetic and real data are presented to validate our algorithm and theoretical results.
Semi-centralized control for multi-robot formation and theoretical lower bound
Sep 12, 2017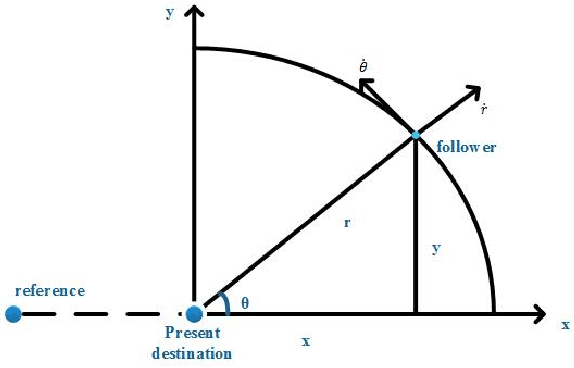

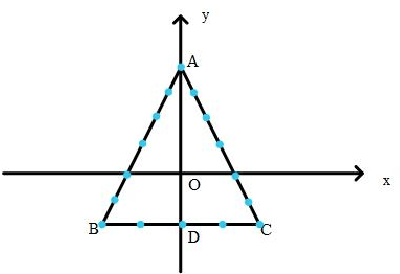
Multi-robot formation control enables robots to cooperate as a working group in completing complex tasks, which has been widely used in both civilian and military scenarios. Before moving to reach a given formation, each robot should choose a position from the formation so that the whole system cost is minimized. To solve the problem, we formulate an optimization problem in terms of the total moving distance and give a solution by the Hungarian method. To analyze the deviation of the achieved formation from the ideal one, we obtain the lower bound of formation bias with respect to system's parameters based on notions in information theory. As an extension, we discuss methods of transformation between different formations. Some theoretical results are obtained to give a guidance of the system design.