 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-agent Policy Reciprocity with Theoretical Guarantee
Paper and Code
Apr 12, 2023
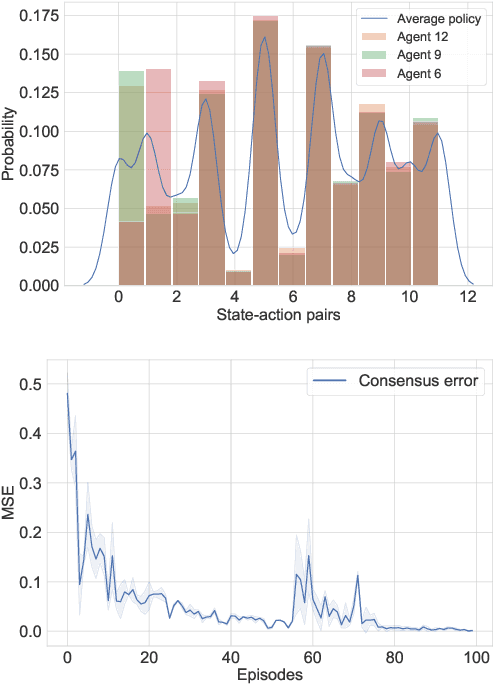
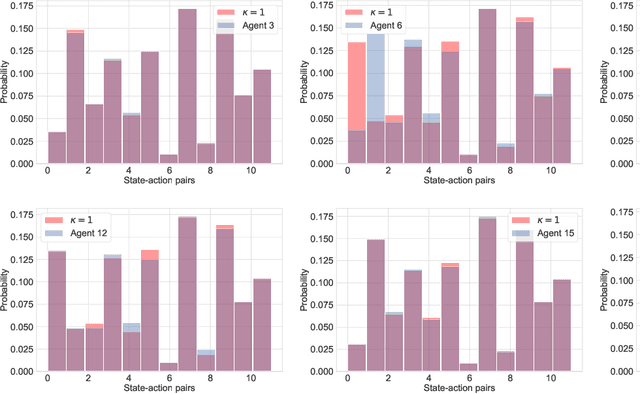
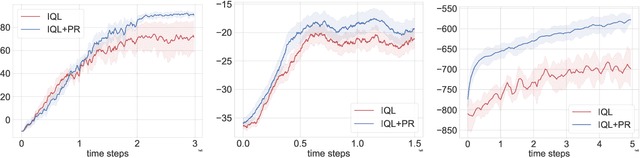
Modern multi-agent reinforcement learning (RL) algorithms hold great potential for solving a variety of real-world problems. However, they do not fully exploit cross-agent knowledge to reduce sample complexity and improve performance. Although transfer RL supports knowledge sharing, it is hyperparameter sensitive and complex. To solve this problem, we propose a novel multi-agent policy reciprocity (PR) framework, where each agent can fully exploit cross-agent policies even in mismatched states. We then define an adjacency space for mismatched states and design a plug-and-play module for value iteration, which enables agents to infer more precise returns. To improve the scalability of PR, deep PR is proposed for continuous control tasks. Moreover, theoretical analysis shows that agents can asymptotically reach consensus through individual perceived rewards and converge to an optimal value function, which implies the stability and effectiveness of PR, respectively. Experimental results on discrete and continuous environments demonstrate that PR outperforms various existing RL and transfer RL methods.