 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnts: An Efficient Three-party Training Framework for Decision Trees by Communication Optimization
Jun 12, 2024
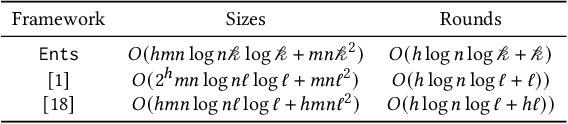
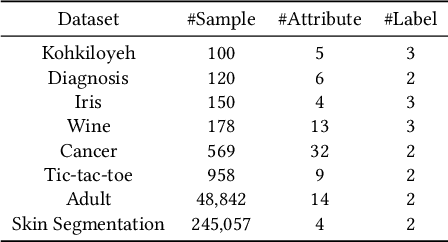
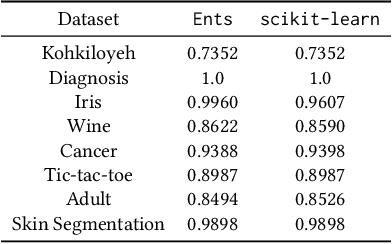
Multi-party training frameworks for decision trees based on secure multi-party computation enable multiple parties to train high-performance models on distributed private data with privacy preservation. The training process essentially involves frequent dataset splitting according to the splitting criterion (e.g. Gini impurity). However, existing multi-party training frameworks for decision trees demonstrate communication inefficiency due to the following issues: (1) They suffer from huge communication overhead in securely splitting a dataset with continuous attributes. (2) They suffer from huge communication overhead due to performing almost all the computations on a large ring to accommodate the secure computations for the splitting criterion. In this paper, we are motivated to present an efficient three-party training framework, namely Ents, for decision trees by communication optimization. For the first issue, we present a series of training protocols based on the secure radix sort protocols to efficiently and securely split a dataset with continuous attributes. For the second issue, we propose an efficient share conversion protocol to convert shares between a small ring and a large ring to reduce the communication overhead incurred by performing almost all the computations on a large ring. Experimental results from eight widely used datasets show that Ents outperforms state-of-the-art frameworks by $5.5\times \sim 9.3\times$ in communication sizes and $3.9\times \sim 5.3\times$ in communication rounds. In terms of training time, Ents yields an improvement of $3.5\times \sim 6.7\times$. To demonstrate its practicality, Ents requires less than three hours to securely train a decision tree on a widely used real-world dataset (Skin Segmentation) with more than 245,000 samples in the WAN setting.
SoK: Training Machine Learning Models over Multiple Sources with Privacy Preservation
Dec 06, 2020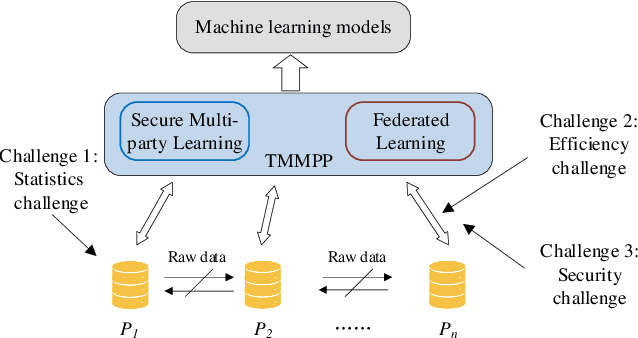
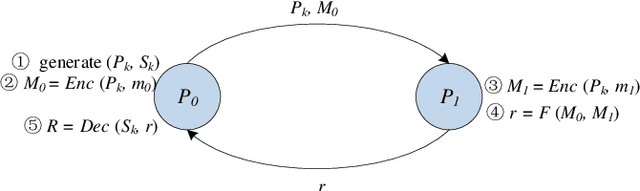
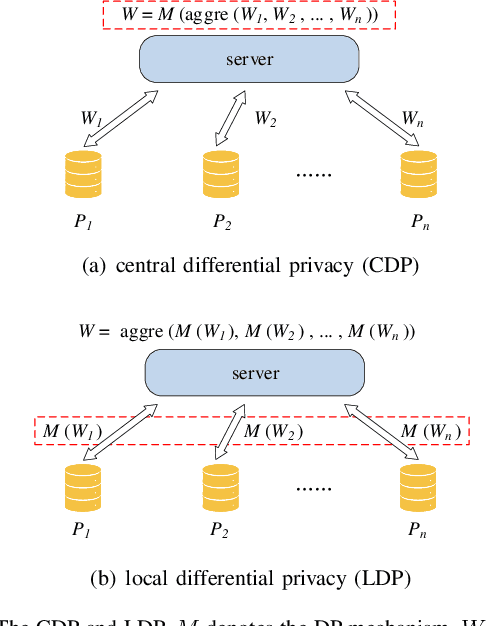
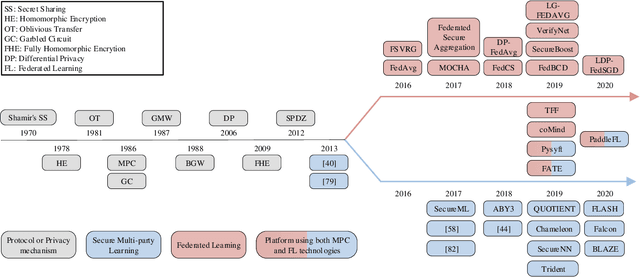
Nowadays, gathering high-quality training data from multiple data controllers with privacy preservation is a key challenge to train high-quality machine learning models. The potential solutions could dramatically break the barriers among isolated data corpus, and consequently enlarge the range of data available for processing. To this end, both academia researchers and industrial vendors are recently strongly motivated to propose two main-stream folders of solutions: 1) Secure Multi-party Learning (MPL for short); and 2) Federated Learning (FL for short). These two solutions have their advantages and limitations when we evaluate them from privacy preservation, ways of communication, communication overhead, format of data, the accuracy of trained models, and application scenarios. Motivated to demonstrate the research progress and discuss the insights on the future directions, we thoroughly investigate these protocols and frameworks of both MPL and FL. At first, we define the problem of training machine learning models over multiple data sources with privacy-preserving (TMMPP for short). Then, we compare the recent studies of TMMPP from the aspects of the technical routes, parties supported, data partitioning, threat model, and supported machine learning models, to show the advantages and limitations. Next, we introduce the state-of-the-art platforms which support online training over multiple data sources. Finally, we discuss the potential directions to resolve the problem of TMMPP.