 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnts: An Efficient Three-party Training Framework for Decision Trees by Communication Optimization
Jun 12, 2024
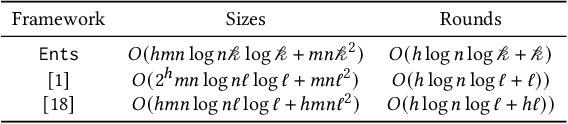
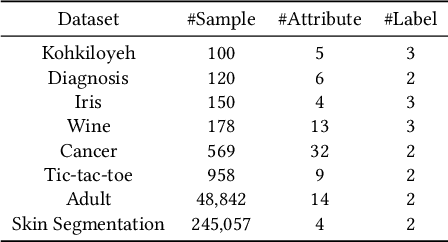
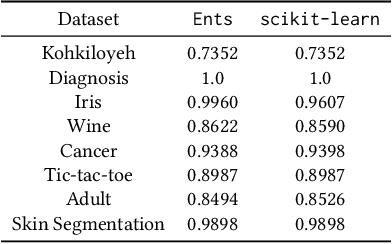
Multi-party training frameworks for decision trees based on secure multi-party computation enable multiple parties to train high-performance models on distributed private data with privacy preservation. The training process essentially involves frequent dataset splitting according to the splitting criterion (e.g. Gini impurity). However, existing multi-party training frameworks for decision trees demonstrate communication inefficiency due to the following issues: (1) They suffer from huge communication overhead in securely splitting a dataset with continuous attributes. (2) They suffer from huge communication overhead due to performing almost all the computations on a large ring to accommodate the secure computations for the splitting criterion. In this paper, we are motivated to present an efficient three-party training framework, namely Ents, for decision trees by communication optimization. For the first issue, we present a series of training protocols based on the secure radix sort protocols to efficiently and securely split a dataset with continuous attributes. For the second issue, we propose an efficient share conversion protocol to convert shares between a small ring and a large ring to reduce the communication overhead incurred by performing almost all the computations on a large ring. Experimental results from eight widely used datasets show that Ents outperforms state-of-the-art frameworks by $5.5\times \sim 9.3\times$ in communication sizes and $3.9\times \sim 5.3\times$ in communication rounds. In terms of training time, Ents yields an improvement of $3.5\times \sim 6.7\times$. To demonstrate its practicality, Ents requires less than three hours to securely train a decision tree on a widely used real-world dataset (Skin Segmentation) with more than 245,000 samples in the WAN setting.
MAP: Model Aggregation and Personalization in Federated Learning with Incomplete Classes
Apr 14, 2024
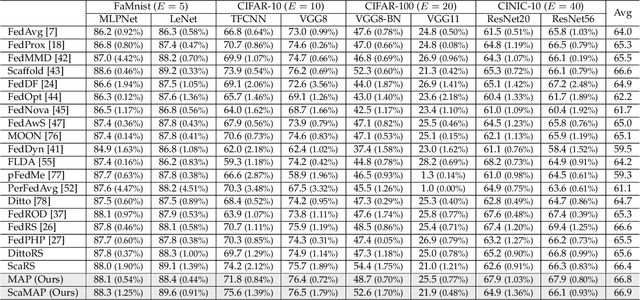
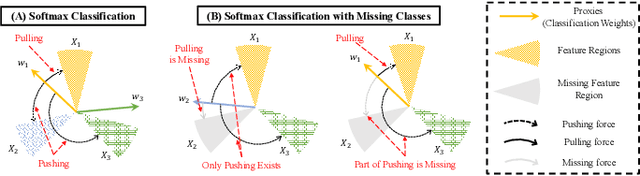
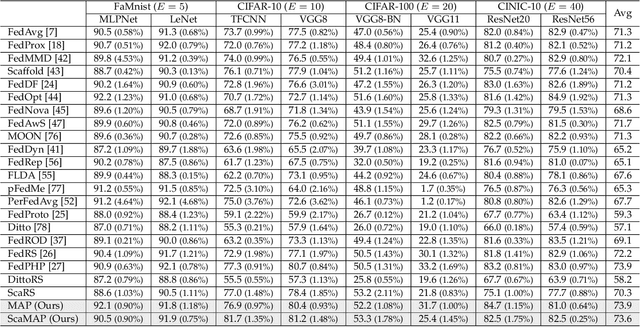
In some real-world applications, data samples are usually distributed on local devices, where federated learning (FL) techniques are proposed to coordinate decentralized clients without directly sharing users' private data. FL commonly follows the parameter server architecture and contains multiple personalization and aggregation procedures. The natural data heterogeneity across clients, i.e., Non-I.I.D. data, challenges both the aggregation and personalization goals in FL. In this paper, we focus on a special kind of Non-I.I.D. scene where clients own incomplete classes, i.e., each client can only access a partial set of the whole class set. The server aims to aggregate a complete classification model that could generalize to all classes, while the clients are inclined to improve the performance of distinguishing their observed classes. For better model aggregation, we point out that the standard softmax will encounter several problems caused by missing classes and propose "restricted softmax" as an alternative. For better model personalization, we point out that the hard-won personalized models are not well exploited and propose "inherited private model" to store the personalization experience. Our proposed algorithm named MAP could simultaneously achieve the aggregation and personalization goals in FL. Abundant experimental studies verify the superiorities of our algorithm.
ECLM: Efficient Edge-Cloud Collaborative Learning with Continuous Environment Adaptation
Nov 18, 2023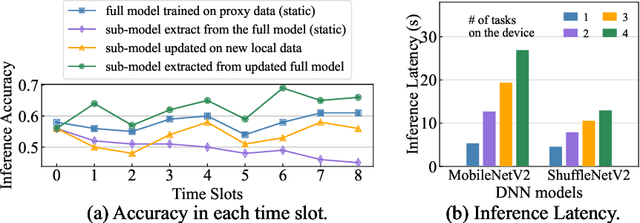
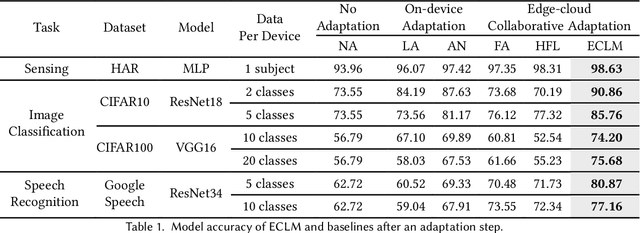
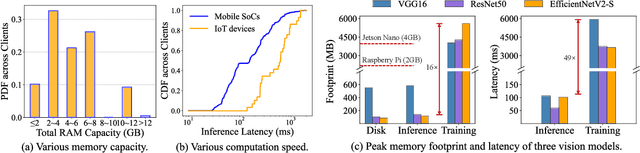
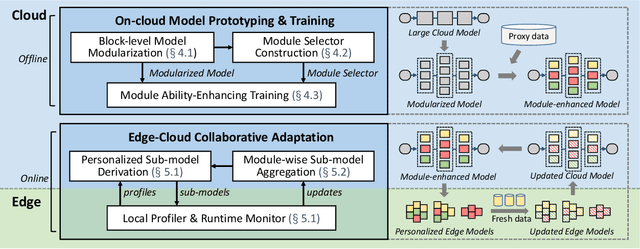
Pervasive mobile AI applications primarily employ one of the two learning paradigms: cloud-based learning (with powerful large models) or on-device learning (with lightweight small models). Despite their own advantages, neither paradigm can effectively handle dynamic edge environments with frequent data distribution shifts and on-device resource fluctuations, inevitably suffering from performance degradation. In this paper, we propose ECLM, an edge-cloud collaborative learning framework for rapid model adaptation for dynamic edge environments. We first propose a novel block-level model decomposition design to decompose the original large cloud model into multiple combinable modules. By flexibly combining a subset of the modules, this design enables the derivation of compact, task-specific sub-models for heterogeneous edge devices from the large cloud model, and the seamless integration of new knowledge learned on these devices into the cloud model periodically. As such, ECLM ensures that the cloud model always provides up-to-date sub-models for edge devices. We further propose an end-to-end learning framework that incorporates the modular model design into an efficient model adaptation pipeline including an offline on-cloud model prototyping and training stage, and an online edge-cloud collaborative adaptation stage. Extensive experiments over various datasets demonstrate that ECLM significantly improves model performance (e.g., 18.89% accuracy increase) and resource efficiency (e.g., 7.12x communication cost reduction) in adapting models to dynamic edge environments by efficiently collaborating the edge and the cloud models.
Asymmetric Temperature Scaling Makes Larger Networks Teach Well Again
Oct 11, 2022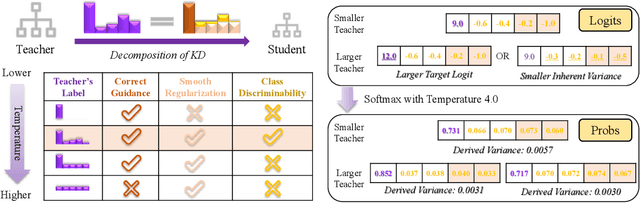

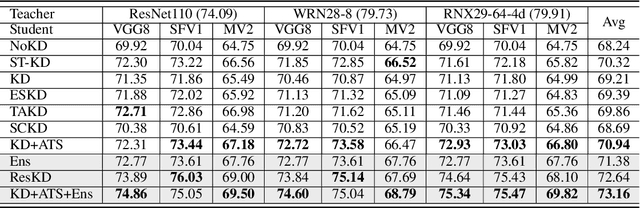

Knowledge Distillation (KD) aims at transferring the knowledge of a well-performed neural network (the {\it teacher}) to a weaker one (the {\it student}). A peculiar phenomenon is that a more accurate model doesn't necessarily teach better, and temperature adjustment can neither alleviate the mismatched capacity. To explain this, we decompose the efficacy of KD into three parts: {\it correct guidance}, {\it smooth regularization}, and {\it class discriminability}. The last term describes the distinctness of {\it wrong class probabilities} that the teacher provides in KD. Complex teachers tend to be over-confident and traditional temperature scaling limits the efficacy of {\it class discriminability}, resulting in less discriminative wrong class probabilities. Therefore, we propose {\it Asymmetric Temperature Scaling (ATS)}, which separately applies a higher/lower temperature to the correct/wrong class. ATS enlarges the variance of wrong class probabilities in the teacher's label and makes the students grasp the absolute affinities of wrong classes to the target class as discriminative as possible. Both theoretical analysis and extensive experimental results demonstrate the effectiveness of ATS. The demo developed in Mindspore is available at \url{https://gitee.com/lxcnju/ats-mindspore} and will be available at \url{https://gitee.com/mindspore/models/tree/master/research/cv/ats}.
Avoid Overfitting User Specific Information in Federated Keyword Spotting
Jun 17, 2022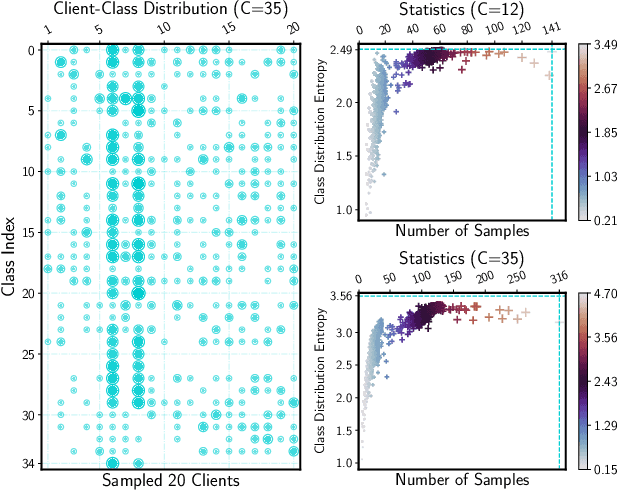
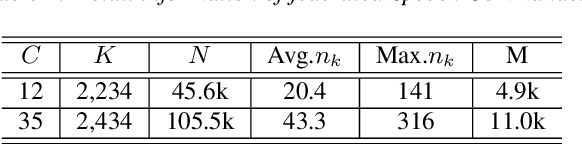
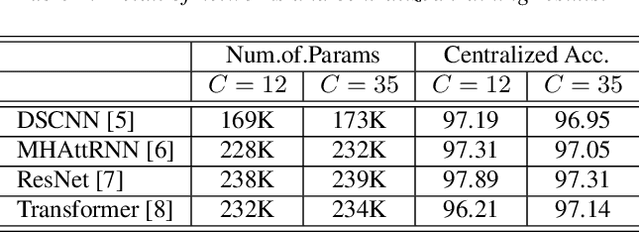
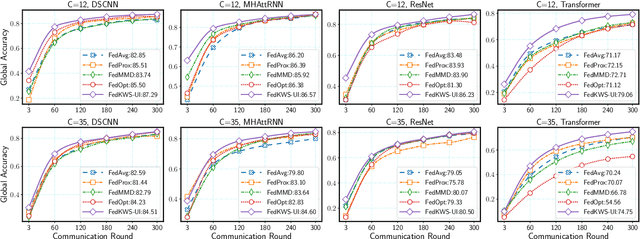
Keyword spotting (KWS) aims to discriminate a specific wake-up word from other signals precisely and efficiently for different users. Recent works utilize various deep networks to train KWS models with all users' speech data centralized without considering data privacy. Federated KWS (FedKWS) could serve as a solution without directly sharing users' data. However, the small amount of data, different user habits, and various accents could lead to fatal problems, e.g., overfitting or weight divergence. Hence, we propose several strategies to encourage the model not to overfit user-specific information in FedKWS. Specifically, we first propose an adversarial learning strategy, which updates the downloaded global model against an overfitted local model and explicitly encourages the global model to capture user-invariant information. Furthermore, we propose an adaptive local training strategy, letting clients with more training data and more uniform class distributions undertake more local update steps. Equivalently, this strategy could weaken the negative impacts of those users whose data is less qualified. Our proposed FedKWS-UI could explicitly and implicitly learn user-invariant information in FedKWS. Abundant experimental results on federated Google Speech Commands verify the effectiveness of FedKWS-UI.
Federated Learning with Position-Aware Neurons
Apr 02, 2022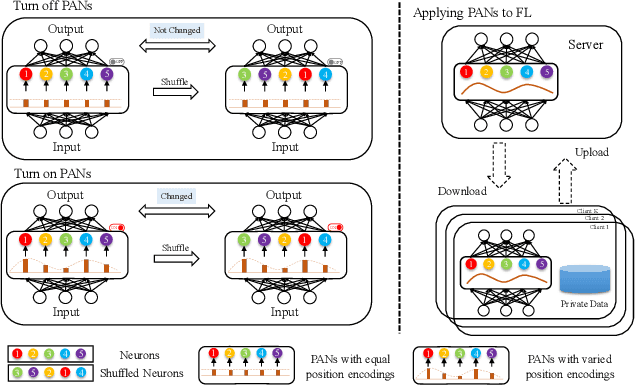

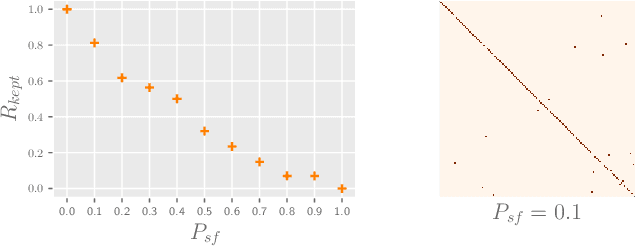
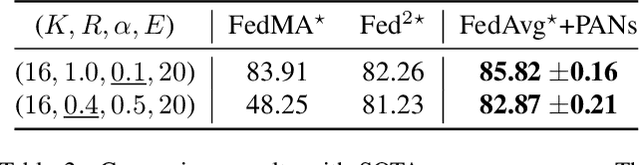
Federated Learning (FL) fuses collaborative models from local nodes without centralizing users' data. The permutation invariance property of neural networks and the non-i.i.d. data across clients make the locally updated parameters imprecisely aligned, disabling the coordinate-based parameter averaging. Traditional neurons do not explicitly consider position information. Hence, we propose Position-Aware Neurons (PANs) as an alternative, fusing position-related values (i.e., position encodings) into neuron outputs. PANs couple themselves to their positions and minimize the possibility of dislocation, even updating on heterogeneous data. We turn on/off PANs to disable/enable the permutation invariance property of neural networks. PANs are tightly coupled with positions when applied to FL, making parameters across clients pre-aligned and facilitating coordinate-based parameter averaging. PANs are algorithm-agnostic and could universally improve existing FL algorithms. Furthermore, "FL with PANs" is simple to implement and computationally friendly.
Domain Adaptation without Model Transferring
Aug 03, 2021
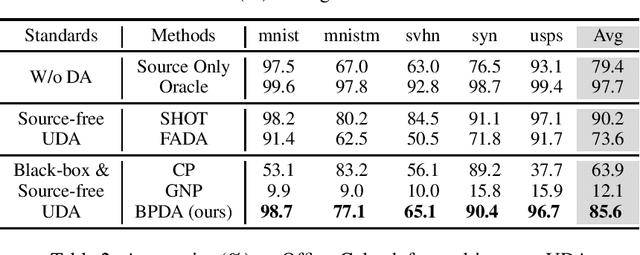

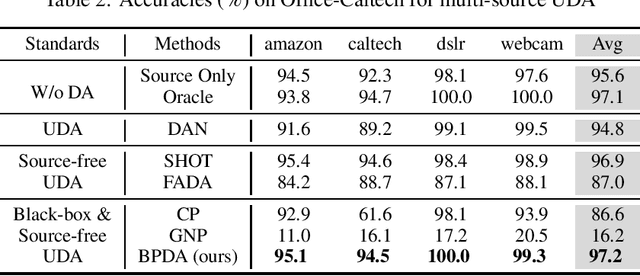
In recent years, researchers have been paying increasing attention to the threats brought by deep learning models to data security and privacy, especially in the field of domain adaptation. Existing unsupervised domain adaptation (UDA) methods can achieve promising performance without transferring data from source domain to target domain. However, UDA with representation alignment or self-supervised pseudo-labeling relies on the transferred source models. In many data-critical scenarios, methods based on model transferring may suffer from membership inference attacks and expose private data. In this paper, we aim to overcome a challenging new setting where the source models cannot be transferred to the target domain. We propose Domain Adaptation without Source Model, which refines information from source model. In order to gain more informative results, we further propose Distributionally Adversarial Training (DAT) to align the distribution of source data with that of target data. Experimental results on benchmarks of Digit-Five, Office-Caltech, Office-31, Office-Home, and DomainNet demonstrate the feasibility of our method without model transferring.
Preliminary Steps Towards Federated Sentiment Classification
Jul 26, 2021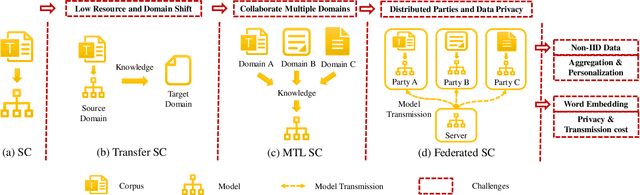
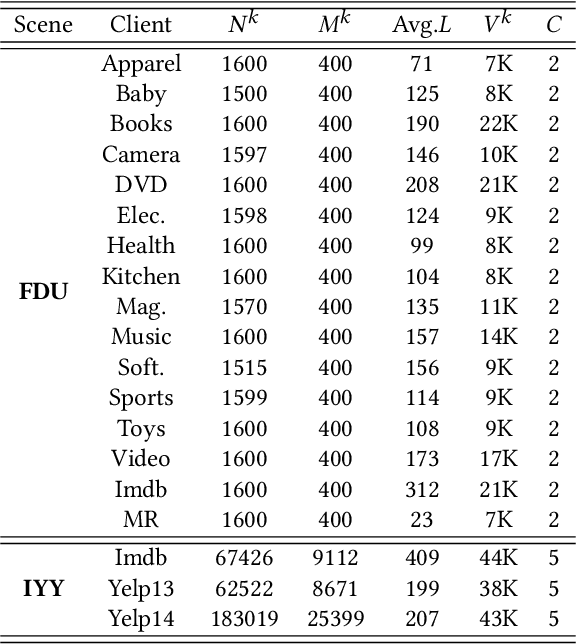
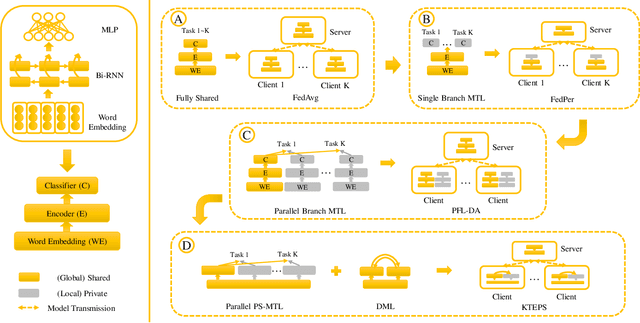
Automatically mining sentiment tendency contained in natural language is a fundamental research to some artificial intelligent applications, where solutions alternate with challenges. Transfer learning and multi-task learning techniques have been leveraged to mitigate the supervision sparsity and collaborate multiple heterogeneous domains correspondingly. Recent years, the sensitive nature of users' private data raises another challenge for sentiment classification, i.e., data privacy protection. In this paper, we resort to federated learning for multiple domain sentiment classification under the constraint that the corpora must be stored on decentralized devices. In view of the heterogeneous semantics across multiple parties and the peculiarities of word embedding, we pertinently provide corresponding solutions. First, we propose a Knowledge Transfer Enhanced Private-Shared (KTEPS) framework for better model aggregation and personalization in federated sentiment classification. Second, we propose KTEPS$^\star$ with the consideration of the rich semantic and huge embedding size properties of word vectors, utilizing Projection-based Dimension Reduction (PDR) methods for privacy protection and efficient transmission simultaneously. We propose two federated sentiment classification scenes based on public benchmarks, and verify the superiorities of our proposed methods with abundant experimental investigations.
Aggregate or Not? Exploring Where to Privatize in DNN Based Federated Learning Under Different Non-IID Scenes
Jul 26, 2021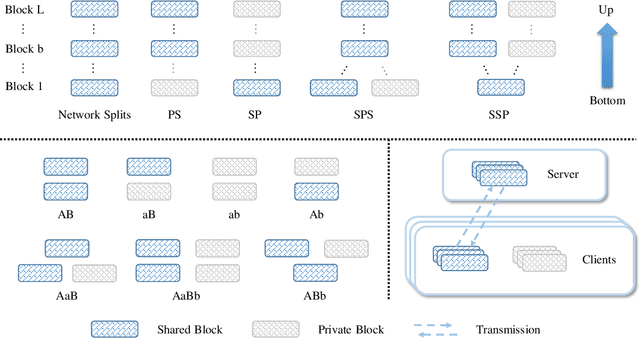

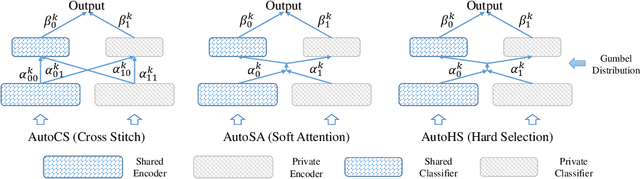
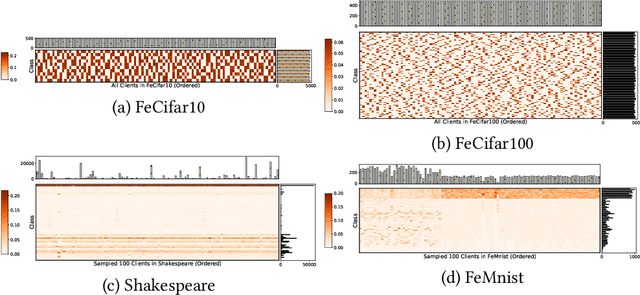
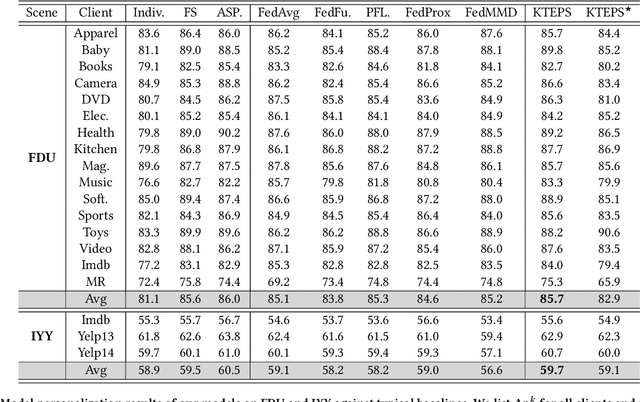
Although federated learning (FL) has recently been proposed for efficient distributed training and data privacy protection, it still encounters many obstacles. One of these is the naturally existing statistical heterogeneity among clients, making local data distributions non independently and identically distributed (i.e., non-iid), which poses challenges for model aggregation and personalization. For FL with a deep neural network (DNN), privatizing some layers is a simple yet effective solution for non-iid problems. However, which layers should we privatize to facilitate the learning process? Do different categories of non-iid scenes have preferred privatization ways? Can we automatically learn the most appropriate privatization way during FL? In this paper, we answer these questions via abundant experimental studies on several FL benchmarks. First, we present the detailed statistics of these benchmarks and categorize them into covariate and label shift non-iid scenes. Then, we investigate both coarse-grained and fine-grained network splits and explore whether the preferred privatization ways have any potential relations to the specific category of a non-iid scene. Our findings are exciting, e.g., privatizing the base layers could boost the performances even in label shift non-iid scenes, which are inconsistent with some natural conjectures. We also find that none of these privatization ways could improve the performances on the Shakespeare benchmark, and we guess that Shakespeare may not be a seriously non-iid scene. Finally, we propose several approaches to automatically learn where to aggregate via cross-stitch, soft attention, and hard selection. We advocate the proposed methods could serve as a preliminary try to explore where to privatize for a novel non-iid scene.
Exploring Uncertainty in Deep Learning for Construction of Prediction Intervals
Apr 27, 2021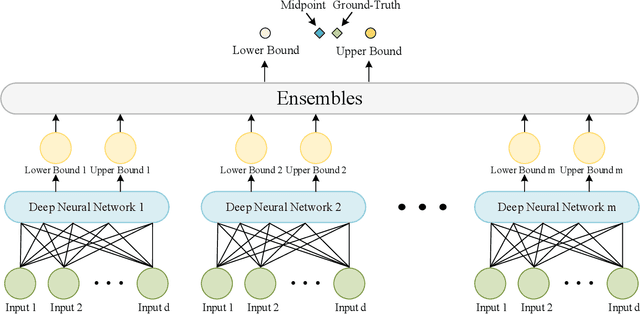
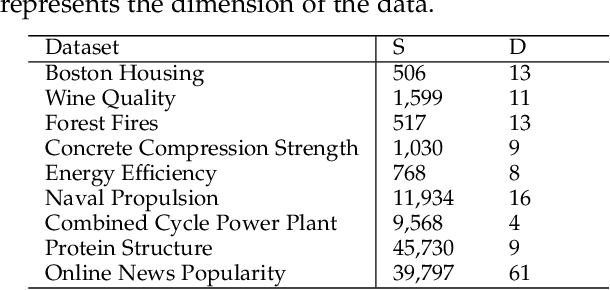
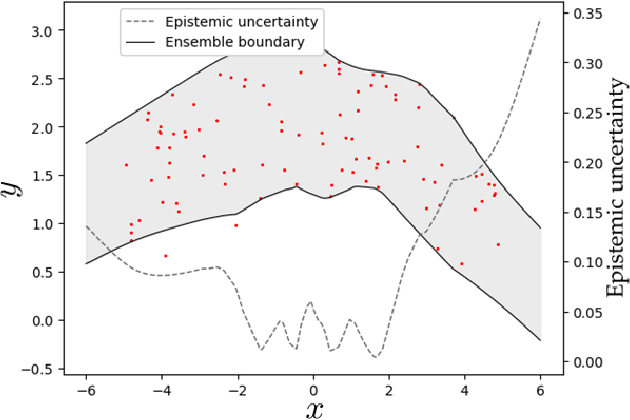
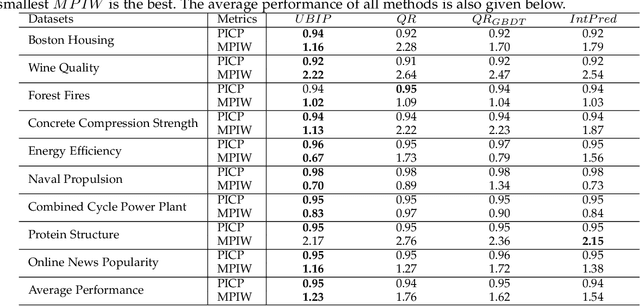
Deep learning has achieved impressive performance on many tasks in recent years. However, it has been found that it is still not enough for deep neural networks to provide only point estimates. For high-risk tasks, we need to assess the reliability of the model predictions. This requires us to quantify the uncertainty of model prediction and construct prediction intervals. In this paper, We explore the uncertainty in deep learning to construct the prediction intervals. In general, We comprehensively consider two categories of uncertainties: aleatory uncertainty and epistemic uncertainty. We design a special loss function, which enables us to learn uncertainty without uncertainty label. We only need to supervise the learning of regression task. We learn the aleatory uncertainty implicitly from the loss function. And that epistemic uncertainty is accounted for in ensembled form. Our method correlates the construction of prediction intervals with the uncertainty estimation. Impressive results on some publicly available datasets show that the performance of our method is competitive with other state-of-the-art methods.