 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePeng Cheng Object Detection Benchmark for Smart City
Mar 11, 2022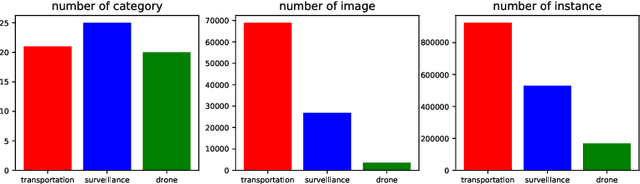
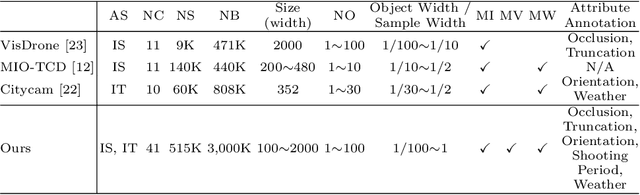
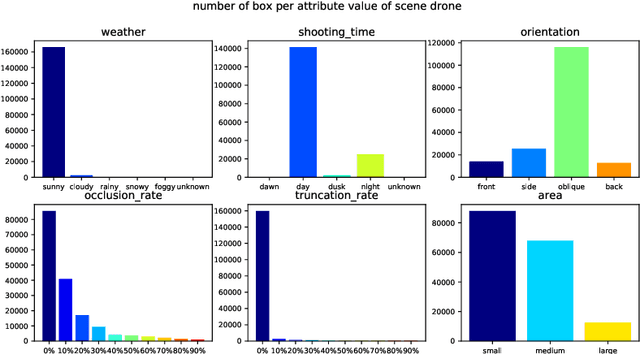

Object detection is an algorithm that recognizes and locates the objects in the image and has a wide range of applications in the visual understanding of complex urban scenes. Existing object detection benchmarks mainly focus on a single specific scenario and their annotation attributes are not rich enough, these make the object detection model is not generalized for the smart city scenes. Considering the diversity and complexity of scenes in intelligent city governance, we build a large-scale object detection benchmark for the smart city. Our benchmark contains about 500K images and includes three scenarios: intelligent transportation, intelligent security, and drones. For the complexity of the real scene in the smart city, the diversity of weather, occlusion, and other complex environment diversity attributes of the images in the three scenes are annotated. The characteristics of the benchmark are analyzed and extensive experiments of the current state-of-the-art target detection algorithm are conducted based on our benchmark to show their performance.
Anomaly Detection with Prototype-Guided Discriminative Latent Embeddings
Apr 30, 2021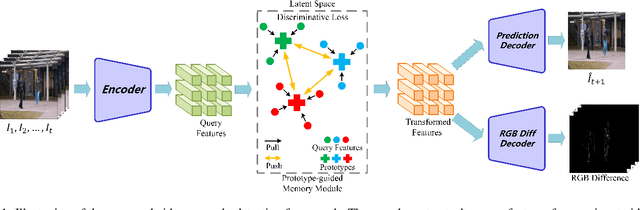
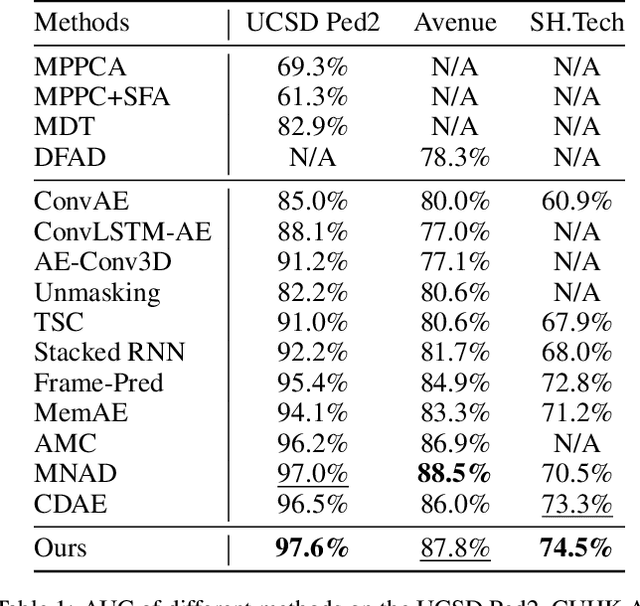
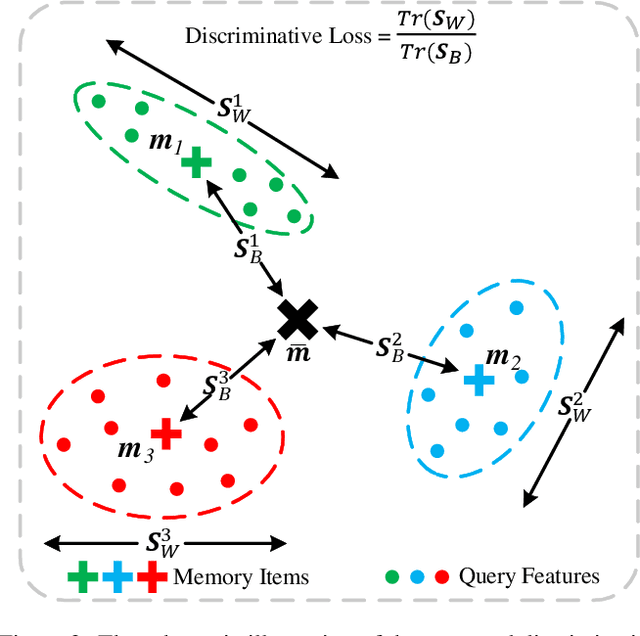
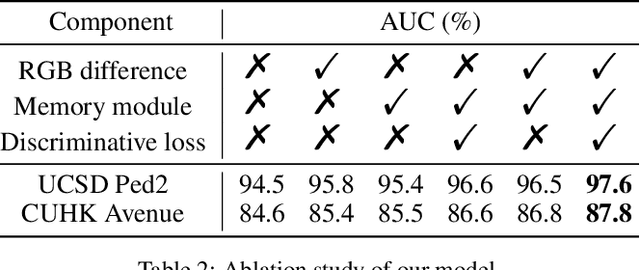
Recent efforts towards video anomaly detection try to learn a deep autoencoder to describe normal event patterns with small reconstruction errors. The video inputs with large reconstruction errors are regarded as anomalies at the test time. However, these methods sometimes reconstruct abnormal inputs well because of the powerful generalization ability of deep autoencoder. To address this problem, we present a novel approach for anomaly detection, which utilizes discriminative prototypes of normal data to reconstruct video frames. In this way, the model will favor the reconstruction of normal events and distort the reconstruction of abnormal events. Specifically, we use a prototype-guided memory module to perform discriminative latent embedding. We introduce a new discriminative criterion for the memory module, as well as a loss function correspondingly, which can encourage memory items to record the representative embeddings of normal data, i.e. prototypes. Besides, we design a novel two-branch autoencoder, which is composed of a future frame prediction network and an RGB difference generation network that share the same encoder. The stacked RGB difference contains motion information just like optical flow, so our model can learn temporal regularity. We evaluate the effectiveness of our method on three benchmark datasets and experimental results demonstrate the proposed method outperforms the state-of-the-art.
Exploring Uncertainty in Deep Learning for Construction of Prediction Intervals
Apr 27, 2021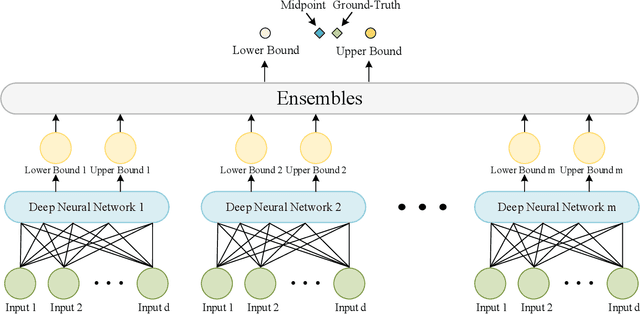
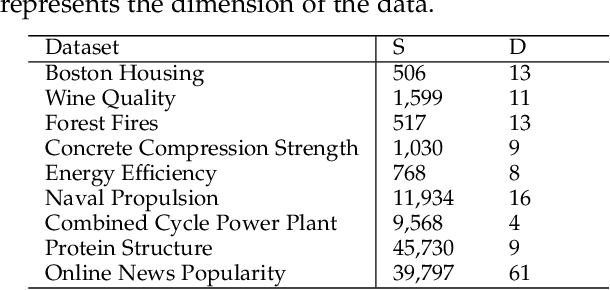
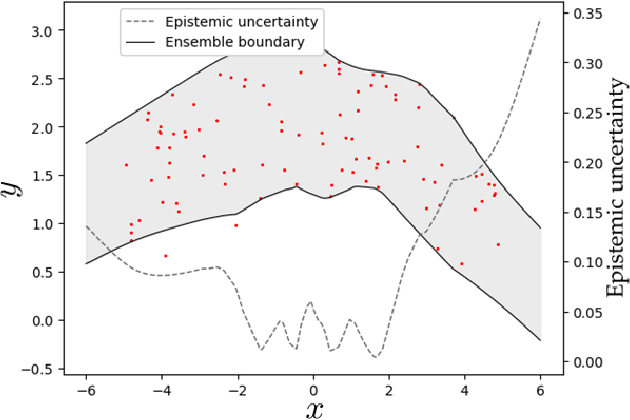
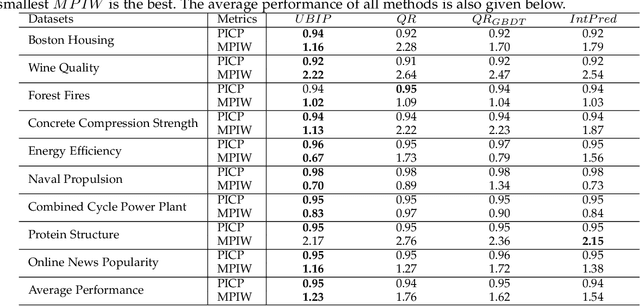
Deep learning has achieved impressive performance on many tasks in recent years. However, it has been found that it is still not enough for deep neural networks to provide only point estimates. For high-risk tasks, we need to assess the reliability of the model predictions. This requires us to quantify the uncertainty of model prediction and construct prediction intervals. In this paper, We explore the uncertainty in deep learning to construct the prediction intervals. In general, We comprehensively consider two categories of uncertainties: aleatory uncertainty and epistemic uncertainty. We design a special loss function, which enables us to learn uncertainty without uncertainty label. We only need to supervise the learning of regression task. We learn the aleatory uncertainty implicitly from the loss function. And that epistemic uncertainty is accounted for in ensembled form. Our method correlates the construction of prediction intervals with the uncertainty estimation. Impressive results on some publicly available datasets show that the performance of our method is competitive with other state-of-the-art methods.