 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInsights from Visual Cognition: Understanding Human Action Dynamics with Overall Glance and Refined Gaze Transformer
Apr 08, 2026Recently, Transformer has made significant progress in various vision tasks. To balance computation and efficiency in video tasks, recent works heavily rely on factorized or window-based self-attention. However, these approaches split spatiotemporal correlations between regions of interest in videos, limiting the models' ability to capture motion and long-range dependencies. In this paper, we argue that, similar to the human visual system, the importance of temporal and spatial information varies across different time scales, and attention is allocated sparsely over time through glance and gaze behavior. Is equal consideration of time and space crucial for success in video tasks? Motivated by this understanding, we propose a dual-path network called the Overall Glance and Refined Gaze (OG-ReG) Transformer. The Glance path extracts coarse-grained overall spatiotemporal information, while the Gaze path supplements the Glance path by providing local details. Our model achieves state-of-the-art results on the Kinetics-400, Something-Something v2, and Diving-48, demonstrating its competitive performance. The code will be available at https://github.com/linuxsino/OG-ReG.
Beyond Completion: Probing Cumulative State Tracking to Predict LLM Agent Performance
Mar 28, 2026Task-completion rate is the standard proxy for LLM agent capability, but models with identical completion scores can differ substantially in their ability to track intermediate state. We introduce Working Memory Fidelity-Active Manipulation (WMF-AM), a calibrated no-scratchpad probe of cumulative arithmetic state tracking, and evaluate it on 20 open-weight models (0.5B-35B, 13 families) against a released deterministic 10-task agent battery. In a pre-specified, Bonferroni-corrected analysis, WMF-AM predicts agent performance with Kendall's tau = 0.612 (p < 0.001, 95% CI [0.360, 0.814]); exploratory partial-tau analyses suggest this signal persists after controlling for completion score and model scale. Three construct-isolation ablations (K = 1 control, non-arithmetic ceiling, yoked cancellation) support the interpretation that cumulative state tracking under load, rather than single-step arithmetic or entity tracking alone, is the primary difficulty source. K-calibration keeps the probe in a discriminative range where prior fixed-depth benchmarks become non-discriminative; generalization beyond this open-weight sample remains open.
DEEMO: De-identity Multimodal Emotion Recognition and Reasoning
Apr 28, 2025Emotion understanding is a critical yet challenging task. Most existing approaches rely heavily on identity-sensitive information, such as facial expressions and speech, which raises concerns about personal privacy. To address this, we introduce the De-identity Multimodal Emotion Recognition and Reasoning (DEEMO), a novel task designed to enable emotion understanding using de-identified video and audio inputs. The DEEMO dataset consists of two subsets: DEEMO-NFBL, which includes rich annotations of Non-Facial Body Language (NFBL), and DEEMO-MER, an instruction dataset for Multimodal Emotion Recognition and Reasoning using identity-free cues. This design supports emotion understanding without compromising identity privacy. In addition, we propose DEEMO-LLaMA, a Multimodal Large Language Model (MLLM) that integrates de-identified audio, video, and textual information to enhance both emotion recognition and reasoning. Extensive experiments show that DEEMO-LLaMA achieves state-of-the-art performance on both tasks, outperforming existing MLLMs by a significant margin, achieving 74.49% accuracy and 74.45% F1-score in de-identity emotion recognition, and 6.20 clue overlap and 7.66 label overlap in de-identity emotion reasoning. Our work contributes to ethical AI by advancing privacy-preserving emotion understanding and promoting responsible affective computing.
Enhancing Micro Gesture Recognition for Emotion Understanding via Context-aware Visual-Text Contrastive Learning
May 03, 2024Psychological studies have shown that Micro Gestures (MG) are closely linked to human emotions. MG-based emotion understanding has attracted much attention because it allows for emotion understanding through nonverbal body gestures without relying on identity information (e.g., facial and electrocardiogram data). Therefore, it is essential to recognize MG effectively for advanced emotion understanding. However, existing Micro Gesture Recognition (MGR) methods utilize only a single modality (e.g., RGB or skeleton) while overlooking crucial textual information. In this letter, we propose a simple but effective visual-text contrastive learning solution that utilizes text information for MGR. In addition, instead of using handcrafted prompts for visual-text contrastive learning, we propose a novel module called Adaptive prompting to generate context-aware prompts. The experimental results show that the proposed method achieves state-of-the-art performance on two public datasets. Furthermore, based on an empirical study utilizing the results of MGR for emotion understanding, we demonstrate that using the textual results of MGR significantly improves performance by 6%+ compared to directly using video as input.
* accepted by IEEE Signal Processing Letters
EALD-MLLM: Emotion Analysis in Long-sequential and De-identity videos with Multi-modal Large Language Model
May 01, 2024Emotion AI is the ability of computers to understand human emotional states. Existing works have achieved promising progress, but two limitations remain to be solved: 1) Previous studies have been more focused on short sequential video emotion analysis while overlooking long sequential video. However, the emotions in short sequential videos only reflect instantaneous emotions, which may be deliberately guided or hidden. In contrast, long sequential videos can reveal authentic emotions; 2) Previous studies commonly utilize various signals such as facial, speech, and even sensitive biological signals (e.g., electrocardiogram). However, due to the increasing demand for privacy, developing Emotion AI without relying on sensitive signals is becoming important. To address the aforementioned limitations, in this paper, we construct a dataset for Emotion Analysis in Long-sequential and De-identity videos called EALD by collecting and processing the sequences of athletes' post-match interviews. In addition to providing annotations of the overall emotional state of each video, we also provide the Non-Facial Body Language (NFBL) annotations for each player. NFBL is an inner-driven emotional expression and can serve as an identity-free clue to understanding the emotional state. Moreover, we provide a simple but effective baseline for further research. More precisely, we evaluate the Multimodal Large Language Models (MLLMs) with de-identification signals (e.g., visual, speech, and NFBLs) to perform emotion analysis. Our experimental results demonstrate that: 1) MLLMs can achieve comparable, even better performance than the supervised single-modal models, even in a zero-shot scenario; 2) NFBL is an important cue in long sequential emotion analysis. EALD will be available on the open-source platform.
Prompt-Driven Dynamic Object-Centric Learning for Single Domain Generalization
Feb 28, 2024Single-domain generalization aims to learn a model from single source domain data to achieve generalized performance on other unseen target domains. Existing works primarily focus on improving the generalization ability of static networks. However, static networks are unable to dynamically adapt to the diverse variations in different image scenes, leading to limited generalization capability. Different scenes exhibit varying levels of complexity, and the complexity of images further varies significantly in cross-domain scenarios. In this paper, we propose a dynamic object-centric perception network based on prompt learning, aiming to adapt to the variations in image complexity. Specifically, we propose an object-centric gating module based on prompt learning to focus attention on the object-centric features guided by the various scene prompts. Then, with the object-centric gating masks, the dynamic selective module dynamically selects highly correlated feature regions in both spatial and channel dimensions enabling the model to adaptively perceive object-centric relevant features, thereby enhancing the generalization capability. Extensive experiments were conducted on single-domain generalization tasks in image classification and object detection. The experimental results demonstrate that our approach outperforms state-of-the-art methods, which validates the effectiveness and generally of our proposed method.
Prototype-guided Cross-task Knowledge Distillation for Large-scale Models
Dec 26, 2022



Recently, large-scale pre-trained models have shown their advantages in many tasks. However, due to the huge computational complexity and storage requirements, it is challenging to apply the large-scale model to real scenes. A common solution is knowledge distillation which regards the large-scale model as a teacher model and helps to train a small student model to obtain a competitive performance. Cross-task Knowledge distillation expands the application scenarios of the large-scale pre-trained model. Existing knowledge distillation works focus on directly mimicking the final prediction or the intermediate layers of the teacher model, which represent the global-level characteristics and are task-specific. To alleviate the constraint of different label spaces, capturing invariant intrinsic local object characteristics (such as the shape characteristics of the leg and tail of the cattle and horse) plays a key role. Considering the complexity and variability of real scene tasks, we propose a Prototype-guided Cross-task Knowledge Distillation (ProC-KD) approach to transfer the intrinsic local-level object knowledge of a large-scale teacher network to various task scenarios. First, to better transfer the generalized knowledge in the teacher model in cross-task scenarios, we propose a prototype learning module to learn from the essential feature representation of objects in the teacher model. Secondly, for diverse downstream tasks, we propose a task-adaptive feature augmentation module to enhance the features of the student model with the learned generalization prototype features and guide the training of the student model to improve its generalization ability. The experimental results on various visual tasks demonstrate the effectiveness of our approach for large-scale model cross-task knowledge distillation scenes.
Peng Cheng Object Detection Benchmark for Smart City
Mar 11, 2022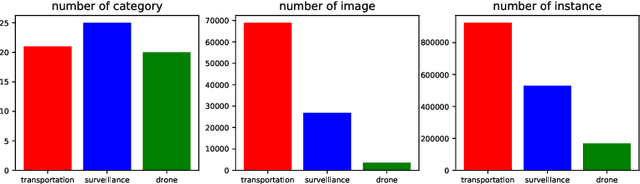
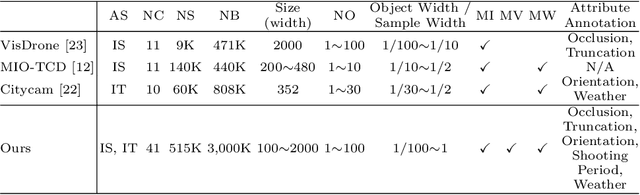
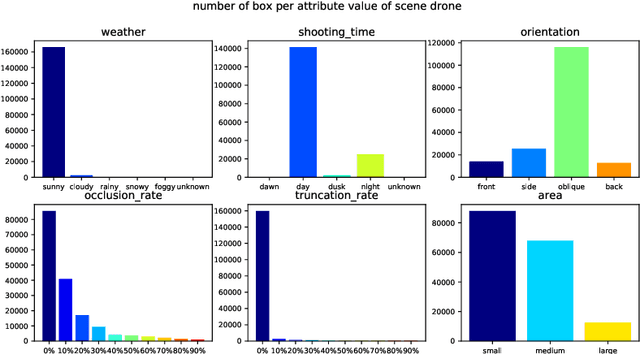

Object detection is an algorithm that recognizes and locates the objects in the image and has a wide range of applications in the visual understanding of complex urban scenes. Existing object detection benchmarks mainly focus on a single specific scenario and their annotation attributes are not rich enough, these make the object detection model is not generalized for the smart city scenes. Considering the diversity and complexity of scenes in intelligent city governance, we build a large-scale object detection benchmark for the smart city. Our benchmark contains about 500K images and includes three scenarios: intelligent transportation, intelligent security, and drones. For the complexity of the real scene in the smart city, the diversity of weather, occlusion, and other complex environment diversity attributes of the images in the three scenes are annotated. The characteristics of the benchmark are analyzed and extensive experiments of the current state-of-the-art target detection algorithm are conducted based on our benchmark to show their performance.
LineCounter: Learning Handwritten Text Line Segmentation by Counting
May 24, 2021

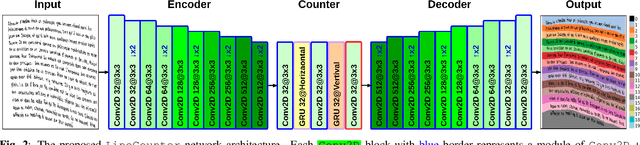
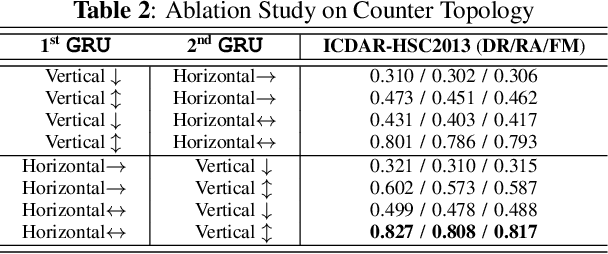
Handwritten Text Line Segmentation (HTLS) is a low-level but important task for many higher-level document processing tasks like handwritten text recognition. It is often formulated in terms of semantic segmentation or object detection in deep learning. However, both formulations have serious shortcomings. The former requires heavy post-processing of splitting/merging adjacent segments, while the latter may fail on dense or curved texts. In this paper, we propose a novel Line Counting formulation for HTLS -- that involves counting the number of text lines from the top at every pixel location. This formulation helps learn an end-to-end HTLS solution that directly predicts per-pixel line number for a given document image. Furthermore, we propose a deep neural network (DNN) model LineCounter to perform HTLS through the Line Counting formulation. Our extensive experiments on the three public datasets (ICDAR2013-HSC, HIT-MW, and VML-AHTE) demonstrate that LineCounter outperforms state-of-the-art HTLS approaches. Source code is available at https://github.com/Leedeng/Line-Counter.
SauvolaNet: Learning Adaptive Sauvola Network for Degraded Document Binarization
May 12, 2021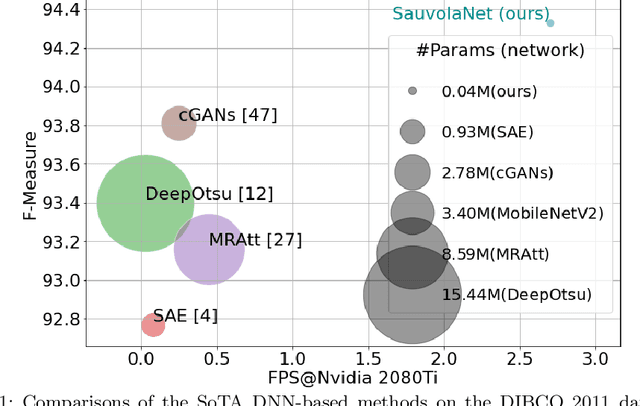


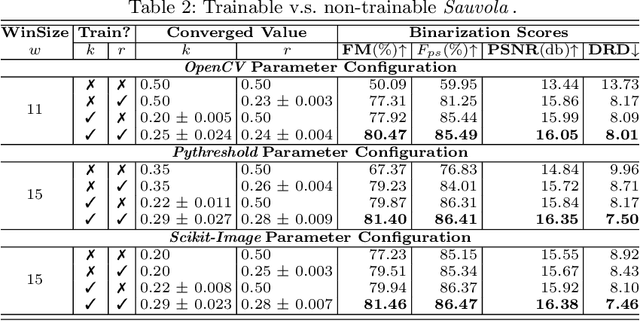
Inspired by the classic Sauvola local image thresholding approach, we systematically study it from the deep neural network (DNN) perspective and propose a new solution called SauvolaNet for degraded document binarization (DDB). It is composed of three explainable modules, namely, Multi-Window Sauvola (MWS), Pixelwise Window Attention (PWA), and Adaptive Sauolva Threshold (AST). The MWS module honestly reflects the classic Sauvola but with trainable parameters and multi-window settings. The PWA module estimates the preferred window sizes for each pixel location. The AST module further consolidates the outputs from MWS and PWA and predicts the final adaptive threshold for each pixel location. As a result, SauvolaNet becomes end-to-end trainable and significantly reduces the number of required network parameters to 40K -- it is only 1\% of MobileNetV2. In the meantime, it achieves the State-of-The-Art (SoTA) performance for the DDB task -- SauvolaNet is at least comparable to, if not better than, SoTA binarization solutions in our extensive studies on the 13 public document binarization datasets. Our source code is available at https://github.com/Leedeng/SauvolaNet.