 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFat-Cat: Document-Driven Metacognitive Multi-Agent System for Complex Reasoning
Feb 02, 2026The effectiveness of LLM-based agents is often limited not by model capacity alone, but by how efficiently contextual information is utilized at runtime. Existing agent frameworks rely on rigid, syntax-heavy state representations such as nested JSON, which require models to devote a substantial portion of their limited attention to syntactic processing rather than semantic reasoning. In this paper, we propose Fat-Cat, a document-driven agent architecture that improves the signal-to-noise ratio of state management. By integrating three key components: (1) a Semantic File System that represents agent state as Markdown documents aligned with common pre-training corpora, (2) a Textual Strategy Evolution module that accumulates task-solving knowledge without parameter updates, and (3) a Closed-Loop Watcher that monitors reasoning trajectories to reduce hallucinations. Extensive reasoning, retrieval, and coding benchmarks, Fat-Cat consistently improves agent performance. It enables the Kimi-k2 model to outperform the proprietary GPT-4o baseline on HotPotQA. Replacing the document-based state with JSON leads to performance drop, while empirically validating the critical necessity of document-driven state modeling over rigid syntax. The code is available at https://github.com/answeryt/Fat-Cat.
Towards Open Environments and Instructions: General Vision-Language Navigation via Fast-Slow Interactive Reasoning
Jan 14, 2026Vision-Language Navigation aims to enable agents to navigate to a target location based on language instructions. Traditional VLN often follows a close-set assumption, i.e., training and test data share the same style of the input images and instructions. However, the real world is open and filled with various unseen environments, posing enormous difficulties for close-set methods. To this end, we focus on the General Scene Adaptation (GSA-VLN) task, aiming to learn generalized navigation ability by introducing diverse environments and inconsistent intructions.Towards this task, when facing unseen environments and instructions, the challenge mainly lies in how to enable the agent to dynamically produce generalized strategies during the navigation process. Recent research indicates that by means of fast and slow cognition systems, human beings could generate stable policies, which strengthen their adaptation for open world. Inspired by this idea, we propose the slow4fast-VLN, establishing a dynamic interactive fast-slow reasoning framework. The fast-reasoning module, an end-to-end strategy network, outputs actions via real-time input. It accumulates execution records in a history repository to build memory. The slow-reasoning module analyze the memories generated by the fast-reasoning module. Through deep reflection, it extracts experiences that enhance the generalization ability of decision-making. These experiences are structurally stored and used to continuously optimize the fast-reasoning module. Unlike traditional methods that treat fast-slow reasoning as independent mechanisms, our framework enables fast-slow interaction. By leveraging the experiences from slow reasoning. This interaction allows the system to continuously adapt and efficiently execute navigation tasks when facing unseen scenarios.
How Order-Sensitive Are LLMs? OrderProbe for Deterministic Structural Reconstruction
Jan 13, 2026Large language models (LLMs) excel at semantic understanding, yet their ability to reconstruct internal structure from scrambled inputs remains underexplored. Sentence-level restoration is ill-posed for automated evaluation because multiple valid word orders often exist. We introduce OrderProbe, a deterministic benchmark for structural reconstruction using fixed four-character expressions in Chinese, Japanese, and Korean, which have a unique canonical order and thus support exact-match scoring. We further propose a diagnostic framework that evaluates models beyond recovery accuracy, including semantic fidelity, logical validity, consistency, robustness sensitivity, and information density. Experiments on twelve widely used LLMs show that structural reconstruction remains difficult even for frontier systems: zero-shot recovery frequently falls below 35%. We also observe a consistent dissociation between semantic recall and structural planning, suggesting that structural robustness is not an automatic byproduct of semantic competence.
Simulating Distribution Dynamics: Liquid Temporal Feature Evolution for Single-Domain Generalized Object Detection
Nov 13, 2025In this paper, we focus on Single-Domain Generalized Object Detection (Single-DGOD), aiming to transfer a detector trained on one source domain to multiple unknown domains. Existing methods for Single-DGOD typically rely on discrete data augmentation or static perturbation methods to expand data diversity, thereby mitigating the lack of access to target domain data. However, in real-world scenarios such as changes in weather or lighting conditions, domain shifts often occur continuously and gradually. Discrete augmentations and static perturbations fail to effectively capture the dynamic variation of feature distributions, thereby limiting the model's ability to perceive fine-grained cross-domain differences. To this end, we propose a new method, Liquid Temporal Feature Evolution, which simulates the progressive evolution of features from the source domain to simulated latent distributions by incorporating temporal modeling and liquid neural network-driven parameter adjustment. Specifically, we introduce controllable Gaussian noise injection and multi-scale Gaussian blurring to simulate initial feature perturbations, followed by temporal modeling and a liquid parameter adjustment mechanism to generate adaptive modulation parameters, enabling a smooth and continuous adaptation across domains. By capturing progressive cross-domain feature evolution and dynamically regulating adaptation paths, our method bridges the source-unknown domain distribution gap, significantly boosting generalization and robustness to unseen shifts. Significant performance improvements on the Diverse Weather dataset and Real-to-Art benchmark demonstrate the superiority of our method. Our code is available at https://github.com/2490o/LTFE.
Mamba-driven multi-perspective structural understanding for molecular ground-state conformation prediction
Nov 10, 2025A comprehensive understanding of molecular structures is important for the prediction of molecular ground-state conformation involving property information. Meanwhile, state space model (e.g., Mamba) has recently emerged as a promising mechanism for long sequence modeling and has achieved remarkable results in various language and vision tasks. However, towards molecular ground-state conformation prediction, exploiting Mamba to understand molecular structure is underexplored. To this end, we strive to design a generic and efficient framework with Mamba to capture critical components. In general, molecular structure could be considered to consist of three elements, i.e., atom types, atom positions, and connections between atoms. Thus, considering the three elements, an approach of Mamba-driven multi-perspective structural understanding (MPSU-Mamba) is proposed to localize molecular ground-state conformation. Particularly, for complex and diverse molecules, three different kinds of dedicated scanning strategies are explored to construct a comprehensive perception of corresponding molecular structures. And a bright-channel guided mechanism is defined to discriminate the critical conformation-related atom information. Experimental results on QM9 and Molecule3D datasets indicate that MPSU-Mamba significantly outperforms existing methods. Furthermore, we observe that for the case of few training samples, MPSU-Mamba still achieves superior performance, demonstrating that our method is indeed beneficial for understanding molecular structures.
Style Evolving along Chain-of-Thought for Unknown-Domain Object Detection
Mar 13, 2025Recently, a task of Single-Domain Generalized Object Detection (Single-DGOD) is proposed, aiming to generalize a detector to multiple unknown domains never seen before during training. Due to the unavailability of target-domain data, some methods leverage the multimodal capabilities of vision-language models, using textual prompts to estimate cross-domain information, enhancing the model's generalization capability. These methods typically use a single textual prompt, often referred to as the one-step prompt method. However, when dealing with complex styles such as the combination of rain and night, we observe that the performance of the one-step prompt method tends to be relatively weak. The reason may be that many scenes incorporate not just a single style but a combination of multiple styles. The one-step prompt method may not effectively synthesize combined information involving various styles. To address this limitation, we propose a new method, i.e., Style Evolving along Chain-of-Thought, which aims to progressively integrate and expand style information along the chain of thought, enabling the continual evolution of styles. Specifically, by progressively refining style descriptions and guiding the diverse evolution of styles, this approach enables more accurate simulation of various style characteristics and helps the model gradually learn and adapt to subtle differences between styles. Additionally, it exposes the model to a broader range of style features with different data distributions, thereby enhancing its generalization capability in unseen domains. The significant performance gains over five adverse-weather scenarios and the Real to Art benchmark demonstrate the superiorities of our method.
Prompt-Driven Dynamic Object-Centric Learning for Single Domain Generalization
Feb 28, 2024Single-domain generalization aims to learn a model from single source domain data to achieve generalized performance on other unseen target domains. Existing works primarily focus on improving the generalization ability of static networks. However, static networks are unable to dynamically adapt to the diverse variations in different image scenes, leading to limited generalization capability. Different scenes exhibit varying levels of complexity, and the complexity of images further varies significantly in cross-domain scenarios. In this paper, we propose a dynamic object-centric perception network based on prompt learning, aiming to adapt to the variations in image complexity. Specifically, we propose an object-centric gating module based on prompt learning to focus attention on the object-centric features guided by the various scene prompts. Then, with the object-centric gating masks, the dynamic selective module dynamically selects highly correlated feature regions in both spatial and channel dimensions enabling the model to adaptively perceive object-centric relevant features, thereby enhancing the generalization capability. Extensive experiments were conducted on single-domain generalization tasks in image classification and object detection. The experimental results demonstrate that our approach outperforms state-of-the-art methods, which validates the effectiveness and generally of our proposed method.
Environment-Invariant Curriculum Relation Learning for Fine-Grained Scene Graph Generation
Aug 21, 2023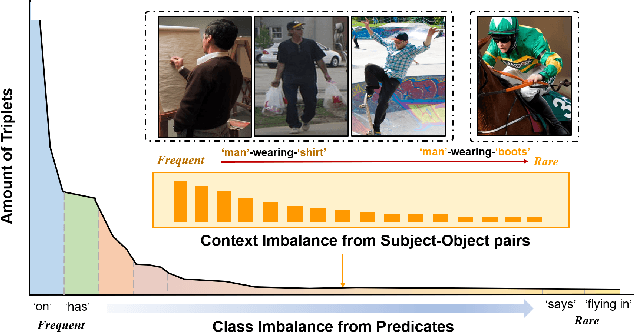
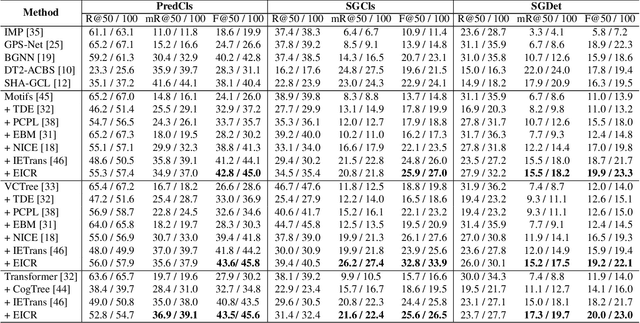
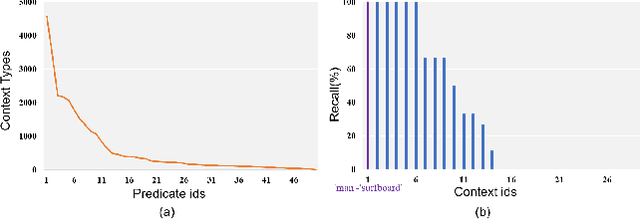

The scene graph generation (SGG) task is designed to identify the predicates based on the subject-object pairs.However,existing datasets generally include two imbalance cases: one is the class imbalance from the predicted predicates and another is the context imbalance from the given subject-object pairs, which presents significant challenges for SGG. Most existing methods focus on the imbalance of the predicted predicate while ignoring the imbalance of the subject-object pairs, which could not achieve satisfactory results. To address the two imbalance cases, we propose a novel Environment Invariant Curriculum Relation learning (EICR) method, which can be applied in a plug-and-play fashion to existing SGG methods. Concretely, to remove the imbalance of the subject-object pairs, we first construct different distribution environments for the subject-object pairs and learn a model invariant to the environment changes. Then, we construct a class-balanced curriculum learning strategy to balance the different environments to remove the predicate imbalance. Comprehensive experiments conducted on VG and GQA datasets demonstrate that our EICR framework can be taken as a general strategy for various SGG models, and achieve significant improvements.
Prototype-guided Cross-task Knowledge Distillation for Large-scale Models
Dec 26, 2022



Recently, large-scale pre-trained models have shown their advantages in many tasks. However, due to the huge computational complexity and storage requirements, it is challenging to apply the large-scale model to real scenes. A common solution is knowledge distillation which regards the large-scale model as a teacher model and helps to train a small student model to obtain a competitive performance. Cross-task Knowledge distillation expands the application scenarios of the large-scale pre-trained model. Existing knowledge distillation works focus on directly mimicking the final prediction or the intermediate layers of the teacher model, which represent the global-level characteristics and are task-specific. To alleviate the constraint of different label spaces, capturing invariant intrinsic local object characteristics (such as the shape characteristics of the leg and tail of the cattle and horse) plays a key role. Considering the complexity and variability of real scene tasks, we propose a Prototype-guided Cross-task Knowledge Distillation (ProC-KD) approach to transfer the intrinsic local-level object knowledge of a large-scale teacher network to various task scenarios. First, to better transfer the generalized knowledge in the teacher model in cross-task scenarios, we propose a prototype learning module to learn from the essential feature representation of objects in the teacher model. Secondly, for diverse downstream tasks, we propose a task-adaptive feature augmentation module to enhance the features of the student model with the learned generalization prototype features and guide the training of the student model to improve its generalization ability. The experimental results on various visual tasks demonstrate the effectiveness of our approach for large-scale model cross-task knowledge distillation scenes.
Vector-Decomposed Disentanglement for Domain-Invariant Object Detection
Aug 15, 2021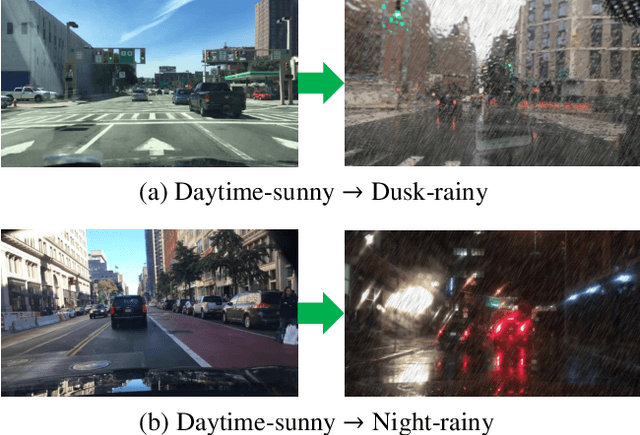
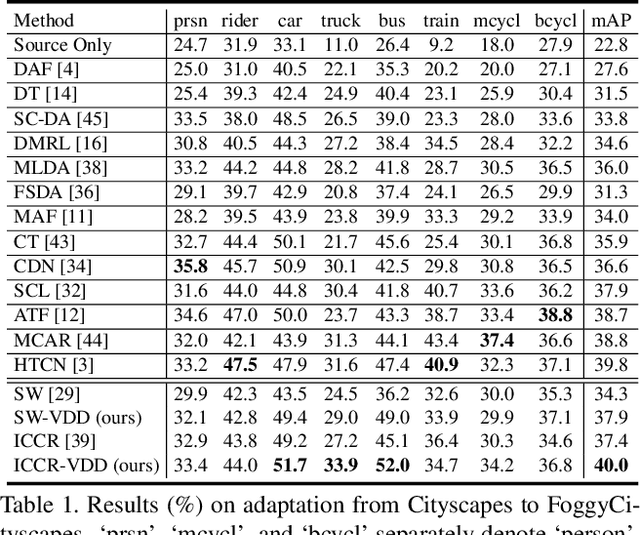
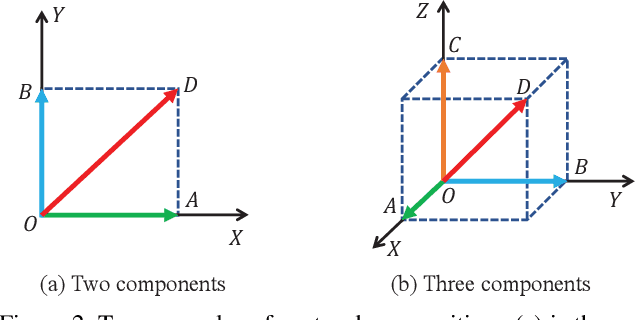
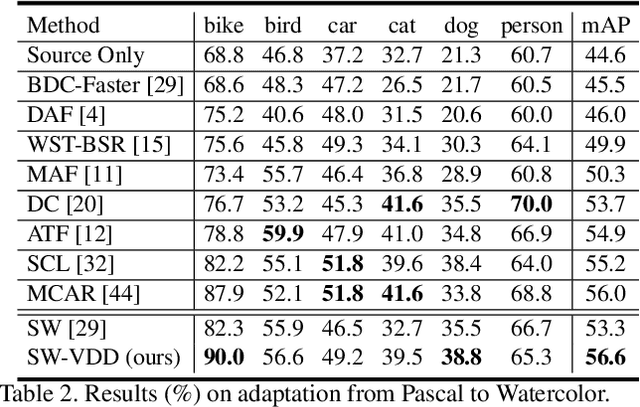
To improve the generalization of detectors, for domain adaptive object detection (DAOD), recent advances mainly explore aligning feature-level distributions between the source and single-target domain, which may neglect the impact of domain-specific information existing in the aligned features. Towards DAOD, it is important to extract domain-invariant object representations. To this end, in this paper, we try to disentangle domain-invariant representations from domain-specific representations. And we propose a novel disentangled method based on vector decomposition. Firstly, an extractor is devised to separate domain-invariant representations from the input, which are used for extracting object proposals. Secondly, domain-specific representations are introduced as the differences between the input and domain-invariant representations. Through the difference operation, the gap between the domain-specific and domain-invariant representations is enlarged, which promotes domain-invariant representations to contain more domain-irrelevant information. In the experiment, we separately evaluate our method on the single- and compound-target case. For the single-target case, experimental results of four domain-shift scenes show our method obtains a significant performance gain over baseline methods. Moreover, for the compound-target case (i.e., the target is a compound of two different domains without domain labels), our method outperforms baseline methods by around 4%, which demonstrates the effectiveness of our method.