 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTouchTTS: An Embarrassingly Simple TTS Framework that Everyone Can Touch
Dec 12, 2024It is well known that LLM-based systems are data-hungry. Recent LLM-based TTS works typically employ complex data processing pipelines to obtain high-quality training data. These sophisticated pipelines require excellent models at each stage (e.g., speech denoising, speech enhancement, speaker diarization, and punctuation models), which themselves demand high-quality training data and are rarely open-sourced. Even with state-of-the-art models, issues persist, such as incomplete background noise removal and misalignment between punctuation and actual speech pauses. Moreover, the stringent filtering strategies often retain only 10-30\% of the original data, significantly impeding data scaling efforts. In this work, we leverage a noise-robust audio tokenizer (S3Tokenizer) to design a simplified yet effective TTS data processing pipeline that maintains data quality while substantially reducing data acquisition costs, achieving a data retention rate of over 50\%. Beyond data scaling challenges, LLM-based TTS systems also incur higher deployment costs compared to conventional approaches. Current systems typically use LLMs solely for text-to-token generation, while requiring separate models (e.g., flow matching models) for token-to-waveform generation, which cannot be directly executed by LLM inference engines, further complicating deployment. To address these challenges, we eliminate redundant modules in both LLM and flow components, replacing the flow model backbone with an LLM architecture. Building upon this simplified flow backbone, we propose a unified architecture for both streaming and non-streaming inference, significantly reducing deployment costs. Finally, we explore the feasibility of unifying TTS and ASR tasks using the same data for training, thanks to the simplified pipeline and the S3Tokenizer that reduces the quality requirements for TTS training data.
S-DCCRN: Super Wide Band DCCRN with learnable complex feature for speech enhancement
Nov 16, 2021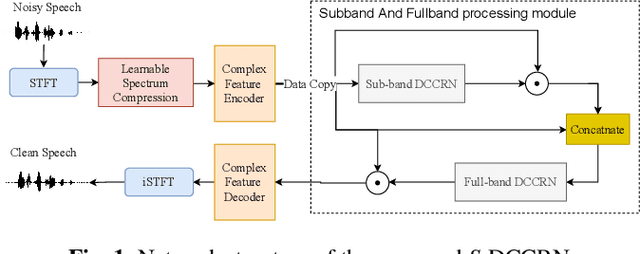
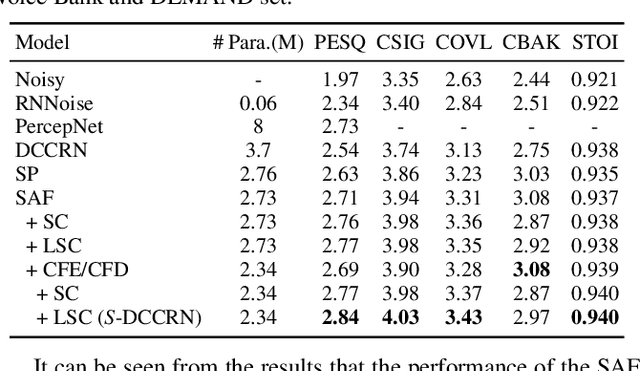
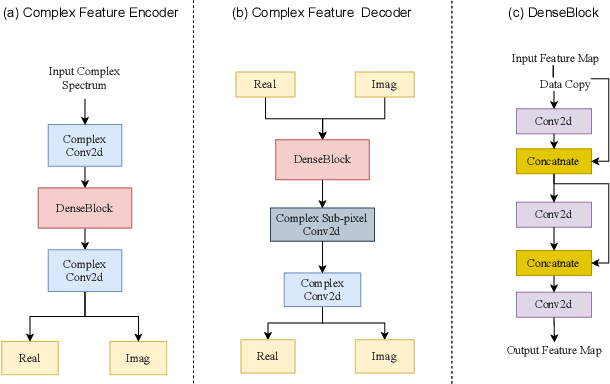
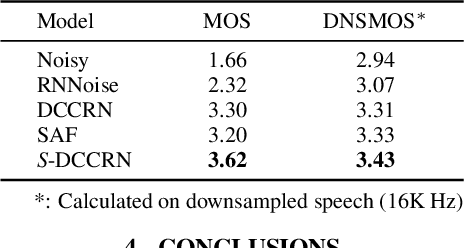
In speech enhancement, complex neural network has shown promising performance due to their effectiveness in processing complex-valued spectrum. Most of the recent speech enhancement approaches mainly focus on wide-band signal with a sampling rate of 16K Hz. However, research on super wide band (e.g., 32K Hz) or even full-band (48K) denoising is still lacked due to the difficulty of modeling more frequency bands and particularly high frequency components. In this paper, we extend our previous deep complex convolution recurrent neural network (DCCRN) substantially to a super wide band version -- S-DCCRN, to perform speech denoising on speech of 32K Hz sampling rate. We first employ a cascaded sub-band and full-band processing module, which consists of two small-footprint DCCRNs -- one operates on sub-band signal and one operates on full-band signal, aiming at benefiting from both local and global frequency information. Moreover, instead of simply adopting the STFT feature as input, we use a complex feature encoder trained in an end-to-end manner to refine the information of different frequency bands. We also use a complex feature decoder to revert the feature to time-frequency domain. Finally, a learnable spectrum compression method is adopted to adjust the energy of different frequency bands, which is beneficial for neural network learning. The proposed model, S-DCCRN, has surpassed PercepNet as well as several competitive models and achieves state-of-the-art performance in terms of speech quality and intelligibility. Ablation studies also demonstrate the effectiveness of different contributions.