 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient conformer-based speech recognition with linear attention
Paper and Code
Apr 14, 2021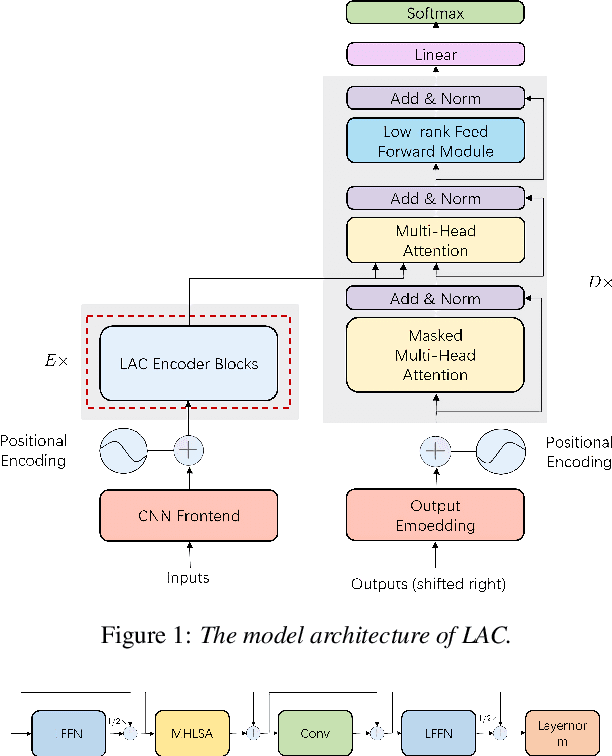


Recently, conformer-based end-to-end automatic speech recognition, which outperforms recurrent neural network based ones, has received much attention. Although the parallel computing of conformer is more efficient than recurrent neural networks, the computational complexity of its dot-product self-attention is quadratic with respect to the length of the input feature. To reduce the computational complexity of the self-attention layer, we propose multi-head linear self-attention for the self-attention layer, which reduces its computational complexity to linear order. In addition, we propose to factorize the feed forward module of the conformer by low-rank matrix factorization, which successfully reduces the number of the parameters by approximate 50% with little performance loss. The proposed model, named linear attention based conformer (LAC), can be trained and inferenced jointly with the connectionist temporal classification objective, which further improves the performance of LAC. To evaluate the effectiveness of LAC, we conduct experiments on the AISHELL-1 and LibriSpeech corpora. Results show that the proposed LAC achieves better performance than 7 recently proposed speech recognition models, and is competitive with the state-of-the-art conformer. Meanwhile, the proposed LAC has a number of parameters of only 50% over the conformer with faster training speed than the latter.