 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLEMAS: Large A 150K-Hour Large-scale Extensible Multilingual Audio Suite with Generative Speech Models
Jan 04, 2026We present the LEMAS-Dataset, which, to our knowledge, is currently the largest open-source multilingual speech corpus with word-level timestamps. Covering over 150,000 hours across 10 major languages, LEMAS-Dataset is constructed via a efficient data processing pipeline that ensures high-quality data and annotations. To validate the effectiveness of LEMAS-Dataset across diverse generative paradigms, we train two benchmark models with distinct architectures and task specializations on this dataset. LEMAS-TTS, built upon a non-autoregressive flow-matching framework, leverages the dataset's massive scale and linguistic diversity to achieve robust zero-shot multilingual synthesis. Our proposed accent-adversarial training and CTC loss mitigate cross-lingual accent issues, enhancing synthesis stability. Complementarily, LEMAS-Edit employs an autoregressive decoder-only architecture that formulates speech editing as a masked token infilling task. By exploiting precise word-level alignments to construct training masks and adopting adaptive decoding strategies, it achieves seamless, smooth-boundary speech editing with natural transitions. Experimental results demonstrate that models trained on LEMAS-Dataset deliver high-quality synthesis and editing performance, confirming the dataset's quality. We envision that this richly timestamp-annotated, fine-grained multilingual corpus will drive future advances in prompt-based speech generation systems.
Integrating Plug-and-Play Data Priors with Weighted Prediction Error for Speech Dereverberation
Dec 05, 2023



Speech dereverberation aims to alleviate the detrimental effects of late-reverberant components. While the weighted prediction error (WPE) method has shown superior performance in dereverberation, there is still room for further improvement in terms of performance and robustness in complex and noisy environments. Recent research has highlighted the effectiveness of integrating physics-based and data-driven methods, enhancing the performance of various signal processing tasks while maintaining interpretability. Motivated by these advancements, this paper presents a novel dereverberation frame-work, which incorporates data-driven methods for capturing speech priors within the WPE framework. The plug-and-play strategy (PnP), specifically the regularization by denoising (RED) strategy, is utilized to incorporate speech prior information learnt from data during the optimization problem solving iterations. Experimental results validate the effectiveness of the proposed approach.
AcademicGPT: Empowering Academic Research
Nov 21, 2023



Large Language Models (LLMs) have demonstrated exceptional capabilities across various natural language processing tasks. Yet, many of these advanced LLMs are tailored for broad, general-purpose applications. In this technical report, we introduce AcademicGPT, designed specifically to empower academic research. AcademicGPT is a continual training model derived from LLaMA2-70B. Our training corpus mainly consists of academic papers, thesis, content from some academic domain, high-quality Chinese data and others. While it may not be extensive in data scale, AcademicGPT marks our initial venture into a domain-specific GPT tailored for research area. We evaluate AcademicGPT on several established public benchmarks such as MMLU and CEval, as well as on some specialized academic benchmarks like PubMedQA, SCIEval, and our newly-created ComputerScienceQA, to demonstrate its ability from general knowledge ability, to Chinese ability, and to academic ability. Building upon AcademicGPT's foundation model, we also developed several applications catered to the academic area, including General Academic Question Answering, AI-assisted Paper Reading, Paper Review, and AI-assisted Title and Abstract Generation.
CT-based Subchondral Bone Microstructural Analysis in Knee Osteoarthritis via MR-Guided Distillation Learning
Jul 11, 2023



Background: MR-based subchondral bone effectively predicts knee osteoarthritis. However, its clinical application is limited by the cost and time of MR. Purpose: We aim to develop a novel distillation-learning-based method named SRRD for subchondral bone microstructural analysis using easily-acquired CT images, which leverages paired MR images to enhance the CT-based analysis model during training. Materials and Methods: Knee joint images of both CT and MR modalities were collected from October 2020 to May 2021. Firstly, we developed a GAN-based generative model to transform MR images into CT images, which was used to establish the anatomical correspondence between the two modalities. Next, we obtained numerous patches of subchondral bone regions of MR images, together with their trabecular parameters (BV / TV, Tb. Th, Tb. Sp, Tb. N) from the corresponding CT image patches via regression. The distillation-learning technique was used to train the regression model and transfer MR structural information to the CT-based model. The regressed trabecular parameters were further used for knee osteoarthritis classification. Results: A total of 80 participants were evaluated. CT-based regression results of trabecular parameters achieved intra-class correlation coefficients (ICCs) of 0.804, 0.773, 0.711, and 0.622 for BV / TV, Tb. Th, Tb. Sp, and Tb. N, respectively. The use of distillation learning significantly improved the performance of the CT-based knee osteoarthritis classification method using the CNN approach, yielding an AUC score of 0.767 (95% CI, 0.681-0.853) instead of 0.658 (95% CI, 0.574-0.742) (p<.001). Conclusions: The proposed SRRD method showed high reliability and validity in MR-CT registration, regression, and knee osteoarthritis classification, indicating the feasibility of subchondral bone microstructural analysis based on CT images.
Segmenting Medical MRI via Recurrent Decoding Cell
Nov 21, 2019
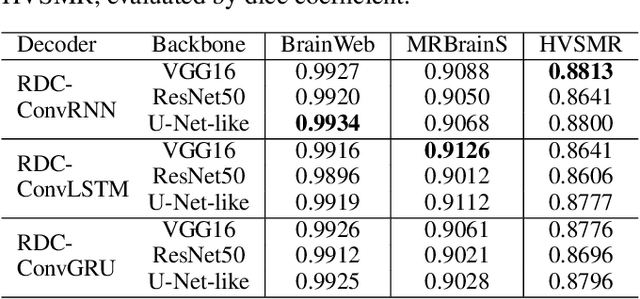
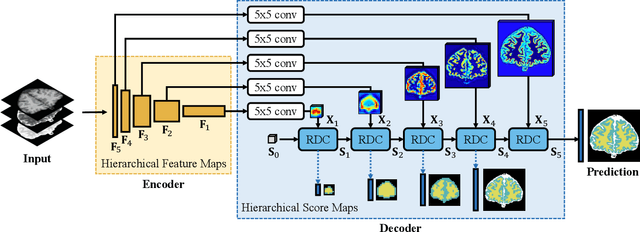

The encoder-decoder networks are commonly used in medical image segmentation due to their remarkable performance in hierarchical feature fusion. However, the expanding path for feature decoding and spatial recovery does not consider the long-term dependency when fusing feature maps from different layers, and the universal encoder-decoder network does not make full use of the multi-modality information to improve the network robustness especially for segmenting medical MRI. In this paper, we propose a novel feature fusion unit called Recurrent Decoding Cell (RDC) which leverages convolutional RNNs to memorize the long-term context information from the previous layers in the decoding phase. An encoder-decoder network, named Convolutional Recurrent Decoding Network (CRDN), is also proposed based on RDC for segmenting multi-modality medical MRI. CRDN adopts CNN backbone to encode image features and decode them hierarchically through a chain of RDCs to obtain the final high-resolution score map. The evaluation experiments on BrainWeb, MRBrainS and HVSMR datasets demonstrate that the introduction of RDC effectively improves the segmentation accuracy as well as reduces the model size, and the proposed CRDN owns its robustness to image noise and intensity non-uniformity in medical MRI.
In Defense of Single-column Networks for Crowd Counting
Aug 18, 2018



Crowd counting usually addressed by density estimation becomes an increasingly important topic in computer vision due to its widespread applications in video surveillance, urban planning, and intelligence gathering. However, it is essentially a challenging task because of the greatly varied sizes of objects, coupled with severe occlusions and vague appearance of extremely small individuals. Existing methods heavily rely on multi-column learning architectures to extract multi-scale features, which however suffer from heavy computational cost, especially undesired for crowd counting. In this paper, we propose the single-column counting network (SCNet) for efficient crowd counting without relying on multi-column networks. SCNet consists of residual fusion modules (RFMs) for multi-scale feature extraction, a pyramid pooling module (PPM) for information fusion, and a sub-pixel convolutional module (SPCM) followed by a bilinear upsampling layer for resolution recovery. Those proposed modules enable our SCNet to fully capture multi-scale features in a compact single-column architecture and estimate high-resolution density map in an efficient way. In addition, we provide a principled paradigm for density map generation and data augmentation for training, which shows further improved performance. Extensive experiments on three benchmark datasets show that our SCNet delivers new state-of-the-art performance and surpasses previous methods by large margins, which demonstrates the great effectiveness of SCNet as a single-column network for crowd counting.