 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTriLens: Per-Layer Logit-Lens Entropy for White-Box Hallucination Detection
May 31, 2026When a language model hallucinates, the final answer is wrong, but the mistake is not necessarily invisible inside the model. Different internal pathways may remain uncertain, disagree in how quickly they sharpen, or commit to competing continuations before the output is produced. We introduce TriLens, a white-box detector that turns this intuition into a compact representation: at every layer, it reads the multi-head self-attention output, the feed-forward output, and the residual stream through the model's own logit lens, then records only the entropy of each readout. The resulting 3L-dimensional trajectory describes how certainty forms across depth and across modules, without storing high-dimensional hidden states or sampling multiple generations. This simple signal yields a strong detector across instruction-tuned LLMs and QA benchmarks, and our analyses show that the three module-wise entropy trajectories provide complementary evidence. TriLens suggests that hallucination detection can benefit from tracking how internal computation settles, not only what the final layer predicts.
Soft Label Coding for End-to-end Sound Source Localization With Ad-hoc Microphone Arrays
Apr 15, 2023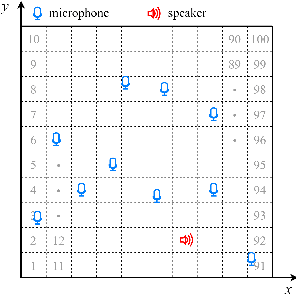



Recently, an end-to-end two-dimensional sound source localization algorithm with ad-hoc microphone arrays formulates the sound source localization problem as a classification problem. The algorithm divides the target indoor space into a set of local areas, and predicts the local area where the speaker locates. However, the local areas are encoded by one-hot code, which may lose the connections between the local areas due to quantization errors. In this paper, we propose a new soft label coding method, named label smoothing, for the classification-based two-dimensional sound source location with ad-hoc microphone arrays. The core idea is to take the geometric connection between the classes into the label coding process.The first one is named static soft label coding (SSLC), which modifies the one-hot codes into soft codes based on the distances between the local areas. Because SSLC is handcrafted which may not be optimal, the second one, named dynamic soft label coding (DSLC), further rectifies SSLC, by learning the soft codes according to the statistics of the predictions produced by the classification-based localization model in the training stage. Experimental results show that the proposed methods can effectively improve the localization accuracy.
Deep Learning Based Two-dimensional Speaker Localization With Large Ad-hoc Microphone Arrays
Oct 19, 2022
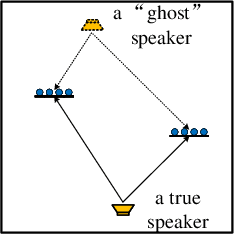
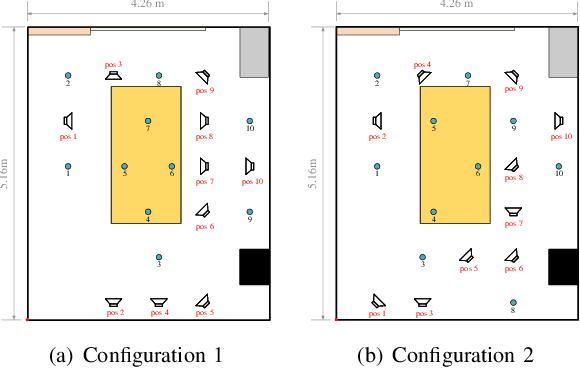
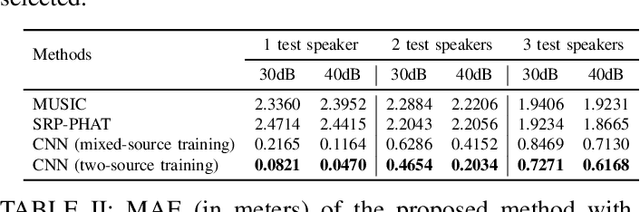
Deep learning based speaker localization has shown its advantage in reverberant scenarios. However, it mostly focuses on the direction-of-arrival (DOA) estimation subtask of speaker localization, where the DOA instead of the 2-dimensional (2D) coordinates is obtained only. To obtain the 2D coordinates of multiple speakers with random positions, this paper proposes a deep-learning-based 2D speaker localization method with large ad-hoc microphone arrays, where an ad-hoc microphone array is a set of randomly-distributed microphone nodes with each node set to a traditional microphone array, e.g. a linear array. Specifically, a convolutional neural network is applied to each node to get the direction-of-arrival (DOA) estimation of speech sources. Then, a triangulation and clustering method integrates the DOA estimations of the nodes for estimating the 2D positions of the speech sources. To further improve the estimation accuracy, we propose a softmax-based node selection algorithm. Experimental results with large-scale ad-hoc microphone arrays show that the proposed method achieves significantly better performance than conventional methods in both simulated and real-world environments. The softmax-based node selection further improves the performance.
End-to-end Two-dimensional Sound Source Localization With Ad-hoc Microphone Arrays
Oct 16, 2022Conventional sound source localization methods are mostly based on a single microphone array that consists of multiple microphones. They are usually formulated as the estimation of the direction of arrival problem. In this paper, we propose a deep-learning-based end-to-end sound source localization method with ad-hoc microphone arrays, where an ad-hoc microphone array is a set of randomly distributed microphone arrays that collaborate with each other. It can produce two-dimensional locations of speakers with only a single microphone per node. Specifically, we divide a targeted indoor space into multiple local areas. We encode each local area by a one-hot code, therefore, the node and speaker locations can be represented by the one-hot codes. Accordingly, the sound source localization problem is formulated as such a classification task of recognizing the one-hot code of the speaker given the one hot codes of the microphone nodes and their speech recordings. An end-to-end spatial-temporal deep model is designed for the classification problem. It utilizes a spatial-temporal attention architecture with a fusion layer inserted in the middle of the architecture, which is able to handle arbitrarily different numbers of microphone nodes during the model training and test. Experimental results show that the proposed method yields good performance in highly reverberant and noisy environments.